
Mendukung Mesin Vektor (SVM) dalam Pembelajaran Mesin
Diterbitkan: 2023-01-04Support Vector Machine adalah salah satu algoritma Machine Learning yang paling populer. Ini efisien dan dapat melatih dalam kumpulan data terbatas. Tapi apa itu?
Apa itu Mesin Vektor Dukungan (SVM)?
Support vector machine adalah algoritma pembelajaran mesin yang menggunakan pembelajaran terawasi untuk membuat model klasifikasi biner. Itu seteguk. Artikel ini akan menjelaskan SVM dan hubungannya dengan pemrosesan bahasa alami. Tapi pertama-tama, mari kita menganalisis cara kerja mesin vektor dukungan.
Bagaimana SVM Bekerja?
Pertimbangkan masalah klasifikasi sederhana di mana kita memiliki data yang memiliki dua fitur, x dan y, dan satu keluaran – klasifikasi yang berwarna merah atau biru. Kita dapat memplot kumpulan data imajiner yang terlihat seperti ini:
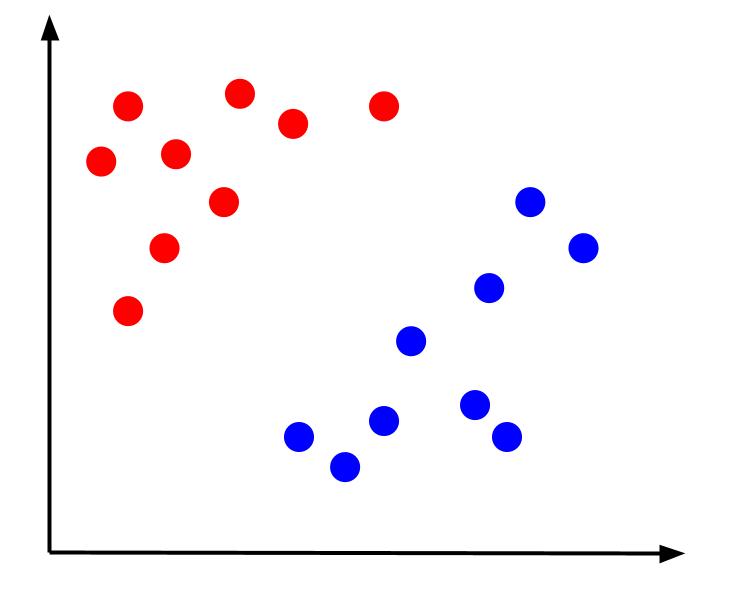
Mengingat data seperti ini, tugasnya adalah membuat batas keputusan. Batas keputusan adalah garis yang memisahkan dua kelas titik data kami. Ini adalah kumpulan data yang sama tetapi dengan batas keputusan:
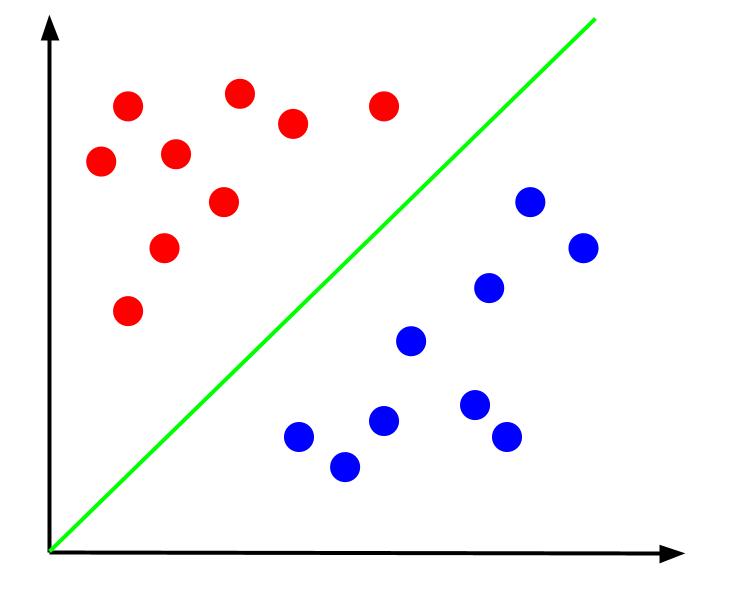
Dengan batas keputusan ini, kita kemudian dapat membuat prediksi untuk kelas mana suatu titik data berada, mengingat letaknya relatif terhadap batas keputusan. Algoritma Support Vector Machine menciptakan batas keputusan terbaik yang akan digunakan untuk mengklasifikasikan poin.
