
Regresi vs. Klasifikasi dalam Pembelajaran Mesin Dijelaskan
Diterbitkan: 2022-12-19Regresi dan klasifikasi adalah dua bidang pembelajaran mesin yang paling mendasar dan signifikan.
Sulit untuk membedakan antara algoritme Regresi dan Klasifikasi saat Anda baru mempelajari pembelajaran mesin. Memahami cara kerja algoritme ini dan kapan menggunakannya dapat menjadi sangat penting untuk membuat prediksi yang akurat dan keputusan yang efektif.
Pertama, Mari kita lihat tentang pembelajaran mesin.
Apa itu Pembelajaran mesin?

Pembelajaran mesin adalah metode mengajar komputer untuk belajar dan membuat keputusan tanpa diprogram secara eksplisit. Ini melibatkan pelatihan model komputer pada kumpulan data, memungkinkan model membuat prediksi atau keputusan berdasarkan pola dan hubungan dalam data.
Ada tiga jenis utama pembelajaran mesin: pembelajaran terawasi, pembelajaran tanpa pengawasan, dan pembelajaran penguatan.
Dalam Supervised learning , model dilengkapi dengan data pelatihan berlabel, termasuk data input dan output yang sesuai. Tujuannya agar model membuat prediksi tentang output untuk data baru yang tidak terlihat berdasarkan pola yang dipelajari dari data pelatihan.
Dalam Unsupervised learning , model tidak diberi data pelatihan berlabel. Sebaliknya, dibiarkan menemukan pola dan hubungan dalam data secara mandiri. Ini dapat digunakan untuk mengidentifikasi grup atau cluster dalam data atau untuk menemukan anomali atau pola yang tidak biasa.
Dan dalam Reinforcement Learning , seorang agen belajar berinteraksi dengan lingkungannya untuk memaksimalkan hadiah. Ini melibatkan pelatihan model untuk membuat keputusan berdasarkan umpan balik yang diterimanya dari lingkungan.
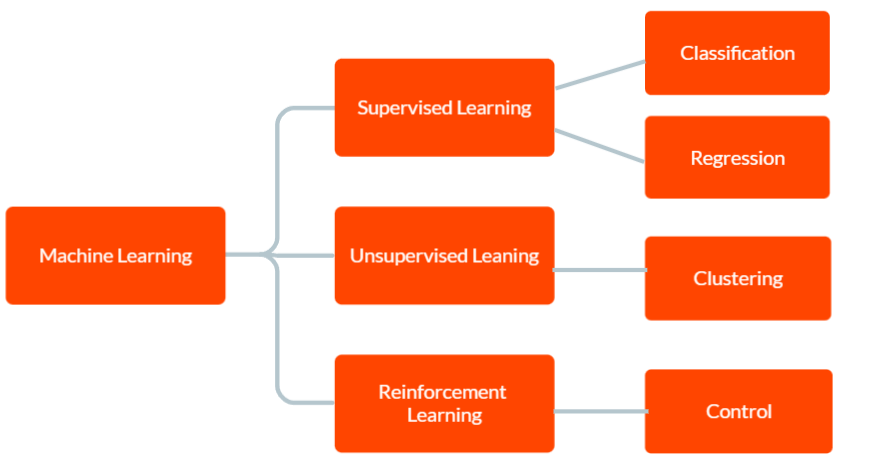
Pembelajaran mesin digunakan dalam berbagai aplikasi, termasuk pengenalan gambar dan ucapan, pemrosesan bahasa alami, deteksi penipuan, dan mobil tanpa pengemudi. Ini memiliki potensi untuk mengotomatiskan banyak tugas dan meningkatkan pengambilan keputusan di berbagai industri.
Artikel ini terutama berfokus pada konsep Klasifikasi dan Regresi, yang berada di bawah pembelajaran mesin yang diawasi. Mari kita mulai!
Klasifikasi dalam Pembelajaran Mesin

Klasifikasi adalah teknik pembelajaran mesin yang melibatkan pelatihan model untuk menetapkan label kelas ke input yang diberikan. Ini adalah tugas pembelajaran yang diawasi, yang berarti bahwa model dilatih pada kumpulan data berlabel yang menyertakan contoh data input dan label kelas yang sesuai.
Model ini bertujuan untuk mempelajari hubungan antara input data dan label kelas untuk memprediksi label kelas untuk input baru yang tidak terlihat.
