
Ottieni il massimo da Apache Solr: un'esplorazione tecnica dell'indicizzazione della ricerca
Pubblicato: 2023-02-21Una funzione di ricerca migliora l'esperienza dell'utente di un sito Web consentendo all'utente di trovare ciò che sta cercando facilmente e rapidamente. Tanto più per siti web di grandi dimensioni, siti di e-commerce e siti con contenuti dinamici (siti di notizie, blog).
Apache Solr è una delle piattaforme di ricerca più popolari utilizzate da siti Web di tutte le dimensioni. È un motore di ricerca open source basato su Java che ti consente di cercare tra grandi quantità di dati, come articoli, prodotti, recensioni dei clienti e altro ancora. Dai uno sguardo più approfondito ad Apache Solr in questo articolo.
Dai un'occhiata a questo articolo per sapere come configurare Apache Solr in Drupal

Perché Apache Solr è così popolare?
Apache Solr è veloce e flessibile e consente la ricerca full-text, l'evidenziazione dei risultati (evidenzia il termine di ricerca corrispondente), la ricerca sfaccettata (una ricerca più raffinata), l'indicizzazione in tempo reale (consente l'indicizzazione immediata di nuovi contenuti), il clustering dinamico ( organizza i risultati della ricerca in gruppi), integrazione del database, funzionalità NoSQL (database non relazionale) e ricca gestione dei documenti (per indicizzare un'ampia varietà di formati di documenti come PDF, MS Office, Open Office).
Alcuni fatti utili su Apache Solr:
- Inizialmente è stato sviluppato da CNET networks, inc. come motore di ricerca per i loro siti web e articoli. Successivamente, è stato open source ed è diventato un progetto Apache di alto livello.
- Supporta più linguaggi di programmazione come PHP, Java, Python e Ruby. Fornisce inoltre API per questi linguaggi.
- Ha il supporto integrato per la ricerca geospaziale, che consente di cercare contenuti in base alla sua posizione. Particolarmente utile per siti come siti web immobiliari, siti web di viaggi, ecc.
- Supporta funzionalità di ricerca avanzate come il controllo ortografico, il completamento automatico e la ricerca personalizzata tramite API e plug-in.
- Utilizza Lucene per l'indicizzazione e la ricerca.
Cos'è Lucene
Apache Lucene è una libreria di ricerca Java open source che consente di aggiungere facilmente la ricerca o il recupero di informazioni all'applicazione. È versatile, potente, preciso e funziona su un efficiente algoritmo di ricerca.
Sebbene noto per le sue capacità di ricerca full-text, Lucene può essere utilizzato anche per la classificazione dei documenti, l'analisi dei dati e il recupero delle informazioni. Supporta anche molte lingue diverse dall'inglese come tedesco, francese, spagnolo, cinese, giapponese e altro.
Cos'è l'indicizzazione?
Tutti i motori di ricerca iniziano con l'indicizzazione. L'indicizzazione è l'elaborazione dei dati originali in una ricerca di riferimenti incrociati altamente efficiente per facilitare la ricerca rapida.
I motori di ricerca non indicizzano i dati direttamente. I testi vengono prima suddivisi in token (elementi atomici). La ricerca è il processo di consultazione dell'indice di ricerca e recupero del documento corrispondente alla query.
Vantaggi dell'indicizzazione
- Recupero rapido e accurato delle informazioni (raccoglie, analizza e memorizza)
- Senza indicizzazione, il motore di ricerca richiede più tempo per scansionare ogni documento
Flusso di indicizzazione
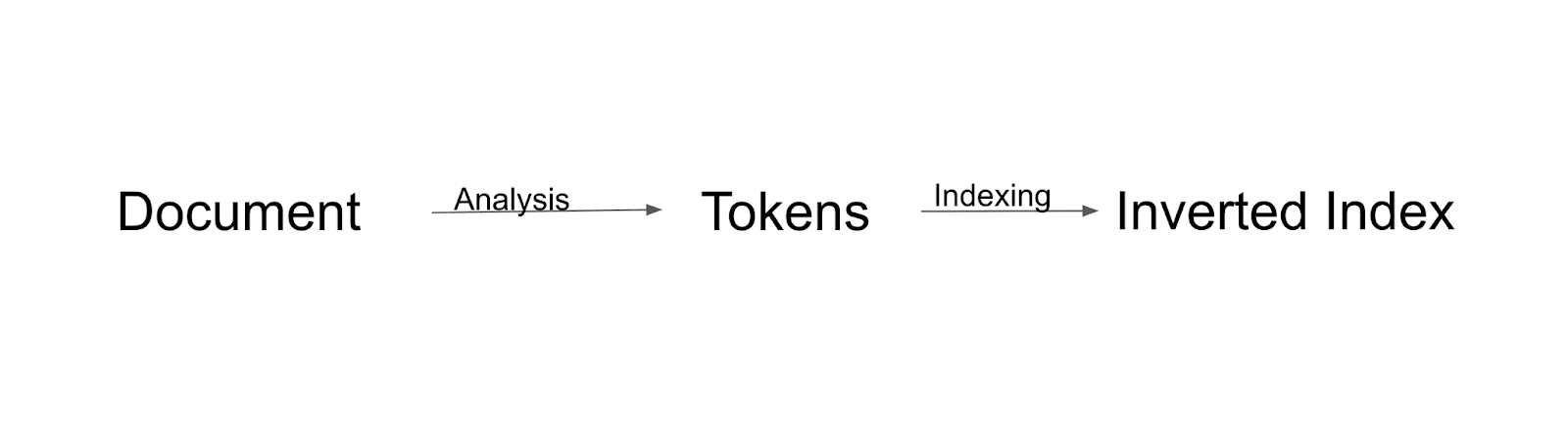
Innanzitutto, il documento verrà analizzato e suddiviso in token. Tutti questi token verranno indicizzati all'indice invertito. L'indice invertito è un modo in cui Solr costruisce l'indice.
Come funziona l'indicizzazione invertita
Consideriamo di avere 3 documenti:
- Amo il cioccolato (D 1)
- Ho ordinato una torta al cioccolato (D 2)
- Ho preparato una torta grande alla vaniglia (D 3)
Il modo in cui viene tokenizzato è come mostrato nella seconda colonna della tabella sottostante.

"Chocolate" è disponibile in D1 e D2
"Cake" è disponibile in D2 e D3
"Big" è disponibile in D3
"Ordinato" è disponibile in D2
"Preparato" è disponibile in D3
"Vanilla" è disponibile in D3
Noterai che parole come "io", "amore" non sono simbolizzate. Queste sono chiamate parole di arresto che non saranno indicizzate o ricercabili da Solr.
Quindi, quando qualcuno cerca il termine "torta al cioccolato", il motore cerca nell'indice. Invece di cercare il documento, esamina prima l'indice per vedere in quali documenti rientrano le parole "Cioccolato" e "Torta". Ciò rende facile e veloce recuperare solo il documento specifico. Questo si chiama indicizzazione invertita.
Schema di archiviazione
Apache Solr utilizza uno schema di archiviazione basato su documenti e archivia ogni dato come documento separato all'interno di una raccolta. Ciò consente un'archiviazione e un recupero dei dati efficienti e flessibili.