Tapi apa yang kita maksud dengan batas keputusan terbaik?
Batas keputusan terbaik dapat dikatakan sebagai batas yang memaksimalkan jaraknya dari salah satu vektor pendukung. Vektor dukungan adalah titik data dari salah satu kelas yang paling dekat dengan kelas lawan. Poin data ini menimbulkan risiko kesalahan klasifikasi terbesar karena kedekatannya dengan kelas lain.
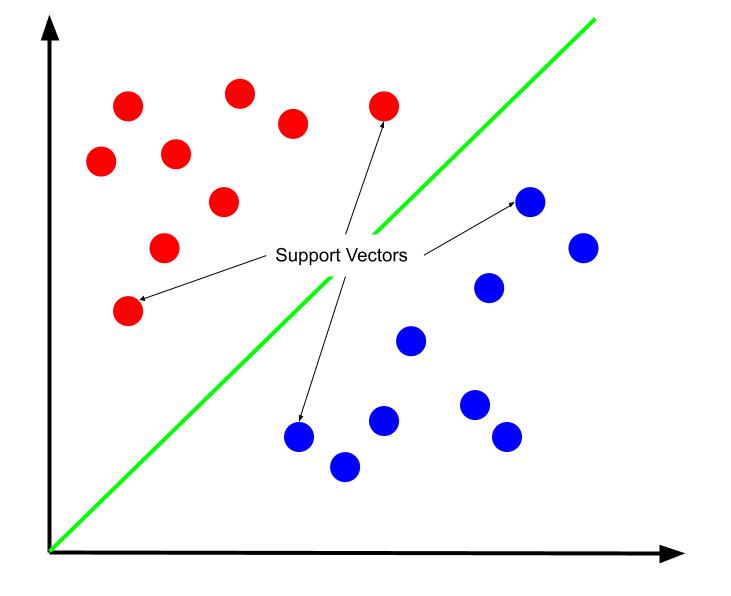
Oleh karena itu, pelatihan mesin vektor pendukung melibatkan upaya untuk menemukan garis yang memaksimalkan margin antara vektor pendukung.
Penting juga untuk dicatat bahwa karena batas keputusan diposisikan relatif terhadap vektor pendukung, mereka adalah satu-satunya penentu posisi batas keputusan. Oleh karena itu, poin data lainnya berlebihan. Dan dengan demikian, pelatihan hanya membutuhkan vektor pendukung.
Dalam contoh ini, batas keputusan yang terbentuk adalah garis lurus. Ini hanya karena dataset hanya memiliki dua fitur. Ketika dataset memiliki tiga fitur, batas keputusan yang terbentuk adalah bidang bukan garis. Dan ketika memiliki empat atau lebih fitur, batas keputusan dikenal sebagai hyperplane.
Data yang Tidak Dapat Dipisahkan Secara Linear
Contoh di atas menganggap data yang sangat sederhana, ketika diplot, dapat dipisahkan oleh batas keputusan linier. Pertimbangkan kasus lain di mana data diplot sebagai berikut:
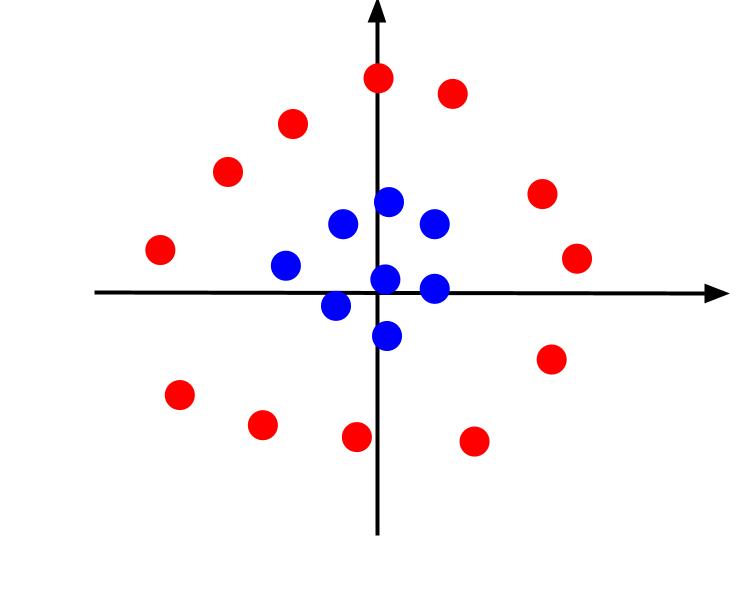
Dalam hal ini, memisahkan data menggunakan garis tidak mungkin dilakukan. Tetapi kami dapat membuat fitur lain, z. Dan fitur ini dapat didefinisikan dengan persamaan: z = x^2 + y^2. Kita dapat menambahkan z sebagai sumbu ketiga pada bidang untuk membuatnya menjadi tiga dimensi.
