
Rilevamento delle anomalie: guida per prevenire le intrusioni nella rete
Pubblicato: 2023-01-09I dati sono una parte indispensabile delle aziende e delle organizzazioni e sono preziosi solo se strutturati correttamente e gestiti in modo efficiente.
Secondo una statistica, oggi il 95% delle aziende trova un problema gestire e strutturare dati non strutturati.
È qui che entra in gioco il data mining. È il processo di scoperta, analisi ed estrazione di modelli significativi e informazioni preziose da grandi insiemi di dati non strutturati.
Le aziende utilizzano il software per identificare i modelli in grandi lotti di dati per saperne di più sui propri clienti e sul pubblico di destinazione e sviluppare strategie commerciali e di marketing per migliorare le vendite e ridurre i costi.
Oltre a questo vantaggio, il rilevamento di frodi e anomalie sono le applicazioni più importanti del data mining.
Questo articolo spiega il rilevamento delle anomalie ed esplora ulteriormente come può aiutare a prevenire violazioni dei dati e intrusioni di rete per garantire la sicurezza dei dati.
Che cos'è il rilevamento delle anomalie e i relativi tipi?

Sebbene il data mining implichi la ricerca di modelli, correlazioni e tendenze che si collegano tra loro, è un ottimo modo per trovare anomalie o punti dati anomali all'interno della rete.
Le anomalie nel data mining sono punti dati che differiscono da altri punti dati nel set di dati e si discostano dal modello di comportamento normale del set di dati.
Le anomalie possono essere classificate in tipi e categorie distinti, tra cui:
- Cambiamenti negli eventi: si riferiscono a cambiamenti improvvisi o sistematici rispetto al comportamento normale precedente.
- Valori anomali: piccoli schemi anomali che compaiono in modo non sistematico nella raccolta dei dati. Questi possono essere ulteriormente classificati in valori anomali globali, contestuali e collettivi.
- Derive: cambiamento graduale, unidirezionale ea lungo termine nel set di dati.
Pertanto, il rilevamento delle anomalie è una tecnica di elaborazione dei dati molto utile per rilevare transazioni fraudolente, gestire casi di studio con squilibri di alta classe e rilevare malattie per costruire solidi modelli di data science.
Ad esempio, un'azienda potrebbe voler analizzare il proprio flusso di cassa per trovare transazioni anomale o ricorrenti su un conto bancario sconosciuto per rilevare frodi e condurre ulteriori indagini.
Vantaggi del rilevamento delle anomalie
Il rilevamento delle anomalie del comportamento degli utenti aiuta a rafforzare i sistemi di sicurezza e li rende più precisi e accurati.
Analizza e dà un senso alle varie informazioni fornite dai sistemi di sicurezza per identificare minacce e potenziali rischi all'interno della rete.
Ecco i vantaggi del rilevamento delle anomalie per le aziende:
- Rilevamento in tempo reale delle minacce alla sicurezza informatica e delle violazioni dei dati mentre i suoi algoritmi di intelligenza artificiale (AI) scansionano costantemente i tuoi dati per trovare comportamenti insoliti.
- Rende il tracciamento di attività e schemi anomali più rapido e semplice rispetto al rilevamento manuale delle anomalie, riducendo la manodopera e il tempo necessari per risolvere le minacce.
- Riduce al minimo i rischi operativi identificando gli errori operativi, come improvvisi cali di prestazioni, prima ancora che si verifichino.
- Aiuta a eliminare i principali danni aziendali rilevando rapidamente le anomalie, poiché senza un sistema di rilevamento delle anomalie, le aziende possono impiegare settimane e mesi per identificare potenziali minacce.
Pertanto, il rilevamento delle anomalie è una risorsa enorme per le aziende che archiviano ampi set di dati aziendali e dei clienti per trovare opportunità di crescita ed eliminare le minacce alla sicurezza e i colli di bottiglia operativi.
Tecniche di rilevamento delle anomalie
Il rilevamento delle anomalie utilizza diverse procedure e algoritmi di machine learning (ML) per monitorare i dati e rilevare le minacce.
