
Cara Menyinkronkan Database Oracle Lokal Anda ke AWS
Diterbitkan: 2023-01-11Melihat perkembangan perangkat lunak perusahaan dari baris pertama selama dua dekade, tren yang tak terbantahkan selama beberapa tahun terakhir jelas – memindahkan basis data ke cloud.
Saya sudah terlibat dalam beberapa proyek migrasi, yang tujuannya adalah untuk membawa database lokal yang ada ke dalam database Cloud Amazon Web Services (AWS). Sementara dari materi dokumentasi AWS, Anda akan belajar betapa mudahnya hal ini, saya di sini untuk memberi tahu Anda bahwa pelaksanaan rencana semacam itu tidak selalu mudah, dan ada kasus di mana rencana itu bisa gagal.

Dalam posting ini, saya akan membahas pengalaman dunia nyata untuk kasus berikut:
- Sumber : Meskipun secara teori, tidak masalah apa sumber Anda (Anda dapat menggunakan pendekatan yang sangat mirip untuk sebagian besar DB paling populer), Oracle adalah sistem Database pilihan di perusahaan besar selama bertahun-tahun, dan disitulah fokus saya nantinya.
- Target : Tidak ada alasan mengapa harus spesifik di sisi ini. Anda dapat memilih database target apa pun di AWS, dan pendekatannya akan tetap sesuai.
- Mode : Anda dapat melakukan penyegaran penuh atau penyegaran tambahan. Beban data batch (status sumber dan target tertunda) atau (mendekati) beban data real-time. Keduanya akan disinggung di sini.
- Frekuensi : Anda mungkin menginginkan migrasi satu kali diikuti dengan peralihan penuh ke cloud atau memerlukan beberapa periode transisi dan memperbarui data di kedua sisi secara bersamaan, yang menyiratkan pengembangan sinkronisasi harian antara lokal dan AWS. Yang pertama lebih sederhana dan jauh lebih masuk akal, tetapi yang terakhir lebih sering diminta dan memiliki lebih banyak break point. Saya akan membahas keduanya di sini.
Deskripsi Masalah
Persyaratannya seringkali sederhana:
Kami ingin mulai mengembangkan layanan di dalam AWS, jadi harap salin semua data kami ke database "ABC". Cepat dan sederhana. Kami perlu menggunakan data di dalam AWS sekarang. Nanti, kita akan mencari tahu bagian mana dari desain DB yang harus diubah agar sesuai dengan aktivitas kita.
Sebelum melangkah lebih jauh, ada yang perlu diperhatikan:
- Jangan melompat ke ide "salin saja apa yang kita miliki dan tangani nanti" terlalu cepat. Maksud saya, ya, ini adalah cara termudah yang dapat Anda lakukan, dan ini akan dilakukan dengan cepat, tetapi ini berpotensi menciptakan masalah arsitektur mendasar yang tidak mungkin diperbaiki nanti tanpa pemfaktoran ulang yang serius dari sebagian besar platform cloud baru. . Bayangkan saja ekosistem cloud benar-benar berbeda dari yang ada di lokasi. Beberapa layanan baru akan diperkenalkan dari waktu ke waktu. Secara alami, orang akan mulai menggunakan hal yang sama dengan sangat berbeda. Hampir tidak pernah merupakan ide bagus untuk mereplikasi status lokal di cloud dengan cara 1:1. Mungkin dalam kasus khusus Anda, tetapi pastikan untuk memeriksa ulang ini.
- Pertanyakan persyaratan dengan beberapa keraguan yang berarti seperti:
- Siapa yang akan menjadi pengguna umum yang menggunakan platform baru ini? Sementara di tempat, itu bisa menjadi pengguna bisnis transaksional; di awan, itu bisa menjadi ilmuwan data atau analis gudang data, atau pengguna utama data mungkin layanan (misalnya, Databricks, Glue, model pembelajaran mesin, dll.).
- Apakah pekerjaan rutin sehari-hari diharapkan tetap ada bahkan setelah beralih ke cloud? Jika tidak, bagaimana mereka diharapkan untuk berubah?
- Apakah Anda merencanakan pertumbuhan data yang substansial dari waktu ke waktu? Kemungkinan besar, jawabannya adalah ya, karena sering kali itulah satu-satunya alasan terpenting untuk bermigrasi ke cloud. Model data baru harus siap untuk itu.
- Harapkan pengguna akhir untuk memikirkan beberapa pertanyaan umum yang diantisipasi yang akan diterima database baru dari pengguna. Ini akan menentukan seberapa banyak model data yang ada akan berubah agar tetap relevan dengan kinerja.