Saat kita melihat plot 3D dari sudut sedemikian rupa sehingga sumbu x horizontal sedangkan sumbu z vertikal, inilah tampilan yang kita dapatkan seperti ini:
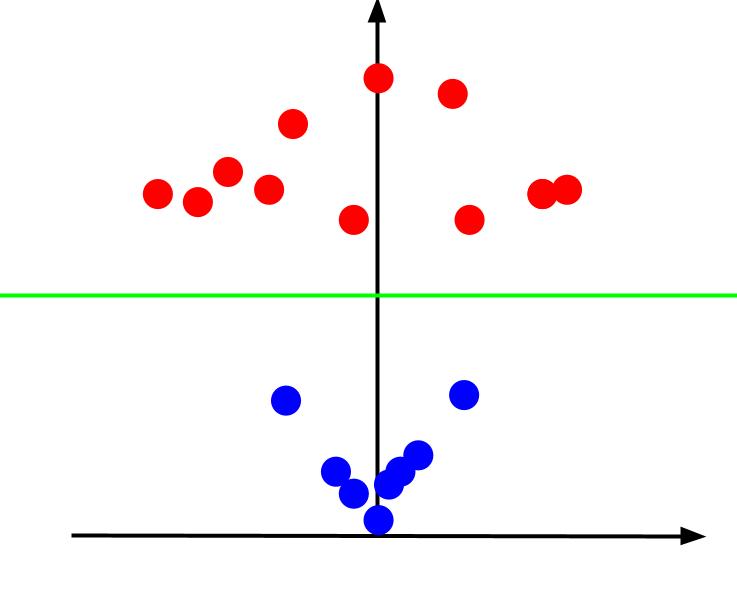
Nilai-z mewakili seberapa jauh suatu titik dari titik asal relatif terhadap titik-titik lain di bidang XY lama. Akibatnya, titik biru yang lebih dekat ke titik asal memiliki nilai z yang rendah.
Sementara titik merah yang lebih jauh dari asal memiliki nilai z yang lebih tinggi, memplotnya dengan nilai znya memberi kita klasifikasi yang jelas yang dapat dibatasi oleh batas keputusan linier, seperti yang diilustrasikan.
Ini adalah ide hebat yang digunakan dalam Support Vector Machines. Secara lebih umum, ini adalah gagasan untuk memetakan dimensi ke dalam jumlah dimensi yang lebih tinggi sehingga titik data dapat dipisahkan oleh batas linier. Fungsi yang bertanggung jawab untuk ini adalah fungsi kernel. Ada banyak fungsi kernel, seperti sigmoid, linear, non-linear, dan RBF.
Untuk membuat pemetaan fitur ini lebih efisien, SVM menggunakan trik kernel.
SVM dalam Pembelajaran Mesin
Support Vector Machine adalah salah satu dari banyak algoritme yang digunakan dalam pembelajaran mesin bersama algoritme populer seperti Decision Trees dan Neural Networks. Ini disukai karena bekerja dengan baik dengan data lebih sedikit daripada algoritma lainnya. Biasanya digunakan untuk melakukan hal berikut:
- Klasifikasi Teks : Mengklasifikasikan data teks seperti komentar dan ulasan ke dalam satu atau beberapa kategori
- Deteksi Wajah : Menganalisis gambar untuk mendeteksi wajah untuk melakukan hal-hal seperti menambahkan filter untuk augmented reality
- Klasifikasi Gambar : Mesin vektor pendukung dapat mengklasifikasikan gambar secara efisien dibandingkan dengan pendekatan lain.