In Drupal, ogni nodo è considerato come un documento. Quindi, quando indicizzi il tuo nodo su Apache Solr, viene considerato come un documento. Ogni documento può contenere più campi. Lucene non ha uno schema globale comune. Ciò significa che puoi indicizzare qualsiasi tipo di campo in ogni documento in Apache Solr.

Come installare Apache Sol
- Innanzitutto, assicurati di avere Java installato sul tuo sistema.
- Successivamente, installiamo Solr da qui: https://solr.apache.org/downloads.html
- Scarica ed estrai Solr.
- Esegui questo comando nella cartella Solr.
◦ bin/solr -e prodotti tecnologici
Questo creerà un nucleo fittizio per la dimostrazione e avvierà anche il server Solr.
- Una volta avviato il server, vai sul tuo browser e digita "http://localhost:8983/".
- Assicurati che Solr sia installato correttamente con il core fittizio.
Struttura della directory
Una volta installato Solr, vedrai molte cartelle come:

Docs - contiene la documentazione su Solr
Dist - Solr file .jar principale
Contrib : contiene plug-in aggiuntivi e funzionalità specializzate di Solr
Bin - script di Solr
Esempio : contiene funzionalità di solr dimostrative
Server - cuore di Solr. Contiene l'applicazione Web Solr, i log, il core Solr
File di configurazione
Per creare un core, abbiamo bisogno di due file obbligatori.
- Schema.xml
- Solrconfig.xml
Schema.xml
- Conterrà i tipi di campi che intendi supportare e il modo in cui tali tipi dovrebbero essere analizzati.
Solrconfig.xml
- Contiene varie impostazioni che controllano il comportamento di un core Solr come gestore di richieste, dispatcher di richieste, componenti di query, gestori di aggiornamenti, ecc.
Interrogazione in Solr
Ora vediamo come interrogare i risultati di Solr nell'interfaccia utente di amministrazione di Solr.
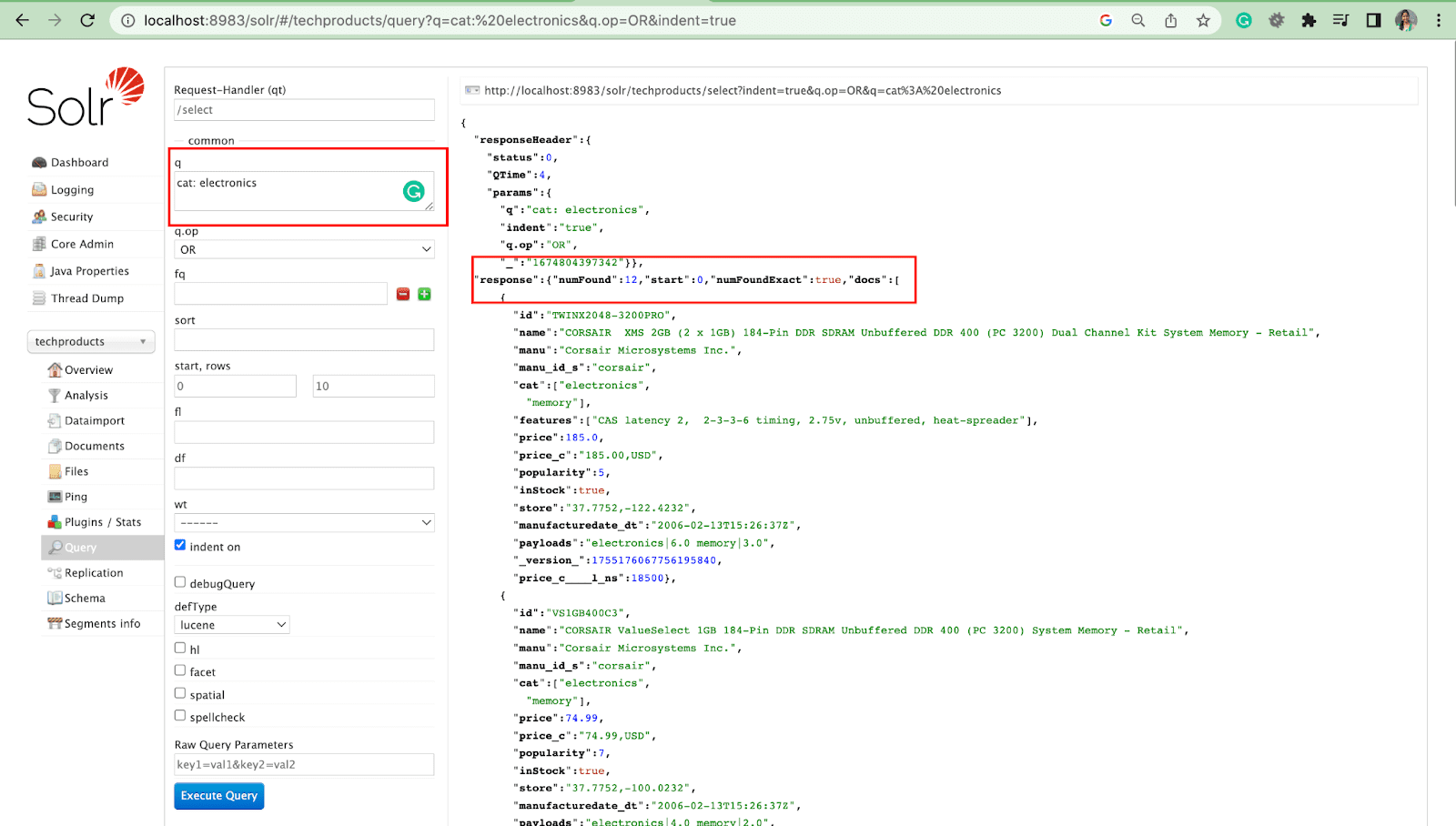
Parametro di ricerca
- I parametri locali sono argomenti in una richiesta Solr che sono specifici di un parametro di query.