Menyiapkan migrasi
Setelah database target dipilih dan model data didiskusikan dengan memuaskan, langkah selanjutnya adalah membiasakan diri dengan Alat Konversi Skema AWS. Ada beberapa area di mana alat ini dapat berfungsi:
- Menganalisis dan mengekstrak model data sumber. SCT akan membaca apa yang ada di database lokal saat ini dan akan menghasilkan model data sumber untuk memulai.
- Sarankan struktur model data target berdasarkan database target.
- Hasilkan skrip penerapan database target untuk menginstal model data target (berdasarkan apa yang ditemukan alat dari database sumber). Ini akan menghasilkan skrip penerapan, dan setelah dieksekusi, database di cloud akan siap untuk memuat data dari database lokal.
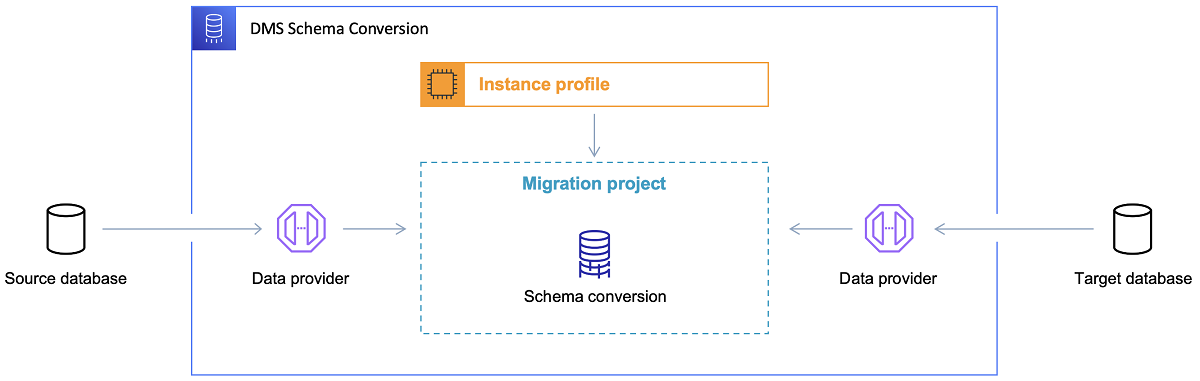
Sekarang ada beberapa tips untuk menggunakan Alat Konversi Skema.
Pertama, hampir tidak pernah menggunakan output secara langsung. Saya akan menganggapnya lebih seperti hasil referensi, dari mana Anda akan melakukan penyesuaian berdasarkan pemahaman dan tujuan Anda terhadap data dan cara bagaimana data akan digunakan di cloud.
Kedua, sebelumnya, tabel mungkin dipilih oleh pengguna yang mengharapkan hasil singkat cepat tentang beberapa entitas domain data konkret. Tapi sekarang, data mungkin dipilih untuk tujuan analitis. Misalnya, indeks basis data yang sebelumnya bekerja di basis data lokal akan menjadi tidak berguna dan pasti tidak meningkatkan kinerja sistem DB terkait dengan penggunaan baru ini. Demikian pula, Anda mungkin ingin mempartisi data secara berbeda pada sistem target, seperti sebelumnya pada sistem sumber.
Juga, mungkin baik untuk mempertimbangkan melakukan beberapa transformasi data selama proses migrasi, yang pada dasarnya berarti mengubah model data target untuk beberapa tabel (sehingga tidak lagi menjadi salinan 1:1). Nantinya, aturan transformasi perlu diimplementasikan ke dalam alat migrasi.
Mengonfigurasi alat migrasi
Jika database sumber dan target memiliki jenis yang sama (mis., Oracle lokal vs. Oracle di AWS, PostgreSQL vs. Aurora Postgresql, dll.), maka yang terbaik adalah menggunakan alat migrasi khusus yang didukung oleh database beton secara native ( misalnya, ekspor dan impor pompa data, Oracle Goldengate, dll.).
Namun, dalam banyak kasus, database sumber dan target tidak akan kompatibel, dan alat pilihan yang jelas adalah AWS Database Migration Service.
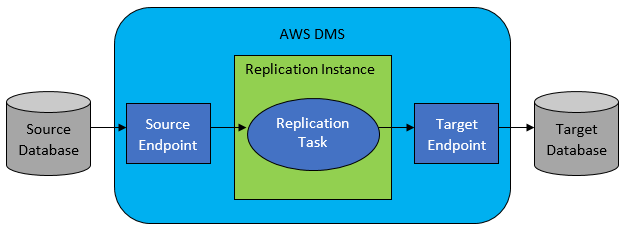
AWS DMS pada dasarnya memungkinkan mengonfigurasi daftar tugas di tingkat tabel, yang akan menentukan:
- Apa sumber DB dan tabel yang tepat untuk dihubungkan?