Ecco le principali tecniche di rilevamento delle anomalie:
#1. Tecniche di apprendimento automatico

Le tecniche di Machine Learning utilizzano algoritmi ML per analizzare i dati e rilevare le anomalie. I diversi tipi di algoritmi di Machine Learning per il rilevamento delle anomalie includono:
- Algoritmi di clustering
- Algoritmi di classificazione
- Algoritmi di apprendimento profondo
E le tecniche ML comunemente utilizzate per il rilevamento di anomalie e minacce includono macchine a vettori di supporto (SVM), clustering k-mean e codificatori automatici.
#2. Tecniche statistiche
Le tecniche statistiche utilizzano modelli statistici per rilevare modelli insoliti (come fluttuazioni insolite nelle prestazioni di una particolare macchina) nei dati per rilevare valori che superano l'intervallo dei valori previsti.
Le comuni tecniche di rilevamento delle anomalie statistiche includono test di ipotesi, IQR, Z-score, Z-score modificato, stima della densità, boxplot, analisi dei valori estremi e istogramma.
#3. Tecniche di data mining

Le tecniche di data mining utilizzano tecniche di classificazione e clustering dei dati per trovare anomalie all'interno del set di dati. Alcune tecniche di anomalia di data mining comuni includono il clustering spettrale, il clustering basato sulla densità e l'analisi dei componenti principali.
Gli algoritmi di data mining di clustering vengono utilizzati per raggruppare diversi punti dati in cluster in base alla loro somiglianza per trovare punti dati e anomalie che non rientrano in questi cluster.
D'altra parte, gli algoritmi di classificazione assegnano punti dati a specifiche classi predefinite e rilevano punti dati che non appartengono a queste classi.
#4. Tecniche basate su regole
Come suggerisce il nome, le tecniche di rilevamento delle anomalie basate su regole utilizzano una serie di regole predeterminate per trovare anomalie all'interno dei dati.
Queste tecniche sono relativamente più facili e semplici da configurare, ma possono essere poco flessibili e potrebbero non essere efficienti nell'adattarsi al cambiamento del comportamento e dei modelli dei dati.
Ad esempio, puoi facilmente programmare un sistema basato su regole per contrassegnare come fraudolente le transazioni che superano un determinato importo in dollari.
#5. Tecniche specifiche del dominio
È possibile utilizzare tecniche specifiche del dominio per rilevare anomalie in sistemi di dati specifici. Tuttavia, mentre possono essere altamente efficienti nel rilevare anomalie in domini specifici, possono essere meno efficienti in altri domini al di fuori di quello specificato.
Ad esempio, utilizzando tecniche specifiche del dominio, è possibile progettare tecniche specifiche per rilevare anomalie nelle transazioni finanziarie. Ma potrebbero non funzionare per trovare anomalie o cali di prestazioni in una macchina.
Necessità di Machine Learning per il rilevamento delle anomalie
L'apprendimento automatico è molto importante e molto utile nel rilevamento delle anomalie.
Oggi, la maggior parte delle aziende e delle organizzazioni che richiedono il rilevamento dei valori anomali gestisce enormi quantità di dati, da testo, informazioni sui clienti e transazioni a file multimediali come immagini e contenuti video.
Esaminare manualmente tutte le transazioni bancarie e i dati generati ogni secondo per ottenere informazioni significative è quasi impossibile. Inoltre, la maggior parte delle aziende affronta sfide e grandi difficoltà nella strutturazione dei dati non strutturati e nell'organizzazione dei dati in modo significativo per l'analisi dei dati.
È qui che strumenti e tecniche come l'apprendimento automatico (ML) svolgono un ruolo enorme nella raccolta, pulizia, strutturazione, organizzazione, analisi e archiviazione di enormi volumi di dati non strutturati.
Le tecniche e gli algoritmi di Machine Learning elaborano grandi set di dati e forniscono la flessibilità necessaria per utilizzare e combinare diverse tecniche e algoritmi per fornire i migliori risultati.
Inoltre, l'apprendimento automatico aiuta anche a semplificare i processi di rilevamento delle anomalie per le applicazioni del mondo reale e consente di risparmiare risorse preziose.
Ecco alcuni altri vantaggi e l'importanza dell'apprendimento automatico nel rilevamento delle anomalie:
- Semplifica il rilevamento delle anomalie di ridimensionamento automatizzando l'identificazione di modelli e anomalie senza richiedere una programmazione esplicita.
- Gli algoritmi di Machine Learning sono altamente adattabili al cambiamento dei modelli di set di dati, rendendoli altamente efficienti e robusti nel tempo.