Ad esempio: gatto: elettronica
Parametro di query con operazioni
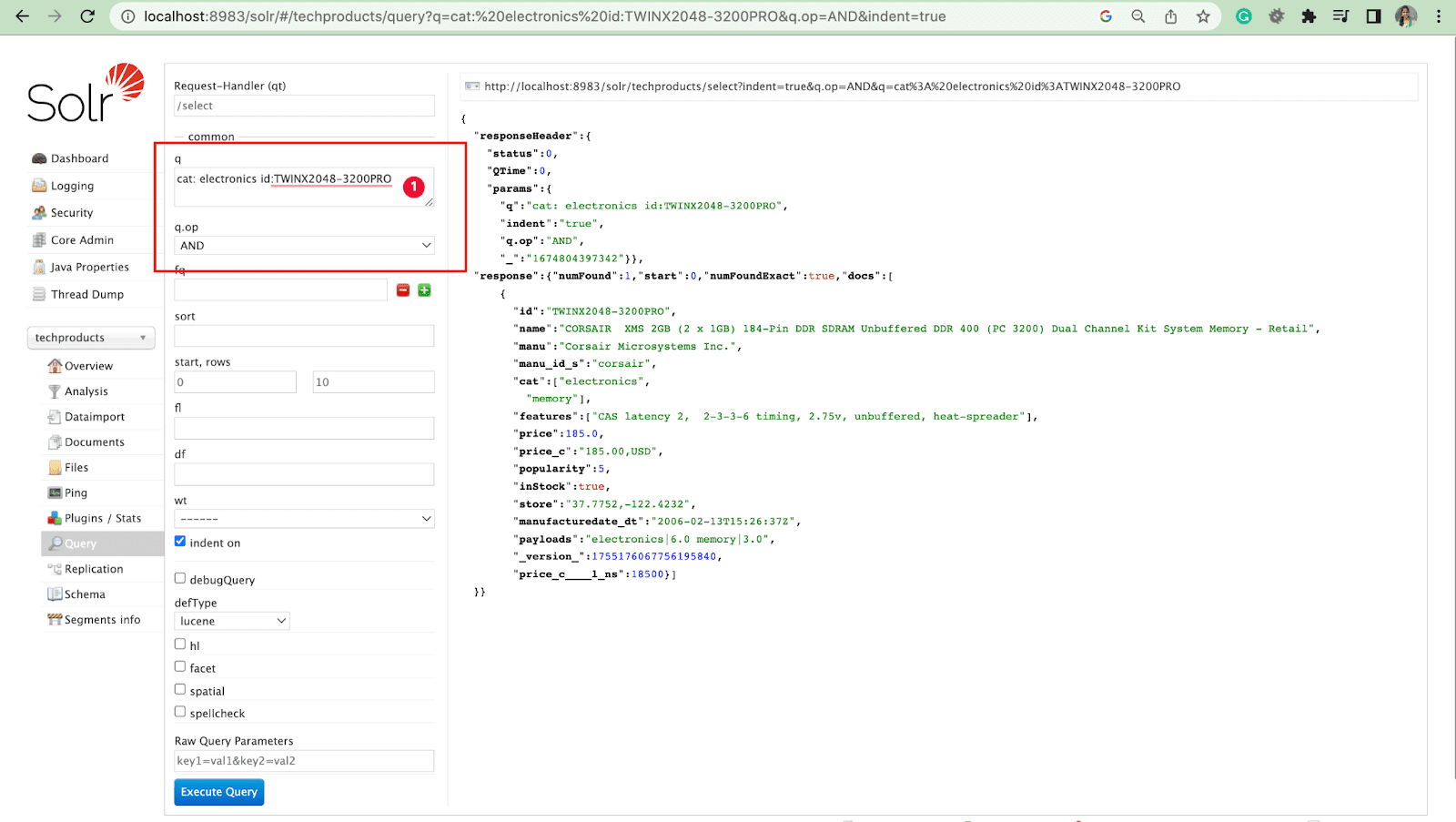
- Possiamo interrogare più campi con operazione.
Ad esempio: cat: electronic id:TWINX2048-3200PRO con q.op AND
[O]
cat: elettronica E id:TWINX2048-3200PRO
[O]
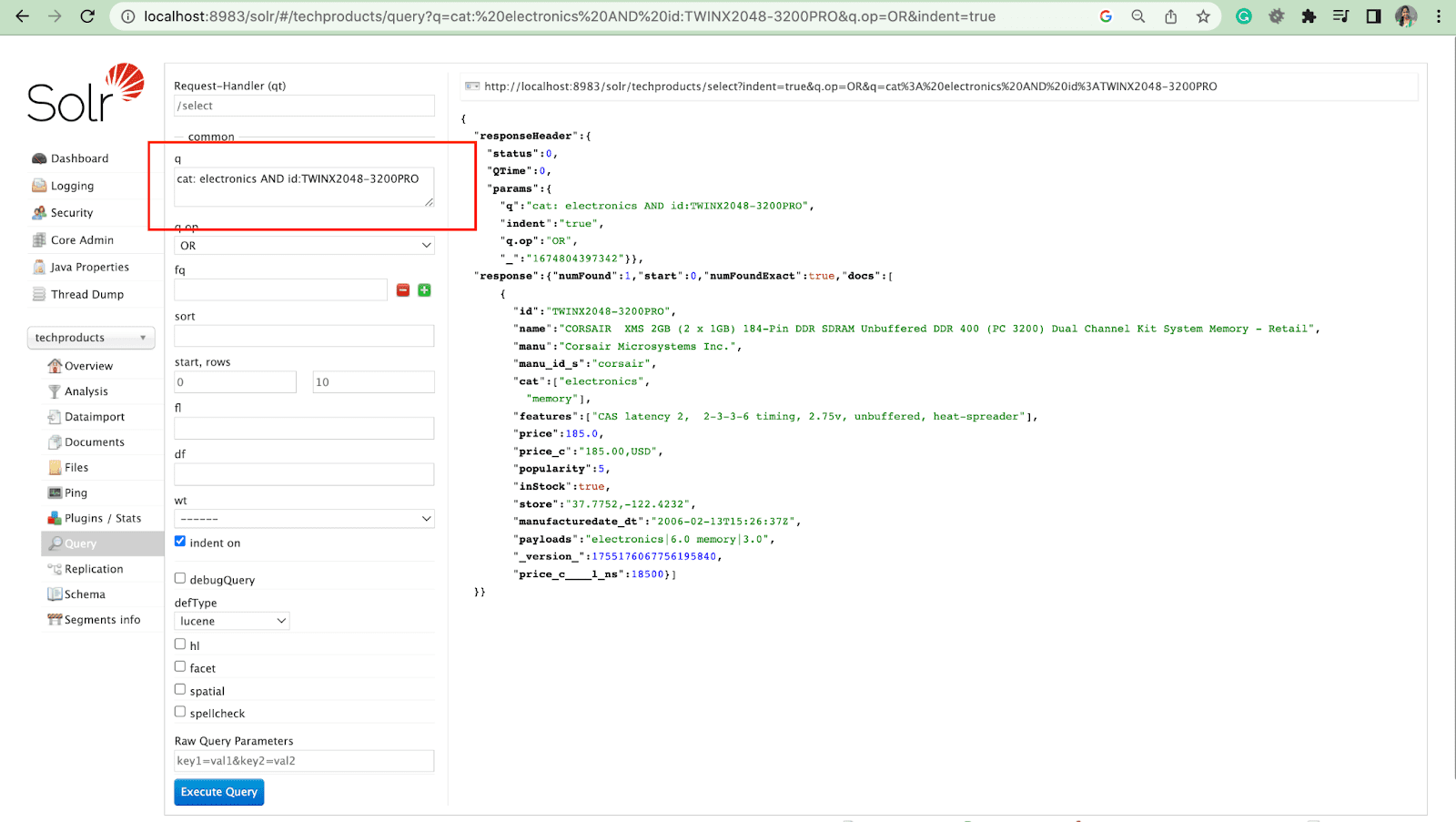
Filtro query
Una query filtro aiuta a restringere i risultati di una ricerca. Una query può essere specificata dal parametro fq per limitare i documenti restituiti nel superset, senza influire sul punteggio.