- Spesifikasi pernyataan yang akan digunakan untuk mendapatkan data untuk tabel target.
- Alat transformasi (jika ada), menentukan bagaimana data sumber akan dipetakan ke dalam data tabel target (jika bukan 1:1).
- Apa database dan tabel target yang tepat untuk memuat data?
Konfigurasi tugas DMS dilakukan dalam beberapa format yang mudah digunakan seperti JSON.
Sekarang dalam skenario paling sederhana, yang perlu Anda lakukan hanyalah menjalankan skrip penerapan pada database target dan memulai tugas DMS. Tapi ada jauh lebih dari itu.
Migrasi Data Penuh Satu Kali

Kasus termudah untuk dieksekusi adalah ketika permintaan untuk memindahkan seluruh database satu kali ke database cloud target. Maka pada dasarnya, semua yang perlu dilakukan akan terlihat seperti berikut:

- Tentukan Tugas DMS untuk setiap tabel sumber.
- Pastikan untuk menentukan konfigurasi pekerjaan DMS dengan benar. Ini berarti menyiapkan paralelisme yang masuk akal, variabel caching, konfigurasi server DMS, ukuran kluster DMS, dll. Ini biasanya merupakan fase yang paling memakan waktu karena memerlukan pengujian ekstensif dan penyempurnaan status konfigurasi optimal.
- Pastikan setiap tabel target dibuat (kosong) di database target dalam struktur tabel yang diharapkan.
- Jadwalkan jendela waktu di mana migrasi data akan dilakukan. Sebelum itu, jelas, pastikan (dengan melakukan tes kinerja) jendela waktu akan cukup untuk menyelesaikan migrasi. Selama migrasi itu sendiri, database sumber mungkin dibatasi dari sudut pandang kinerja. Selain itu, database sumber diharapkan tidak akan berubah selama migrasi berjalan. Jika tidak, data yang dimigrasikan mungkin berbeda dari yang disimpan di database sumber setelah migrasi selesai.
Jika konfigurasi DMS dilakukan dengan baik, tidak ada hal buruk yang akan terjadi dalam skenario ini. Setiap tabel sumber akan diambil dan disalin ke database target AWS. Satu-satunya kekhawatiran adalah performa aktivitas dan memastikan ukurannya tepat di setiap langkah sehingga tidak akan gagal karena ruang penyimpanan tidak mencukupi.
Sinkronisasi Harian Tambahan

Di sinilah segalanya mulai menjadi rumit. Maksud saya, jika dunia ini ideal, maka mungkin akan bekerja dengan baik sepanjang waktu. Tapi dunia tidak pernah ideal.
DMS dapat dikonfigurasi untuk beroperasi dalam dua mode:
- Beban penuh – mode default yang dijelaskan dan digunakan di atas. Tugas DMS dimulai saat Anda memulainya atau saat dijadwalkan untuk dimulai. Setelah selesai, tugas DMS selesai.
- Ubah Pengambilan Data (CDC) – dalam mode ini, tugas DMS berjalan terus menerus. DMS memindai basis data sumber untuk perubahan pada tingkat tabel. Jika perubahan terjadi, ia segera mencoba mereplikasi perubahan di database target berdasarkan konfigurasi di dalam tugas DMS yang terkait dengan tabel yang diubah.
Saat menggunakan CDC, Anda perlu membuat pilihan lain – yaitu, bagaimana CDC akan mengekstrak perubahan delta dari sumber DB.
#1. Oracle Redo Log Pembaca
Salah satu opsi adalah memilih pembaca redo log basis data asli dari Oracle, yang dapat digunakan CDC untuk mendapatkan data yang diubah, dan, berdasarkan perubahan terbaru, mereplikasi perubahan yang sama pada basis data target.
Meskipun ini mungkin terlihat seperti pilihan yang jelas jika berurusan dengan Oracle sebagai sumbernya, ada tangkapan: Oracle redo logs reader menggunakan sumber Oracle cluster dan secara langsung memengaruhi semua aktivitas lain yang berjalan di database (sebenarnya secara langsung membuat sesi aktif di data).
Semakin banyak Tugas DMS yang telah Anda konfigurasikan (atau semakin banyak cluster DMS secara paralel), semakin besar kemungkinan Anda perlu memperbesar cluster Oracle – pada dasarnya, sesuaikan penskalaan vertikal cluster database Oracle utama Anda. Ini pasti akan mempengaruhi total biaya solusi, terlebih lagi jika sinkronisasi harian akan bertahan dengan proyek untuk jangka waktu yang lama.