- Gestisce facilmente set di dati grandi e complessi, rendendo efficiente il rilevamento delle anomalie nonostante la complessità del set di dati.
- Garantisce l'identificazione e il rilevamento tempestivi delle anomalie identificando le anomalie nel momento in cui si verificano, risparmiando tempo e risorse.
- I sistemi di rilevamento delle anomalie basati sull'apprendimento automatico aiutano a raggiungere livelli di accuratezza più elevati nel rilevamento delle anomalie rispetto ai metodi tradizionali.
Pertanto, il rilevamento delle anomalie abbinato all'apprendimento automatico consente un rilevamento più rapido e tempestivo delle anomalie per prevenire minacce alla sicurezza e violazioni dannose.

Algoritmi di Machine Learning per il rilevamento delle anomalie
È possibile rilevare anomalie e valori anomali nei dati con l'aiuto di diversi algoritmi di data mining per la classificazione, il clustering o l'apprendimento delle regole di associazione.
In genere, questi algoritmi di data mining sono classificati in due diverse categorie : algoritmi di apprendimento supervisionati e non supervisionati.
Apprendimento supervisionato
L'apprendimento supervisionato è un tipo comune di algoritmo di apprendimento costituito da algoritmi come macchine a vettori di supporto, regressione logistica e lineare e classificazione multiclasse. Questo tipo di algoritmo viene addestrato su dati etichettati, il che significa che il set di dati di addestramento include sia i normali dati di input che l'output corretto corrispondente o esempi anomali per costruire un modello predittivo.
Pertanto, il suo obiettivo è fare previsioni di output per dati non visti e nuovi in base ai modelli di set di dati di addestramento. Le applicazioni degli algoritmi di apprendimento supervisionato includono il riconoscimento di immagini e parole, la modellazione predittiva e l'elaborazione del linguaggio naturale (NLP).
Apprendimento non supervisionato
Apprendimento non supervisionato non è addestrato su dati etichettati. Invece, scopre processi complicati e strutture di dati sottostanti senza fornire la guida dell'algoritmo di addestramento e invece di fare previsioni specifiche.
Le applicazioni degli algoritmi di apprendimento senza supervisione includono il rilevamento delle anomalie, la stima della densità e la compressione dei dati.
Ora, esploriamo alcuni popolari algoritmi di rilevamento delle anomalie basati sull'apprendimento automatico.
Fattore anomalo locale (LOF)
Local Outlier Factor o LOF è un algoritmo di rilevamento delle anomalie che considera la densità dei dati locali per determinare se un punto dati è un'anomalia.
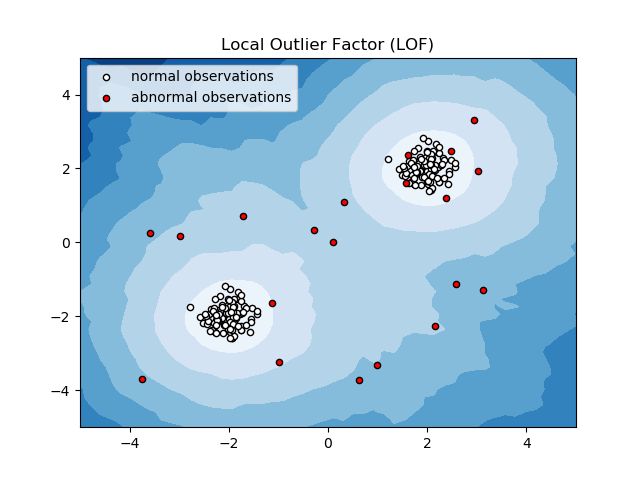
Confronta la densità locale di un oggetto con le densità locali dei suoi vicini per analizzare aree di densità simili e oggetti con densità relativamente inferiori rispetto ai loro vicini, che non sono altro che anomalie o valori anomali.
Pertanto, in termini semplici, la densità che circonda un elemento anomalo o anomalo differisce dalla densità attorno ai suoi vicini. Pertanto, questo algoritmo è anche chiamato algoritmo di rilevamento dei valori anomali basato sulla densità.
K-vicino più prossimo (K-NN)
K-NN è l'algoritmo di classificazione e rilevamento delle anomalie supervisionato più semplice che è facile da implementare, memorizza tutti gli esempi e i dati disponibili e classifica i nuovi esempi in base alle somiglianze nelle metriche di distanza.