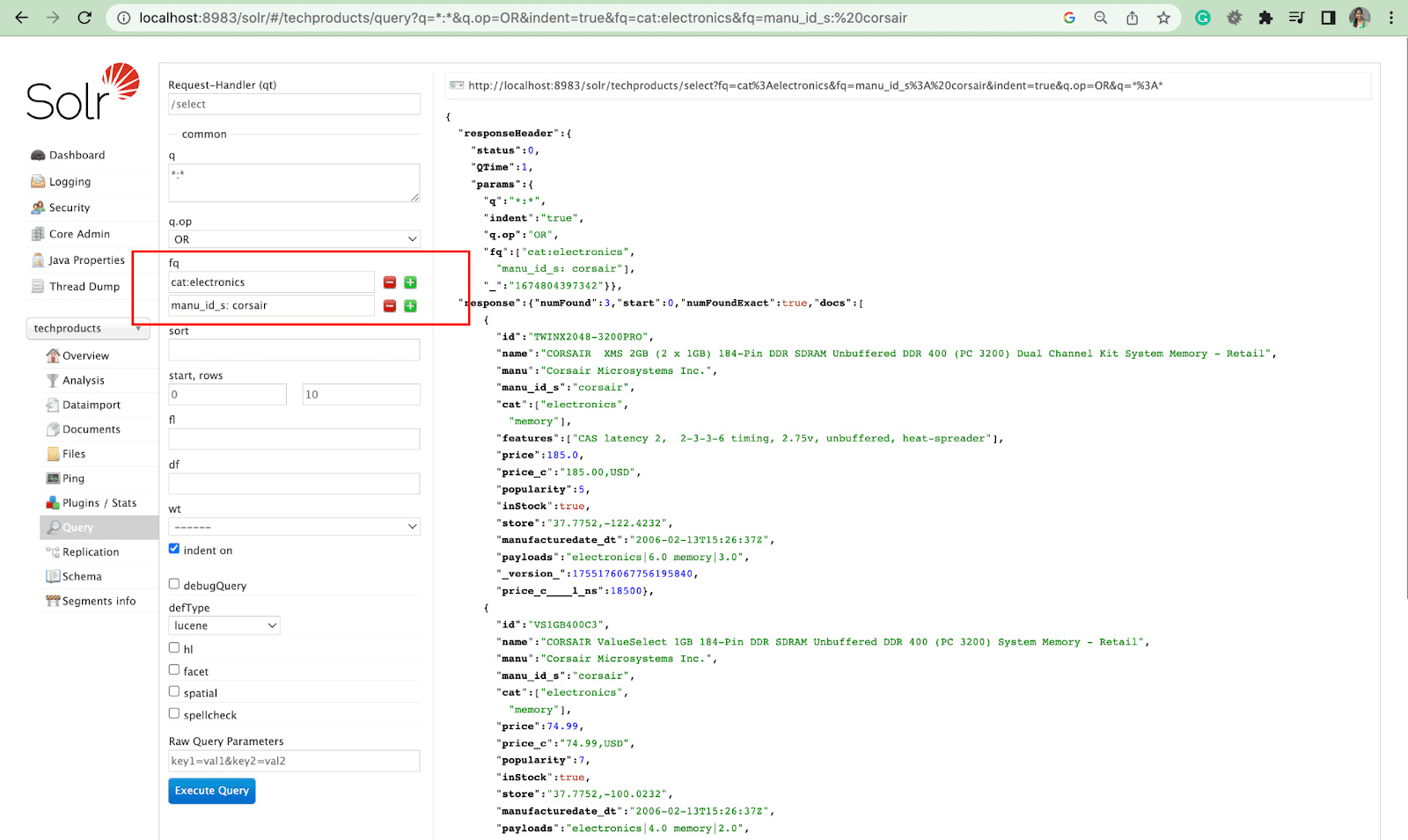
Ordina parametro
Il parametro sort dispone i risultati della ricerca in ordine crescente (asc) o decrescente (desc). A seconda del contenuto, il parametro può essere utilizzato in ordine numerico o alfabetico.
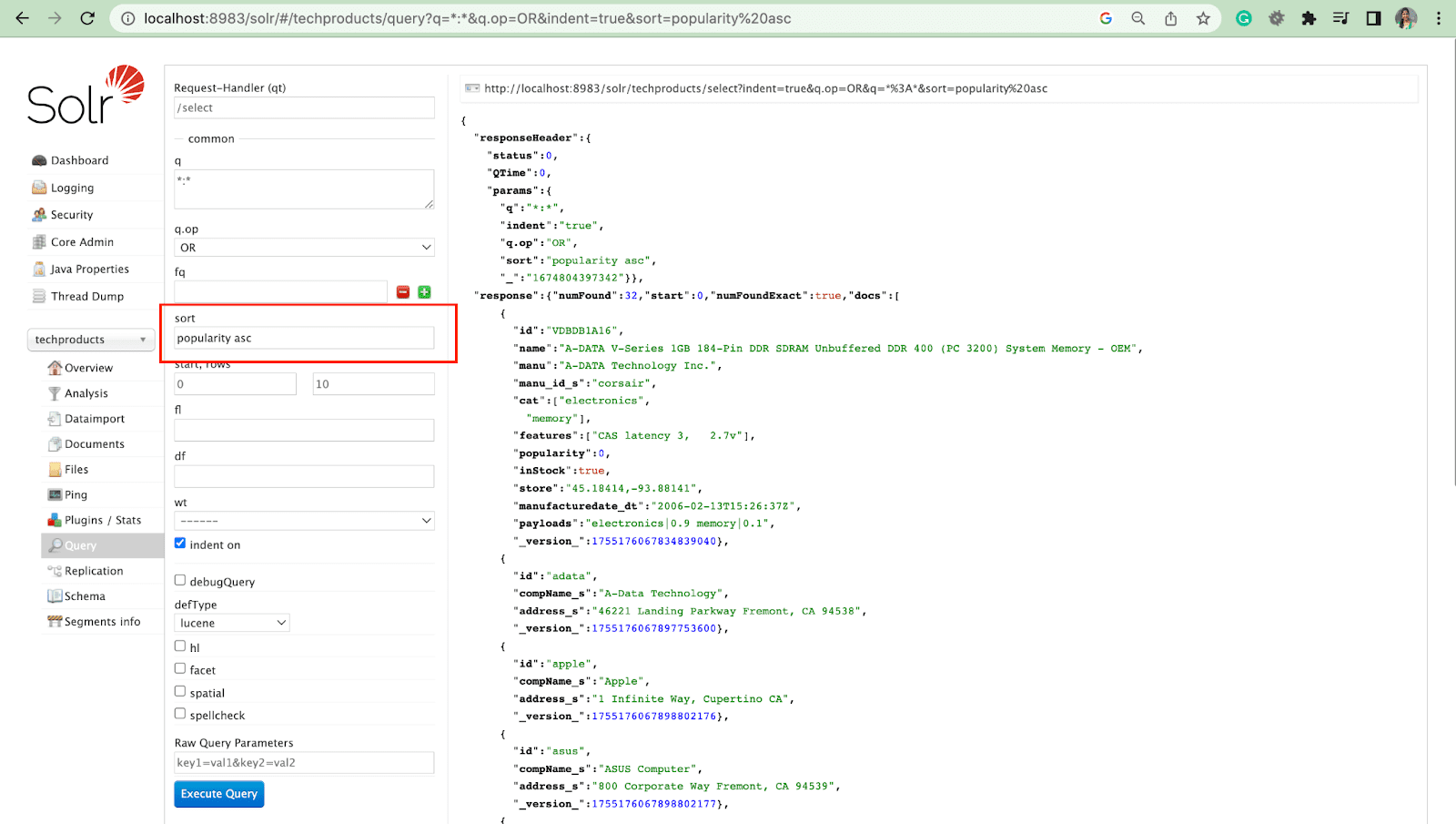