#2. Penambang Log AWS DMS
Berbeda dengan opsi di atas, ini adalah solusi AWS asli untuk masalah yang sama. Dalam hal ini, DMS tidak mempengaruhi sumber Oracle DB. Sebagai gantinya, ia menyalin Oracle redo log ke dalam kluster DMS dan melakukan semua pemrosesan di sana. Meskipun menghemat sumber daya Oracle, ini adalah solusi yang lebih lambat, karena lebih banyak operasi yang terlibat. Dan juga, seperti yang dapat dengan mudah diasumsikan, pembaca khusus untuk log redo Oracle mungkin lebih lambat dalam tugasnya sebagai pembaca asli dari Oracle.
Bergantung pada ukuran database sumber dan jumlah perubahan harian di sana, dalam skenario kasus terbaik, Anda mungkin berakhir dengan sinkronisasi inkremental hampir secara real-time dari data dari database Oracle lokal ke database cloud AWS.
Dalam skenario lain, itu masih tidak akan mendekati sinkronisasi waktu-nyata, tetapi Anda dapat mencoba sedekat mungkin dengan penundaan yang diterima (antara sumber dan target) dengan menyesuaikan konfigurasi kinerja sumber dan cluster target dan paralelisme atau bereksperimen dengan jumlah tugas DMS dan pendistribusiannya di antara instance CDC.
Dan Anda mungkin ingin mempelajari perubahan tabel sumber mana yang didukung oleh CDC (seperti penambahan kolom, misalnya) karena tidak semua kemungkinan perubahan didukung. Dalam beberapa kasus, satu-satunya cara adalah membuat tabel target berubah secara manual dan memulai kembali tugas CDC dari awal (kehilangan semua data yang ada di database target selama ini).
Ketika Semuanya Salah, Tidak Peduli Apapun

Saya mempelajarinya dengan cara yang sulit, tetapi ada satu skenario khusus yang terkait dengan DMS di mana janji replikasi harian sulit dicapai.
DMS dapat memproses redo log hanya dengan kecepatan tertentu. Tidak masalah jika ada lebih banyak contoh DMS yang menjalankan tugas Anda. Namun, setiap instance DMS membaca redo log hanya dengan satu kecepatan yang ditentukan, dan masing-masing dari mereka harus membacanya secara keseluruhan. Bahkan tidak masalah jika Anda menggunakan Oracle Redo Logs atau AWS Log Miner. Keduanya memiliki batas ini.
Jika basis data sumber mencakup sejumlah besar perubahan dalam satu hari sehingga log redo Oracle menjadi sangat besar (seperti 500GB + besar) setiap hari, CDC tidak akan berfungsi. Replikasi tidak akan selesai sebelum akhir hari. Ini akan membawa beberapa pekerjaan yang belum diproses ke hari berikutnya, di mana serangkaian perubahan baru untuk direplikasi sudah menunggu. Jumlah data yang tidak diproses hanya akan bertambah dari hari ke hari.
Dalam kasus khusus ini, CDC bukanlah pilihan (setelah banyak pengujian kinerja dan percobaan yang kami lakukan). Satu-satunya cara untuk memastikan setidaknya semua perubahan delta dari hari ini akan direplikasi pada hari yang sama adalah dengan melakukan pendekatan seperti ini:
- Pisahkan tabel yang sangat besar yang tidak terlalu sering digunakan dan ulangi hanya sekali seminggu (misalnya, selama akhir pekan).
- Mengonfigurasi replikasi tabel yang tidak terlalu besar tetapi masih besar untuk dibagi di antara beberapa tugas DMS; satu tabel akhirnya dimigrasikan oleh 10 atau lebih tugas DMS terpisah secara paralel, memastikan pemisahan data antara tugas DMS berbeda (pengkodean khusus terlibat di sini) dan menjalankannya setiap hari.
- Tambahkan lebih banyak (hingga 4 dalam kasus ini) instance DMS dan pisahkan tugas DMS di antara mereka secara merata, yang berarti tidak hanya berdasarkan jumlah tabel tetapi juga ukurannya.
Pada dasarnya, kami menggunakan mode beban penuh DMS untuk mereplikasi data harian karena itulah satu-satunya cara untuk mencapai setidaknya penyelesaian replikasi data pada hari yang sama.
Bukan solusi yang sempurna, tetapi masih ada, dan bahkan setelah bertahun-tahun, masih bekerja dengan cara yang sama. Jadi, mungkin bukan solusi yang buruk.