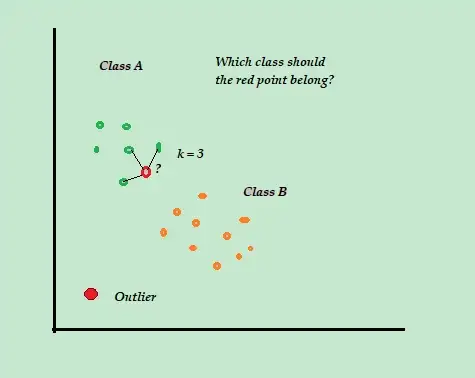
Questo algoritmo di classificazione è anche chiamato studente pigro perché memorizza solo i dati di addestramento etichettati, senza fare nient'altro durante il processo di addestramento.
Quando arriva il nuovo punto dati di addestramento senza etichetta, l'algoritmo esamina i punti dati di addestramento K-più vicini o più vicini per utilizzarli per classificare e determinare la classe del nuovo punto dati senza etichetta.
L'algoritmo K-NN utilizza i seguenti metodi di rilevamento per determinare i punti dati più vicini:
- Distanza euclidea per misurare la distanza per dati continui.
- Distanza di Hamming per misurare la prossimità o "vicinanza" delle due stringhe di testo per dati discreti.
Ad esempio, considera che i tuoi set di dati di addestramento sono costituiti da due etichette di classe, A e B. Se arriva un nuovo punto dati, l'algoritmo calcolerà la distanza tra il nuovo punto dati e ciascuno dei punti dati nel set di dati e selezionerà i punti che sono il numero massimo più vicino al nuovo punto dati.
Quindi, supponiamo che K=3 e 2 punti dati su 3 siano etichettati come A, quindi il nuovo punto dati viene etichettato come classe A.
Pertanto, l'algoritmo K-NN funziona al meglio in ambienti dinamici con frequenti requisiti di aggiornamento dei dati.
È un popolare algoritmo di rilevamento delle anomalie e di text mining con applicazioni nel settore finanziario e aziendale per rilevare transazioni fraudolente e aumentare il tasso di rilevamento delle frodi.
Macchina vettoriale di supporto (SVM)
Support vector machine è un algoritmo di rilevamento delle anomalie basato sull'apprendimento automatico supervisionato utilizzato principalmente nei problemi di regressione e classificazione.
Utilizza un iperpiano multidimensionale per separare i dati in due gruppi (nuovi e normali). Pertanto, l'iperpiano funge da confine decisionale che separa le normali osservazioni di dati e i nuovi dati.
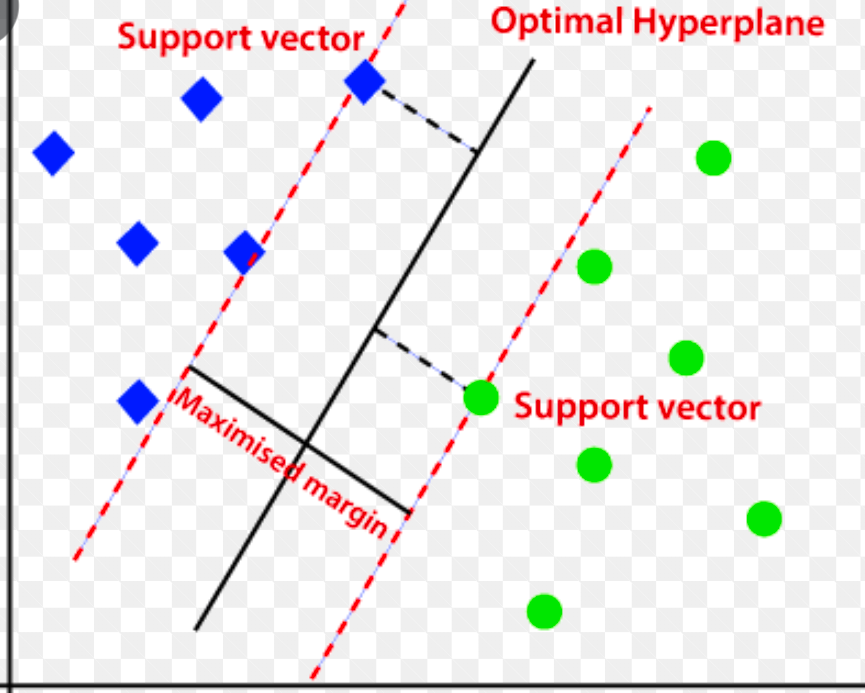
La distanza tra questi due punti dati è indicata come margini.