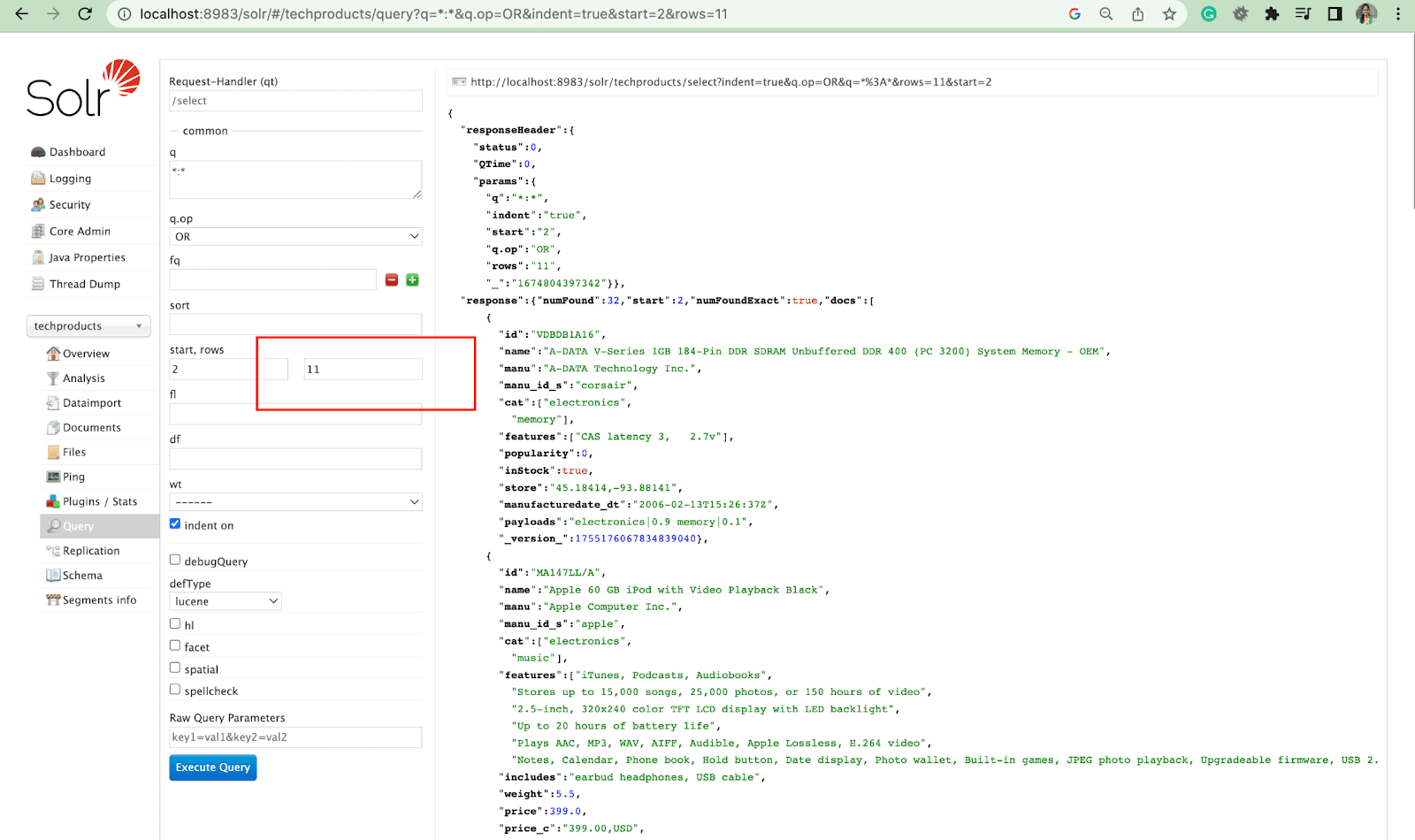
Parametro righe
Il parametro rows consente di impaginare i risultati di una query.
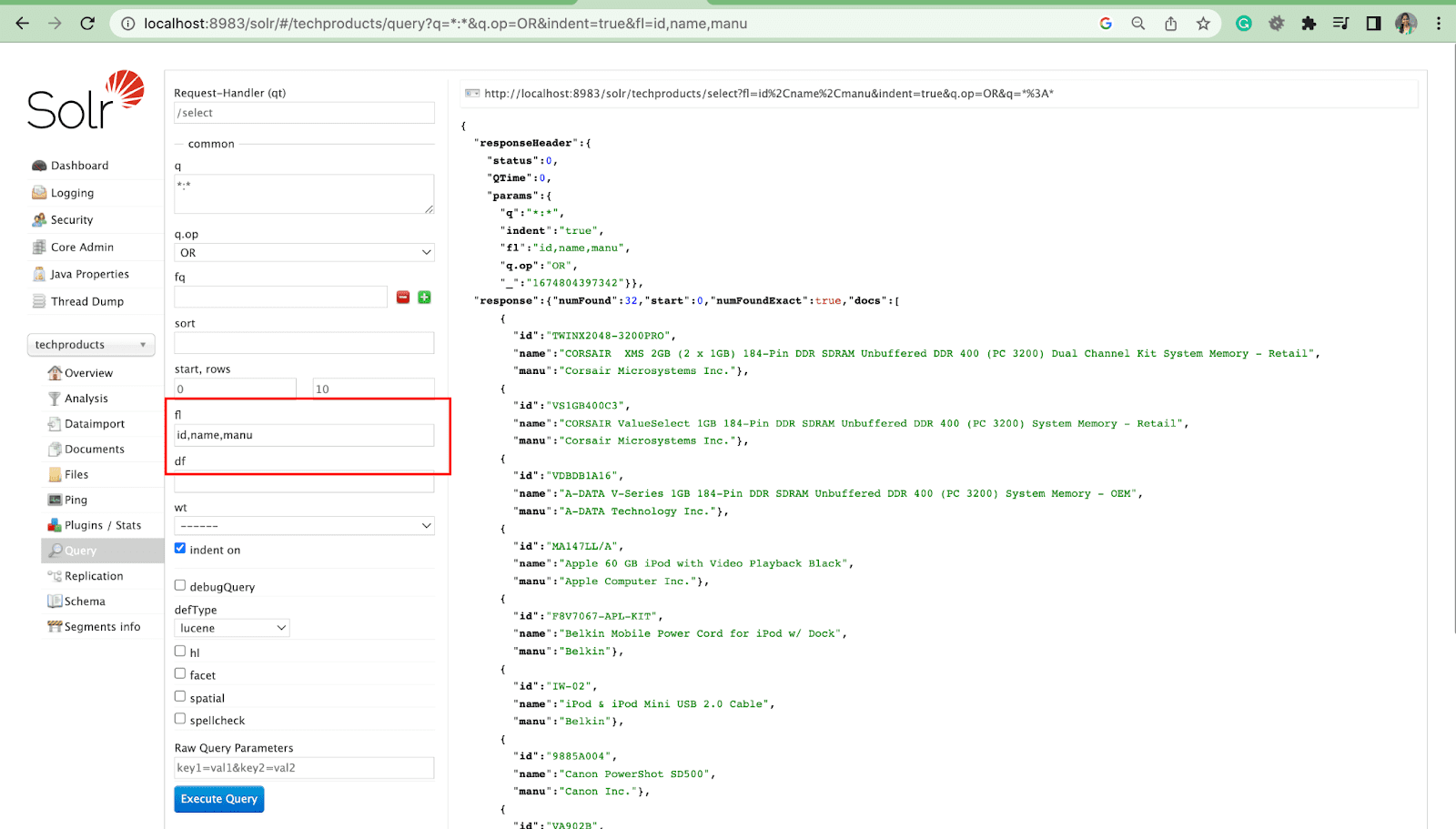
Parametro elenco campi
Il parametro fl limita le informazioni incluse in una risposta a una query a un elenco di campi specificato.