Ada banyak algoritma berbeda yang dapat digunakan untuk klasifikasi, termasuk regresi logistik, pohon keputusan, dan mesin vektor dukungan. Pemilihan algoritma akan bergantung pada karakteristik data dan performa model yang diinginkan.
Beberapa aplikasi klasifikasi umum termasuk deteksi spam, analisis sentimen, dan deteksi penipuan. Dalam setiap kasus ini, data input mungkin menyertakan teks, nilai numerik, atau kombinasi keduanya. Label kelas dapat berupa biner (misalnya, spam atau bukan spam) atau multi-kelas (misalnya, sentimen positif, netral, negatif).
Misalnya, pertimbangkan kumpulan data ulasan pelanggan terhadap suatu produk. Data masukan bisa berupa teks ulasan, dan label kelas bisa berupa peringkat (misalnya, positif, netral, negatif). Model akan dilatih pada kumpulan data ulasan berlabel dan kemudian akan dapat memprediksi peringkat ulasan baru yang belum pernah dilihat sebelumnya.
Jenis Algoritma Klasifikasi ML
Ada beberapa jenis algoritma klasifikasi dalam pembelajaran mesin:
Regresi logistik
Ini adalah model linier yang digunakan untuk klasifikasi biner. Ini digunakan untuk memprediksi kemungkinan terjadinya peristiwa tertentu. Tujuan regresi logistik adalah menemukan koefisien (bobot) terbaik yang meminimalkan kesalahan antara probabilitas yang diprediksi dan hasil yang diamati.
Hal ini dilakukan dengan menggunakan algoritme pengoptimalan, seperti penurunan gradien, untuk menyesuaikan koefisien hingga model sesuai dengan data pelatihan sebaik mungkin.
Pohon Keputusan
Ini adalah model seperti pohon yang membuat keputusan berdasarkan nilai fitur. Mereka dapat digunakan untuk klasifikasi biner dan multi-kelas. Pohon keputusan memiliki beberapa keunggulan, termasuk kesederhanaan dan interoperabilitasnya.
Mereka juga cepat untuk melatih dan membuat prediksi, dan mereka dapat menangani data numerik dan kategorikal. Namun, mereka rentan terhadap overfitting, terutama jika pohonnya dalam dan memiliki banyak cabang.
Klasifikasi Hutan Acak
Klasifikasi Hutan Acak adalah metode ansambel yang menggabungkan prediksi dari beberapa pohon keputusan untuk membuat prediksi yang lebih akurat dan stabil. Ini kurang rentan terhadap overfitting daripada pohon keputusan tunggal karena prediksi masing-masing pohon dirata-ratakan, yang mengurangi varians dalam model.
AdaBoost
Ini adalah algoritme penguat yang secara adaptif mengubah bobot contoh yang salah klasifikasi dalam set pelatihan. Ini sering digunakan untuk klasifikasi biner.
Naif Bayes
Naive Bayes didasarkan pada teorema Bayes, yang merupakan cara memperbarui probabilitas suatu peristiwa berdasarkan bukti baru. Ini adalah pengklasifikasi probabilistik yang sering digunakan untuk klasifikasi teks dan pemfilteran spam.
K-Tetangga Terdekat
K-Nearest Neighbors (KNN) digunakan untuk tugas klasifikasi dan regresi. Ini adalah metode non-parametrik yang mengklasifikasikan titik data berdasarkan kelas tetangga terdekatnya. KNN memiliki beberapa keunggulan, termasuk kesederhanaannya dan mudah diimplementasikan. Itu juga dapat menangani data numerik dan kategorikal, dan tidak membuat asumsi apa pun tentang distribusi data yang mendasarinya.
Peningkatan Gradien
Ini adalah ansambel pembelajar lemah yang dilatih secara berurutan, dengan masing-masing model berusaha memperbaiki kesalahan model sebelumnya. Mereka dapat digunakan untuk klasifikasi dan regresi.
Regresi dalam Pembelajaran Mesin
Dalam pembelajaran mesin, regresi adalah jenis pembelajaran terawasi di mana tujuannya adalah untuk memprediksi variabel dependen ac berdasarkan satu atau lebih fitur input (disebut juga prediktor atau variabel independen).
Algoritma regresi digunakan untuk memodelkan hubungan antara input dan output dan membuat prediksi berdasarkan hubungan tersebut. Regresi dapat digunakan untuk variabel dependen kontinu dan kategorikal.