Poiché l'obiettivo è aumentare la distanza tra i due punti, SVM determina l' iperpiano migliore o ottimale con il margine massimo per garantire che la distanza tra le due classi sia la più ampia possibile.
Per quanto riguarda il rilevamento delle anomalie, SVM calcola il margine della nuova osservazione del punto dati dall'iperpiano per classificarlo.
Se il margine supera la soglia impostata, classifica la nuova osservazione come anomalia. Allo stesso tempo, se il margine è inferiore alla soglia, l'osservazione è classificata come normale.
Pertanto, gli algoritmi SVM sono altamente efficienti nella gestione di insiemi di dati ad alta dimensione e complessi.
Foresta di isolamento
Isolation Forest è un algoritmo di rilevamento delle anomalie di machine learning senza supervisione basato sul concetto di Random Forest Classifier.
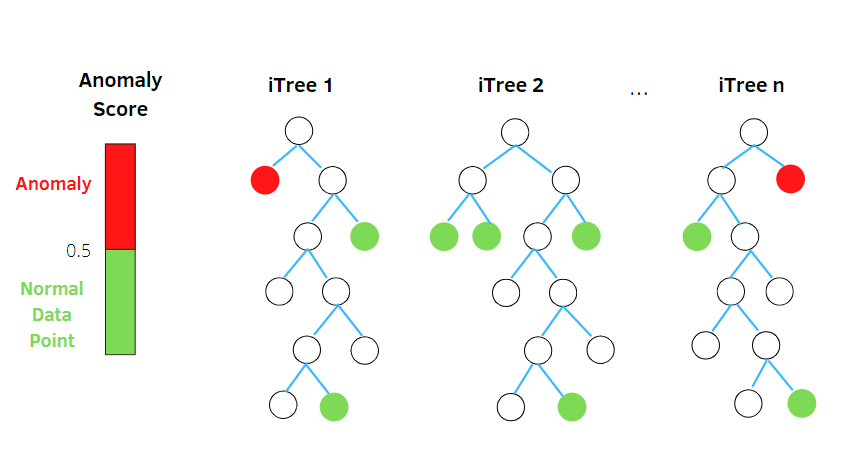
Questo algoritmo elabora i dati sottocampionati in modo casuale nel set di dati in una struttura ad albero basata su attributi casuali. Costruisce diversi alberi decisionali per isolare le osservazioni. E considera una particolare osservazione un'anomalia se è isolata in meno alberi in base al suo tasso di contaminazione.
Pertanto, in termini semplici, l'algoritmo della foresta di isolamento suddivide i punti dati in diversi alberi decisionali, assicurando che ogni osservazione venga isolata da un'altra.
Le anomalie in genere si trovano lontano dal cluster di punti dati, semplificando l'identificazione delle anomalie rispetto ai normali punti dati.
Gli algoritmi della foresta di isolamento possono gestire facilmente dati categorici e numerici. Di conseguenza, sono più veloci da addestrare e altamente efficienti nel rilevare anomalie di set di dati ad alta dimensione e di grandi dimensioni.
Intervallo interquartile
L'intervallo interquartile o IQR viene utilizzato per misurare la variabilità statistica o la dispersione statistica per trovare punti anomali nei set di dati dividendoli in quartili.