Masalah Klasifikasi Teks
Internet dipenuhi dengan banyak sekali data tekstual. Namun, banyak dari data ini tidak terstruktur dan tidak berlabel. Untuk lebih menggunakan data teks ini dan lebih memahaminya, diperlukan klasifikasi. Contoh waktu ketika teks diklasifikasikan meliputi:
- Ketika tweet dikategorikan ke dalam topik sehingga orang dapat mengikuti topik yang mereka inginkan
- Saat email dikategorikan sebagai Sosial, Promosi, atau Spam
- Ketika komentar diklasifikasikan sebagai kebencian atau cabul di forum publik
Bagaimana SVM Bekerja Dengan Klasifikasi Bahasa Alami
Support Vector Machine digunakan untuk mengklasifikasikan teks menjadi teks yang termasuk dalam topik tertentu dan teks yang tidak termasuk dalam topik. Ini dicapai dengan terlebih dahulu mengubah dan merepresentasikan data teks menjadi kumpulan data dengan beberapa fitur.
Salah satu cara untuk melakukannya adalah dengan membuat fitur untuk setiap kata dalam kumpulan data. Kemudian untuk setiap titik data teks, Anda mencatat berapa kali setiap kata muncul. Jadi misalkan kata-kata unik muncul di kumpulan data; Anda akan memiliki fitur dalam kumpulan data.
Selain itu, Anda akan memberikan klasifikasi untuk poin data ini. Sementara klasifikasi ini diberi label dengan teks, sebagian besar implementasi SVM mengharapkan label numerik.
Oleh karena itu, Anda harus mengonversi label ini menjadi angka sebelum pelatihan. Setelah kumpulan data disiapkan, menggunakan fitur-fitur ini sebagai koordinat, Anda kemudian dapat menggunakan model SVM untuk mengklasifikasikan teks.
Membuat SVM dengan Python
Untuk membuat mesin vektor dukungan (SVM) dengan Python, Anda dapat menggunakan kelas SVC dari pustaka sklearn.svm . Berikut adalah contoh bagaimana Anda bisa menggunakan kelas SVC untuk membangun model SVM dengan Python:
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) Dalam contoh ini, pertama-tama kita mengimpor kelas SVC dari pustaka sklearn.svm . Kemudian, kami memuat dataset dan membaginya menjadi set pelatihan dan pengujian.
Selanjutnya, kita membuat model SVM dengan membuat instance objek SVC dan menentukan parameter kernel sebagai 'linear'. Kami kemudian melatih model pada data pelatihan menggunakan metode fit dan mengevaluasi model pada data uji menggunakan metode score . Metode score mengembalikan akurasi model, yang kami cetak ke konsol.
Anda juga dapat menentukan parameter lain untuk objek SVC , seperti parameter C yang mengontrol kekuatan regularisasi, dan parameter gamma , yang mengontrol koefisien kernel untuk kernel tertentu.
Manfaat SVM
Berikut adalah daftar beberapa manfaat menggunakan mesin vektor dukungan (SVM):
- Efisien : SVM umumnya efisien untuk dilatih, terutama bila jumlah sampelnya besar.
- Kuat terhadap Kebisingan : SVM relatif kuat terhadap kebisingan dalam data pelatihan saat mereka mencoba menemukan pengklasifikasi margin maksimum, yang kurang sensitif terhadap kebisingan dibandingkan pengklasifikasi lainnya.
- Hemat Memori: SVM hanya membutuhkan subset dari data pelatihan untuk berada di memori pada waktu tertentu, menjadikannya lebih hemat memori daripada algoritme lainnya.
- Efektif di Ruang Dimensi Tinggi: SVM masih dapat bekerja dengan baik meskipun jumlah fitur melebihi jumlah sampel.
- Keserbagunaan : SVM dapat digunakan untuk tugas klasifikasi dan regresi dan dapat menangani berbagai jenis data, termasuk data linier dan non-linier.
Sekarang, mari jelajahi beberapa sumber daya terbaik untuk mempelajari Support Vector Machine (SVM).

Sumber Belajar
Pengantar untuk Mendukung Mesin Vektor
Buku Pengantar Support Vector Machines ini secara komprehensif dan bertahap memperkenalkan Anda pada metode Pembelajaran berbasis Kernel.
| Pratinjau | Produk | Peringkat | Harga | |
|---|---|---|---|---|
 | Pengantar untuk Mendukung Mesin Vektor dan Metode Pembelajaran Berbasis Kernel Lainnya | $75.00 | Beli di Amazon |
Ini memberi Anda dasar yang kuat pada teori Support Vector Machines.