Secara umum, tujuan regresi adalah untuk membangun model yang dapat secara akurat memprediksi output berdasarkan fitur input dan untuk memahami hubungan mendasar antara fitur input dan output.
Analisis regresi digunakan di berbagai bidang, termasuk ekonomi, keuangan, pemasaran, dan psikologi, untuk memahami dan memprediksi hubungan antara variabel yang berbeda. Ini adalah alat fundamental dalam analisis data dan pembelajaran mesin dan digunakan untuk membuat prediksi, mengidentifikasi tren, dan memahami mekanisme dasar yang menggerakkan data.
Misalnya, dalam model regresi linier sederhana, tujuannya mungkin untuk memprediksi harga rumah berdasarkan ukuran, lokasi, dan fitur lainnya. Ukuran rumah dan lokasinya akan menjadi variabel bebas, dan harga rumah akan menjadi variabel terikat.
Model akan dilatih tentang data input yang mencakup ukuran dan lokasi beberapa rumah, beserta harganya. Setelah model dilatih, model tersebut dapat digunakan untuk membuat prediksi tentang harga sebuah rumah, berdasarkan ukuran dan lokasinya.
Jenis Algoritma Regresi ML
Algoritma regresi tersedia dalam berbagai bentuk, dan penggunaan masing-masing algoritma bergantung pada jumlah parameter, seperti jenis nilai atribut, pola garis tren, dan jumlah variabel independen. Teknik regresi yang sering digunakan antara lain:
Regresi linier
Model linier sederhana ini digunakan untuk memprediksi nilai kontinu berdasarkan sekumpulan fitur. Ini digunakan untuk memodelkan hubungan antara fitur dan variabel target dengan memasang garis ke data.
Regresi Polinomial
Ini adalah model non-linier yang digunakan untuk mencocokkan kurva dengan data. Ini digunakan untuk memodelkan hubungan antara fitur dan variabel target ketika hubungannya tidak linier. Ini didasarkan pada gagasan untuk menambahkan suku orde tinggi ke model linear untuk menangkap hubungan non-linear antara variabel dependen dan independen.
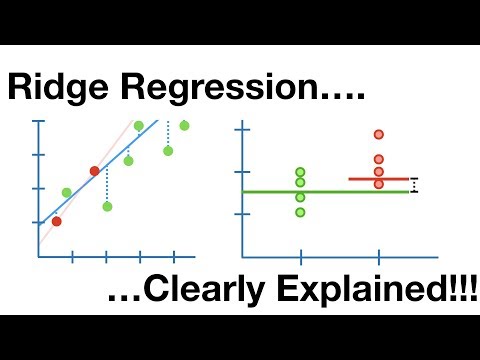
Regresi Punggungan
Ini adalah model linier yang membahas overfitting dalam regresi linier. Ini adalah versi reguler dari regresi linier yang menambahkan istilah penalti ke fungsi biaya untuk mengurangi kompleksitas model.
Mendukung Regresi Vektor
Seperti SVM, Support Vector Regression adalah model linear yang mencoba menyesuaikan data dengan menemukan hyperplane yang memaksimalkan margin antara variabel dependen dan independen.
Namun, tidak seperti SVM, yang digunakan untuk klasifikasi, SVR digunakan untuk tugas regresi, di mana tujuannya adalah untuk memprediksi nilai kontinu daripada label kelas.
Regresi Lasso
Ini adalah model linier teregulasi lainnya yang digunakan untuk mencegah overfitting dalam regresi linier. Ini menambahkan istilah penalti ke fungsi biaya berdasarkan nilai absolut dari koefisien.
Regresi Linear Bayesian
Regresi Linear Bayesian adalah pendekatan probabilistik untuk regresi linier berdasarkan teorema Bayes, yang merupakan cara memperbarui probabilitas suatu peristiwa berdasarkan bukti baru.
Model regresi ini bertujuan untuk mengestimasi distribusi posterior dari parameter model yang diberikan data. Ini dilakukan dengan mendefinisikan distribusi sebelumnya pada parameter dan kemudian menggunakan teorema Bayes untuk memperbarui distribusi berdasarkan data yang diamati.