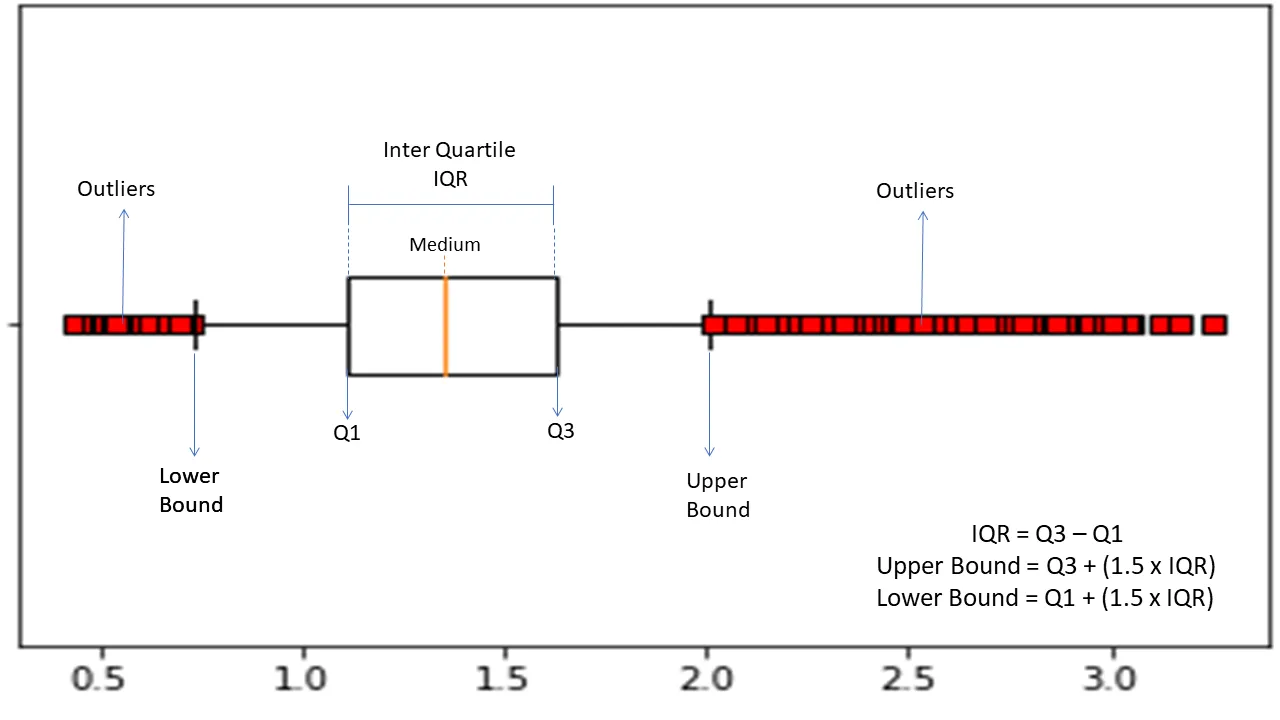
L'algoritmo ordina i dati in ordine crescente e divide l'insieme in quattro parti uguali. I valori che separano queste parti sono Q1, Q2 e Q3: primo, secondo e terzo quartile.
Ecco la distribuzione percentile di questi quartili:
- Q1 indica il 25° percentile dei dati.
- Q2 indica il 50° percentile dei dati.
- Q3 indica il 75° percentile dei dati.
IQR è la differenza tra il terzo (75°) e il primo (25°) set di dati percentile, che rappresenta il 50% dei dati.
L'utilizzo dell'IQR per il rilevamento delle anomalie richiede di calcolare l'IQR del set di dati e definire i limiti inferiore e superiore dei dati per trovare le anomalie.
- Limite inferiore: Q1 – 1,5 * IQR
- Limite superiore: Q3 + 1,5 * IQR
In genere, le osservazioni che cadono al di fuori di questi limiti sono considerate anomalie.
L'algoritmo IQR è efficace per set di dati con dati distribuiti in modo non uniforme e dove la distribuzione non è ben compresa.
Parole finali
I rischi per la sicurezza informatica e le violazioni dei dati non sembrano diminuire nei prossimi anni e si prevede che questo settore rischioso crescerà ulteriormente nel 2023 e che i soli attacchi informatici IoT raddoppieranno entro il 2025.
Inoltre, i crimini informatici costeranno alle aziende e alle organizzazioni globali circa 10,3 trilioni di dollari all'anno entro il 2025.
Questo è il motivo per cui la necessità di tecniche di rilevamento delle anomalie sta diventando sempre più diffusa e necessaria oggi per il rilevamento delle frodi e la prevenzione delle intrusioni nella rete.
Questo articolo ti aiuterà a capire quali sono le anomalie nel data mining, i diversi tipi di anomalie e i modi per prevenire le intrusioni nella rete utilizzando tecniche di rilevamento delle anomalie basate su ML.
Successivamente, puoi esplorare tutto ciò che riguarda la matrice di confusione nell'apprendimento automatico.