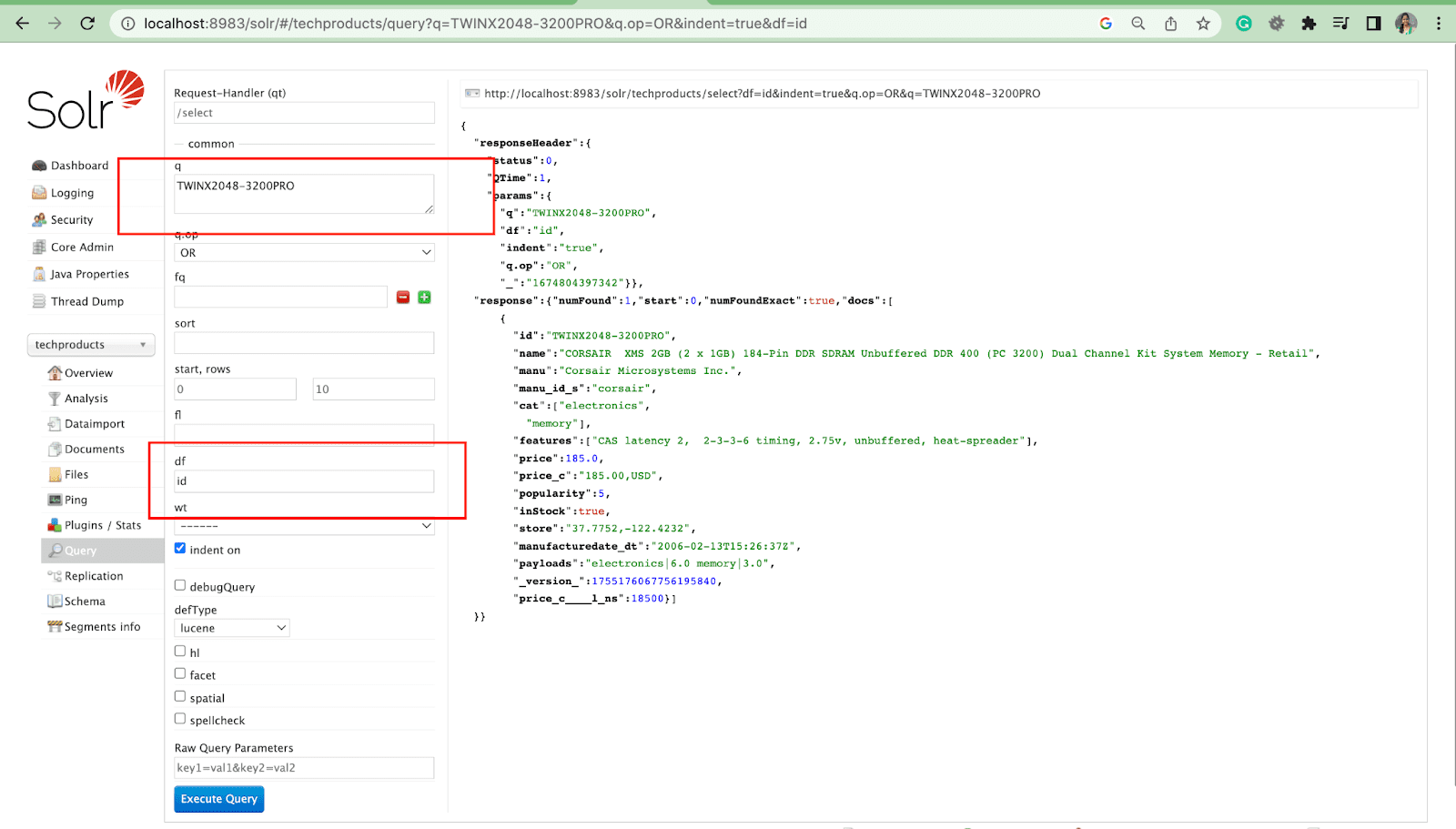
Campo predefinito Parametro
Il parametro di campo predefinito è il campo predefinito per il parametro di query.
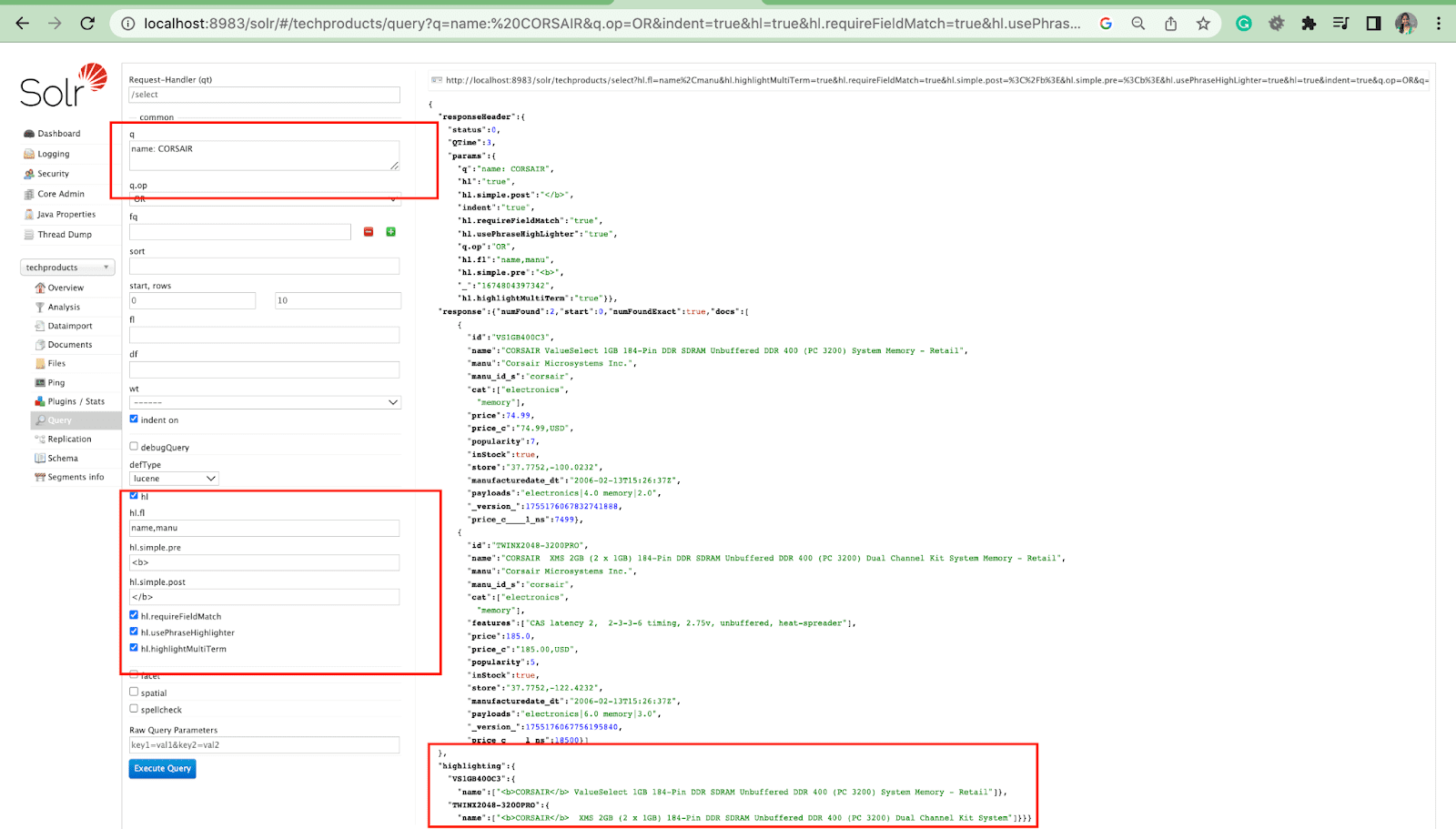
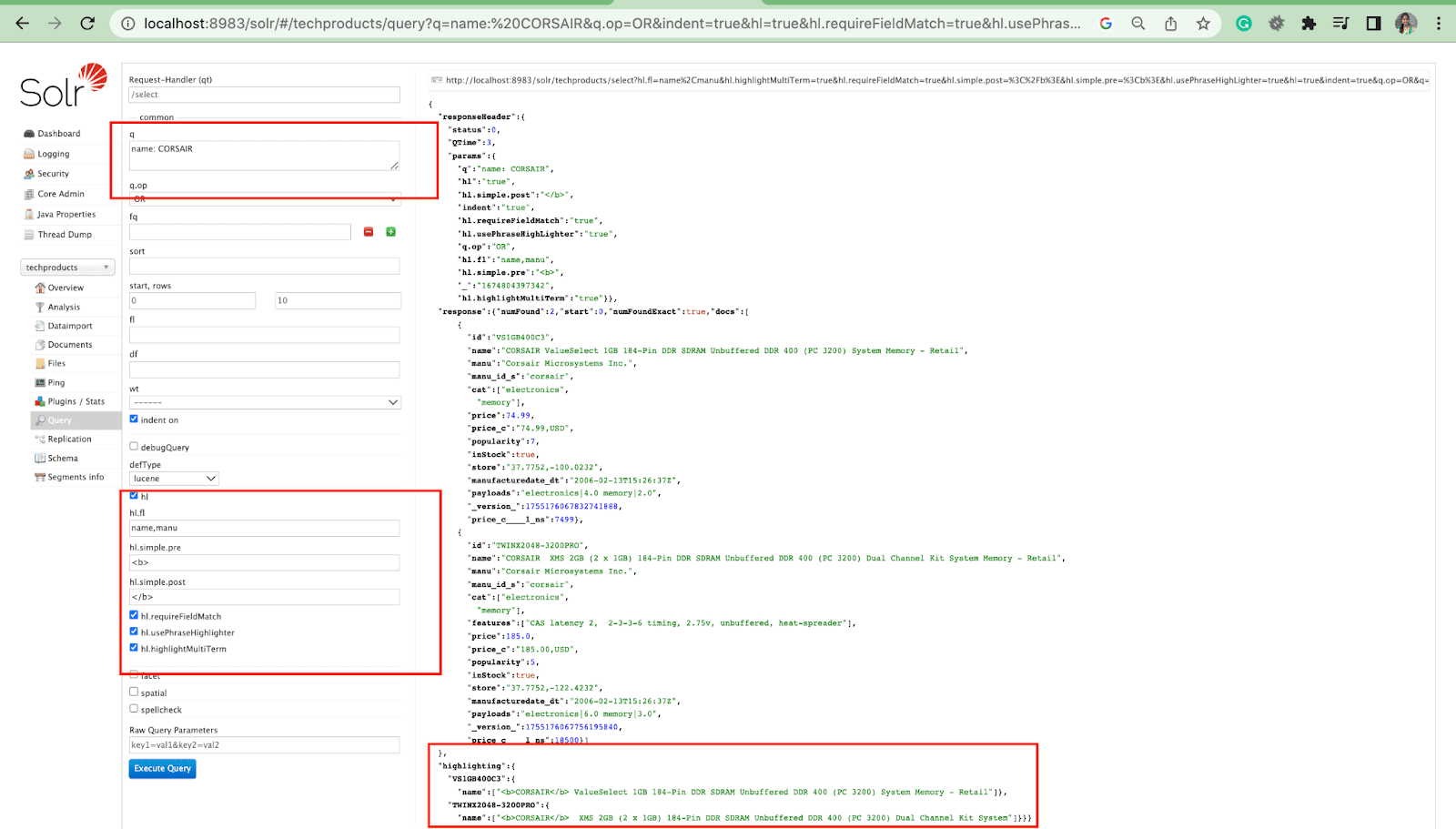
In evidenza Parametro
La funzione di evidenziazione in Solr consente l'inclusione di frammenti di documenti che corrispondono a una query.
Alcuni dei parametri di evidenziazione più comuni sono:
- Hl.fl - Evidenzia un elenco di campi.
- Hl.simple.pre - Specifica quale "tag" deve essere utilizzato prima di una parola evidenziata.
- Hl.simple.post - Specifica quale "tag" deve essere utilizzato dopo un termine evidenziato.
- hl.highlightMultiTerm - Se è impostato su true , Solr evidenzierà le query con caratteri jolly. Se false , non verranno affatto evidenziate.