Regresi vs Klasifikasi
Regresi dan klasifikasi adalah dua jenis pembelajaran terawasi, yang artinya digunakan untuk memprediksi keluaran berdasarkan serangkaian fitur masukan. Namun, ada beberapa perbedaan utama antara keduanya:
| Regresi | Klasifikasi | |
| Definisi | Jenis pembelajaran terawasi yang memprediksi nilai berkelanjutan | Jenis pembelajaran yang diawasi yang memprediksi nilai kategorikal |
| Jenis keluaran | Kontinu | Diskrit |
| Metrik evaluasi | Kesalahan kuadrat rata-rata (MSE), kesalahan kuadrat rata-rata akar (RMSE) | Akurasi, presisi, daya ingat, skor F1 |
| Algoritma | Regresi linier, Lasso, Ridge, KNN, Pohon Keputusan | Regresi logistik, SVM, Naive Bayes, KNN, Pohon Keputusan |
| Kompleksitas model | Model yang kurang kompleks | Model yang lebih kompleks |
| Asumsi | Hubungan linier antara fitur dan target | Tidak ada asumsi khusus tentang hubungan antara fitur dan target |
| Ketidakseimbangan kelas | Tak dapat diterapkan | Ini bisa menjadi masalah |
| Penyimpangan | Dapat memengaruhi performa model | Biasanya tidak masalah |
| Pentingnya fitur | Fitur diberi peringkat berdasarkan kepentingan | Fitur tidak diberi peringkat berdasarkan kepentingan |
| Contoh aplikasi | Memprediksi harga, suhu, kuantitas | Memprediksi apakah email spam, memprediksi churn pelanggan |
Sumber Belajar
Mungkin sulit untuk memilih sumber daya online terbaik untuk memahami konsep pembelajaran mesin. Kami telah memeriksa kursus populer yang disediakan oleh platform andal untuk memberi Anda rekomendasi kami untuk kursus ML teratas tentang regresi dan klasifikasi.
#1. Kamp Pelatihan Klasifikasi Pembelajaran Mesin dengan Python
Ini adalah kursus yang ditawarkan di platform Udemy. Ini mencakup berbagai algoritma dan teknik klasifikasi, termasuk pohon keputusan dan regresi logistik, dan mendukung mesin vektor.

Anda juga dapat mempelajari tentang topik seperti overfitting, tradeoff bias-varians, dan evaluasi model. Kursus ini menggunakan pustaka Python seperti sci-kit-learn dan panda untuk mengimplementasikan dan mengevaluasi model pembelajaran mesin. Jadi, pengetahuan dasar python diperlukan untuk memulai kursus ini.
#2. Masterclass Regresi Pembelajaran Mesin dengan Python
Dalam kursus Udemy ini, Pelatih Meliputi dasar-dasar dan teori yang mendasari berbagai algoritme regresi, termasuk regresi linier, regresi polinomial, dan teknik regresi Lasso & Ridge.
Di akhir kursus ini, Anda akan dapat menerapkan algoritme regresi dan menilai performa model Machine learning yang dilatih menggunakan berbagai indikator Performa Utama.
Membungkus
Algoritme pembelajaran mesin bisa sangat berguna dalam banyak aplikasi, dan dapat membantu mengotomatiskan dan merampingkan banyak proses. Algoritme ML menggunakan teknik statistik untuk mempelajari pola dalam data dan membuat prediksi atau keputusan berdasarkan pola tersebut.
Mereka dapat dilatih pada data dalam jumlah besar dan dapat digunakan untuk melakukan tugas-tugas yang sulit atau memakan waktu bagi manusia untuk melakukannya secara manual.
Setiap algoritme ML memiliki kekuatan dan kelemahannya masing-masing, dan pilihan algoritme bergantung pada sifat data dan persyaratan tugas. Penting untuk memilih algoritme atau kombinasi algoritme yang tepat untuk masalah spesifik yang ingin Anda selesaikan.
Penting untuk memilih jenis algoritme yang tepat untuk masalah Anda, karena menggunakan jenis algoritme yang salah dapat menyebabkan kinerja yang buruk dan prediksi yang tidak akurat. Jika Anda tidak yakin algoritme mana yang akan digunakan, akan sangat membantu untuk mencoba algoritme regresi dan klasifikasi dan membandingkan kinerjanya pada kumpulan data Anda.
Saya harap artikel ini bermanfaat bagi Anda dalam mempelajari Regresi vs. Klasifikasi dalam Pembelajaran Mesin. Anda mungkin juga tertarik untuk mempelajari model Machine Learning teratas.