Mendukung Aplikasi Mesin Vektor
Jika buku pertama berfokus pada teori Support Vector Machines, buku tentang Aplikasi Support Vector Machines ini berfokus pada aplikasi praktisnya.
| Pratinjau | Produk | Peringkat | Harga | |
|---|---|---|---|---|
 | Mendukung Aplikasi Mesin Vektor | $15,52 | Beli di Amazon |
Ini melihat bagaimana SVM digunakan dalam pemrosesan gambar, deteksi pola, dan visi komputer.
Mendukung Mesin Vektor (Ilmu Informasi dan Statistik)
Tujuan dari buku Support Vector Machines (Ilmu Informasi dan Statistik) ini adalah untuk memberikan gambaran tentang prinsip-prinsip di balik efektivitas support vector machine (SVM) dalam berbagai aplikasi.
| Pratinjau | Produk | Peringkat | Harga | |
|---|---|---|---|---|
 | Mendukung Mesin Vektor (Ilmu Informasi dan Statistik) | $167,36 | Beli di Amazon |
Penulis menyoroti beberapa faktor yang berkontribusi terhadap keberhasilan SVM, termasuk kemampuannya untuk bekerja dengan baik dengan sejumlah parameter yang dapat disesuaikan, ketahanannya terhadap berbagai jenis kesalahan dan anomali, dan kinerja komputasi yang efisien dibandingkan dengan metode lain.
Belajar dengan Kernel
“Belajar dengan Kernel” adalah buku yang memperkenalkan pembaca untuk mendukung mesin vektor (SVM) dan teknik kernel terkait.
| Pratinjau | Produk | Peringkat | Harga | |
|---|---|---|---|---|
 | Belajar dengan Kernel: Mendukung Mesin Vektor, Regularisasi, Optimasi, dan Selanjutnya (Adaptif… | $80,00 | Beli di Amazon |
Ini dirancang untuk memberi pembaca pemahaman dasar matematika dan pengetahuan yang mereka butuhkan untuk mulai menggunakan algoritma kernel dalam pembelajaran mesin. Buku ini bertujuan untuk memberikan pengantar SVM dan metode kernel yang menyeluruh namun dapat diakses.
Dukung Mesin Vektor dengan Sci-kit Learn
Kursus Mesin Vektor Dukungan online dengan Sci-kit Learn oleh jaringan proyek Coursera ini mengajarkan cara menerapkan model SVM menggunakan pustaka pembelajaran mesin populer, Sci-Kit Learn.

Selain itu, Anda akan mempelajari teori di balik SVM dan menentukan kekuatan dan keterbatasannya. Kursus ini tingkat pemula dan membutuhkan waktu sekitar 2,5 jam.
Mendukung Mesin Vektor dengan Python: Konsep dan Kode
Kursus online berbayar tentang Mesin Vektor Dukungan dengan Python oleh Udemy ini memiliki instruksi berbasis video hingga 6 jam dan dilengkapi dengan sertifikasi.

Ini mencakup SVM dan bagaimana mereka dapat diimplementasikan dengan kuat di Python. Selain itu, ini mencakup aplikasi bisnis dari Support Vector Machines.
Pembelajaran Mesin dan AI: Mendukung Mesin Vektor dengan Python
Dalam kursus Pembelajaran Mesin dan AI ini, Anda akan mempelajari cara menggunakan mesin vektor dukungan (SVM) untuk berbagai aplikasi praktis, termasuk pengenalan gambar, deteksi spam, diagnosis medis, dan analisis regresi.

Anda akan menggunakan bahasa pemrograman Python untuk mengimplementasikan model ML untuk aplikasi ini.
Kata Akhir
Pada artikel ini, kita mempelajari secara singkat tentang teori di balik Support Vector Machines. Kami belajar tentang penerapannya dalam Machine Learning dan Natural Langauge Processing.
Kami juga melihat seperti apa penerapannya menggunakan scikit-learn . Selanjutnya, kami berbicara tentang aplikasi praktis dan manfaat dari Support Vector Machines.
Sementara artikel ini hanya pengantar, sumber daya tambahan direkomendasikan untuk lebih detail, menjelaskan lebih banyak tentang Mesin Vektor Dukungan. Mengingat betapa fleksibel dan efisiennya mereka, SVM layak dipahami untuk tumbuh sebagai ilmuwan data dan insinyur ML.
Selanjutnya, Anda dapat melihat model pembelajaran mesin teratas.