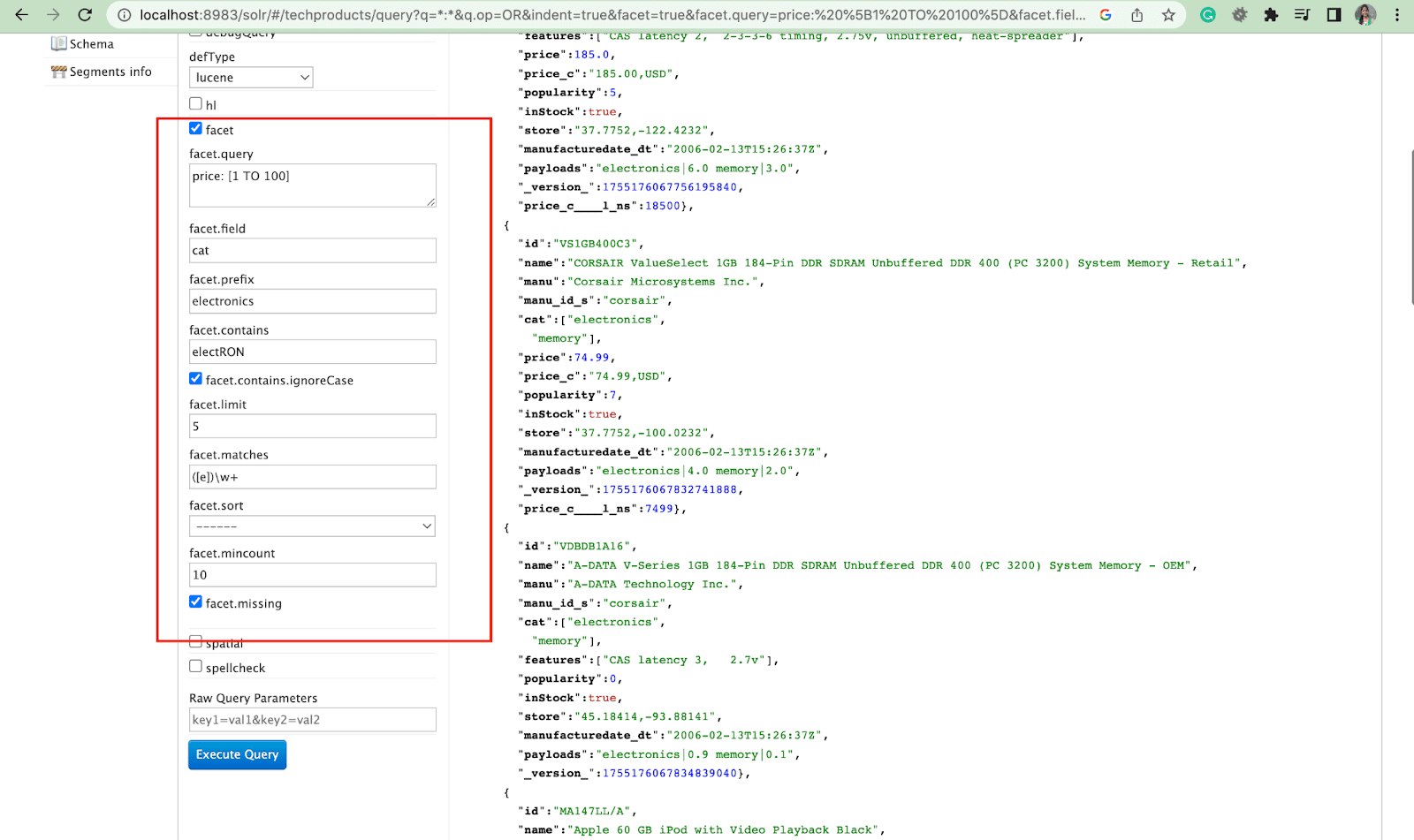
Sfaccettatura:
I facet consentono agli utenti di esplorare e perfezionare grandi insiemi di risultati di ricerca. Vengono visualizzati in un'interfaccia utente come caselle di controllo, elenchi a discesa o altri controlli. I due parametri generali per controllare i facet sono:
- Parametro di sfaccettatura
Utilizzando il parametro facet, gli utenti possono generare facet in base ai valori di uno o più campi nel proprio indice di ricerca. Nei risultati della ricerca, il parametro facet può essere configurato per controllare la modalità di generazione e visualizzazione dei facet.
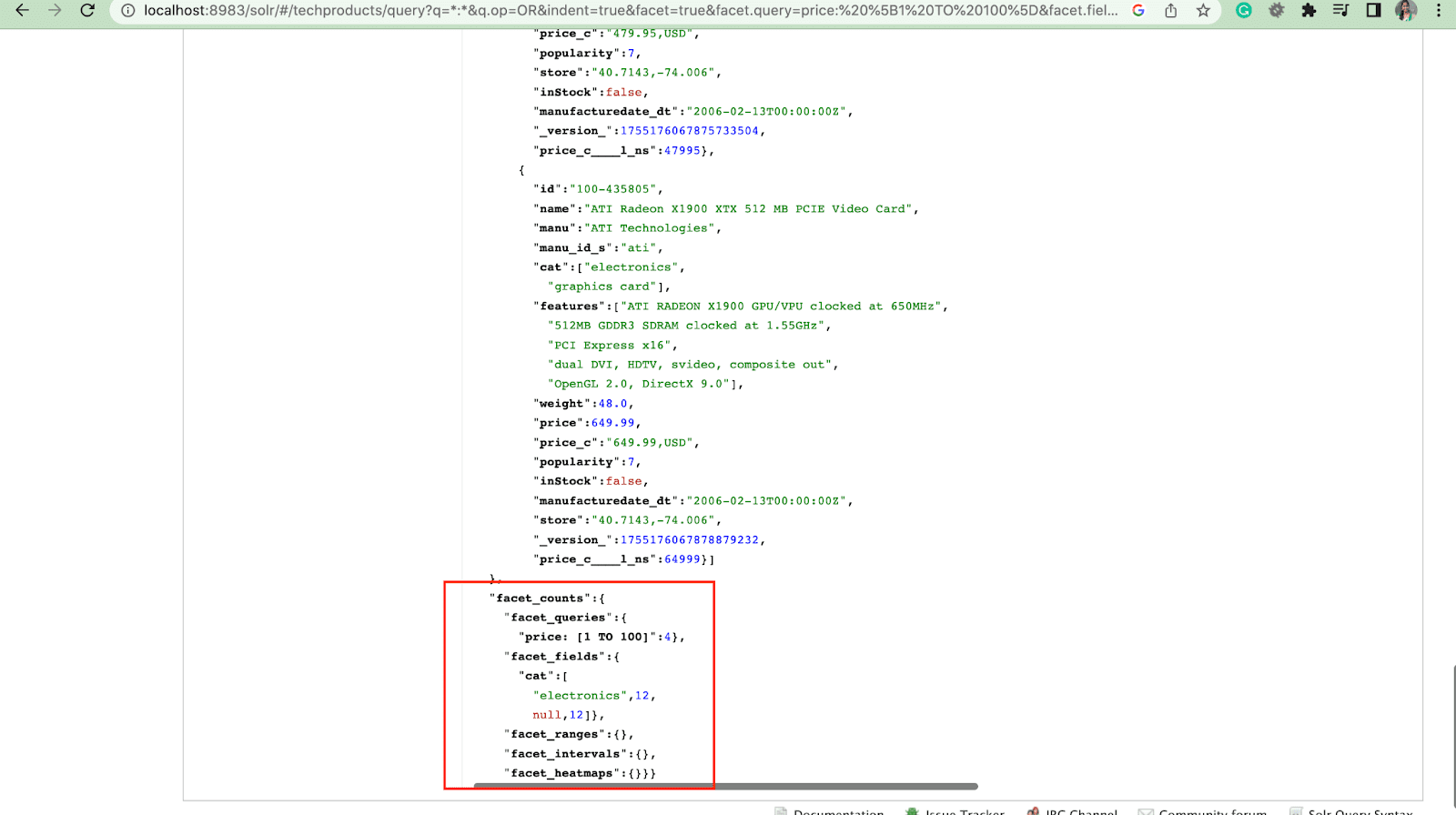
2. Parametro Facet.query
Quando un utente include un parametro facet.query nella query Solr, Solr genererà un elenco di conteggi di facet che corrispondono al numero di documenti nell'indice che corrispondono a ciascuna query. Facet.query è utile quando si desidera generare facet basati su criteri di ricerca complessi che non possono essere facilmente rappresentati utilizzando un semplice valore di campo.
Ci sono molti altri parametri facet come facet.field (per specificare i campi che dovrebbero essere usati per generare facet) , facet.limit (numero massimo di facet da visualizzare per ogni campo) , facet.mincount (numero minimo di documenti necessari per il facet da includere nella risposta) , facet.sort (specifica l'ordine in cui devono essere visualizzati i valori del facet) .
Pensieri finali
Apache Solr è un motore di ricerca altamente versatile dotato di molte caratteristiche interessanti che possono essere personalizzate secondo le tue esigenze. Drupal funziona molto bene con Apache Solr. Se stai cercando esperti Drupal per configurare un potente motore di ricerca per il tuo nuovo progetto, ci piacerebbe andare oltre!