
Cara Membuat Pandas DataFrame [Dengan Contoh]
Diterbitkan: 2022-12-08Pelajari dasar-dasar bekerja dengan panda DataFrames: struktur data dasar di panda, pustaka manipulasi data yang andal.
Jika Anda ingin memulai analisis data dengan Python, panda adalah salah satu pustaka pertama yang harus Anda pelajari untuk digunakan. Dari mengimpor data dari berbagai sumber seperti file CSV dan database hingga menangani data yang hilang dan menganalisisnya untuk mendapatkan wawasan – panda memungkinkan, Anda melakukan semua hal di atas.
Untuk mulai menganalisis data dengan panda, Anda harus memahami struktur data fundamental dalam panda: data frames .
Dalam tutorial ini, Anda akan mempelajari dasar-dasar kerangka data panda dan metode umum untuk membuat kerangka data. Anda kemudian akan mempelajari cara memilih baris dan kolom dari kerangka data untuk mengambil subkumpulan data.
Untuk semua ini dan lebih banyak lagi, mari kita mulai.
Menginstal dan Mengimpor Panda
Karena panda adalah pustaka analisis data pihak ketiga, Anda harus menginstalnya terlebih dahulu. Direkomendasikan untuk menginstal paket eksternal di lingkungan virtual untuk proyek Anda.
Jika Anda menggunakan distribusi Anaconda dari Python, Anda dapat menggunakan conda untuk manajemen paket.
conda install pandasAnda juga dapat menginstal panda menggunakan pip:
pip install pandasPustaka panda membutuhkan NumPy sebagai ketergantungan. Jadi jika NumPy belum terinstal, NumPy juga akan terinstal selama proses instalasi.
Setelah menginstal panda, Anda dapat mengimpornya ke lingkungan kerja Anda. Secara umum, panda diimpor dengan alias pd :
import pandas as pdApa itu DataFrame di Pandas?

Struktur data fundamental dalam panda adalah kerangka data . Bingkai data adalah larik data dua dimensi dengan indeks berlabel dan kolom bernama . Setiap kolom dalam bingkai data yang disebut seri panda , berbagi indeks yang sama.
Berikut adalah contoh bingkai data yang akan kami buat dari awal selama beberapa menit ke depan. Kerangka data ini berisi data tentang berapa banyak yang dihabiskan enam siswa dalam empat minggu.

Nama-nama siswa adalah label baris. Dan kolom diberi nama 'Minggu1' hingga 'Minggu4'. Perhatikan bahwa semua kolom berbagi kumpulan label baris yang sama, juga disebut indeks .
Cara Membuat Bingkai Data Pandas
Ada beberapa cara untuk membuat bingkai data panda. Dalam tutorial ini, kita akan membahas metode berikut:
- Membuat bingkai data dari array NumPy
- Membuat bingkai data dari kamus Python
- Membuat bingkai data dengan membaca file CSV
Dari NumPy Array
Mari kita buat bingkai data dari larik NumPy.
Mari kita buat array data bentuk (6,4) dengan asumsi bahwa dalam minggu tertentu, setiap siswa menghabiskan antara $0 dan $100. Fungsi randint() dari modul random NumPy mengembalikan array bilangan bulat acak dalam interval tertentu, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Untuk membuat bingkai data panda, Anda bisa menggunakan konstruktor DataFrame dan meneruskan larik NumPy sebagai argumen data , seperti yang ditunjukkan:
students_df = pd.DataFrame(data=data) Sekarang kita dapat memanggil fungsi built-in type() untuk memeriksa tipe dari students_df . Kami melihat bahwa itu adalah objek DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 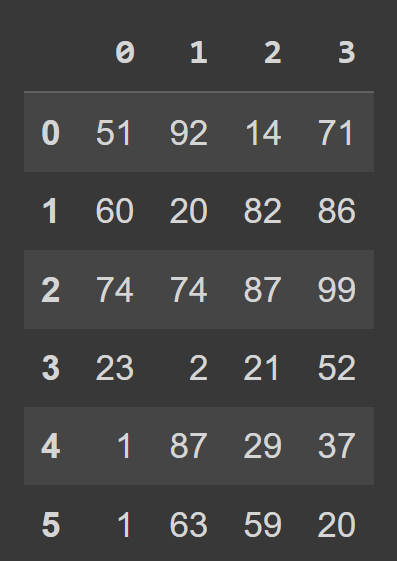
Kami melihat bahwa secara default, kami memiliki pengindeksan rentang yang dimulai dari 0 hingga numRows – 1, dan label kolom adalah 0, 1, 2, …, numCols -1. Namun, ini mengurangi keterbacaan. Ini akan membantu untuk menambahkan nama kolom deskriptif dan label baris ke bingkai data.
Mari buat dua daftar: satu untuk menyimpan nama siswa dan satu lagi untuk menyimpan label kolom.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Saat memanggil konstruktor DataFrame , Anda dapat menyetel index dan columns ke daftar label baris dan label kolom yang akan digunakan.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Kami sekarang memiliki bingkai data students_df dengan label baris dan kolom deskriptif.
print(students_df) 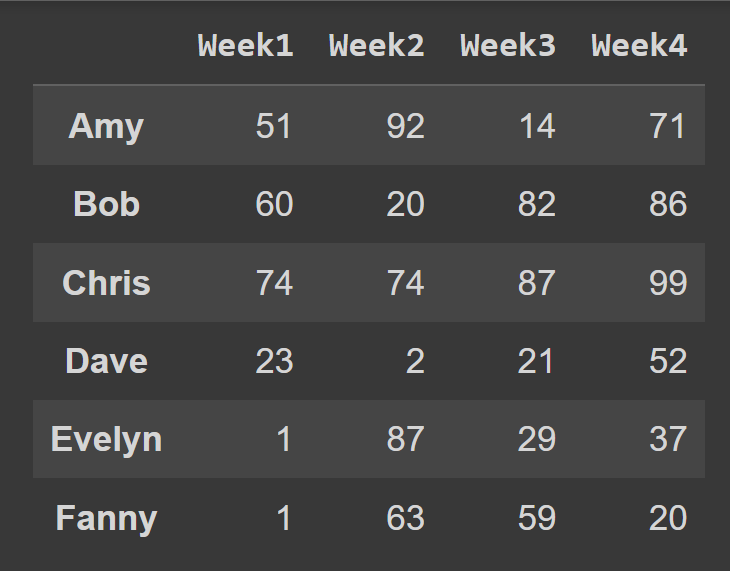
Untuk mendapatkan beberapa informasi dasar tentang bingkai data, seperti nilai yang hilang dan tipe data, Anda dapat memanggil metode info() pada objek bingkai data.
students_df.info() 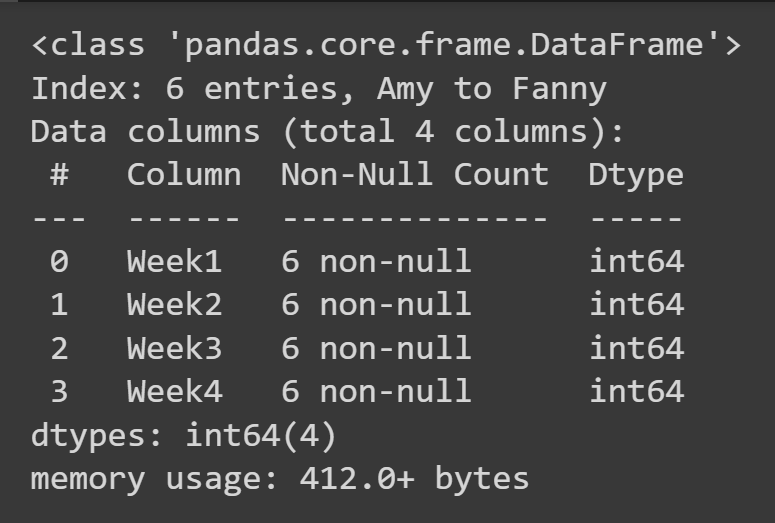
Dari Kamus Python
Anda juga dapat membuat bingkai data panda dari kamus Python.
Di sini, data_dict adalah kamus yang berisi data siswa:
- Nama-nama siswa adalah kuncinya.
- Setiap nilai adalah daftar berapa banyak yang dihabiskan setiap siswa dari minggu pertama hingga keempat.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Untuk membuat bingkai data dari kamus Python, gunakan from_dict , seperti yang ditunjukkan di bawah ini. Argumen pertama sesuai dengan kamus yang berisi data ( data_dict ). Secara default, kunci digunakan sebagai nama kolom bingkai data. Karena kami ingin menyetel kunci sebagai label baris , setel orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 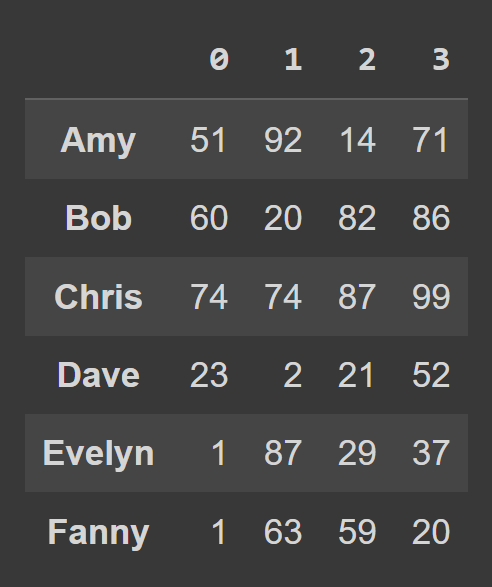
Untuk mengubah nama kolom menjadi nomor minggu, kami menetapkan kolom ke daftar cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 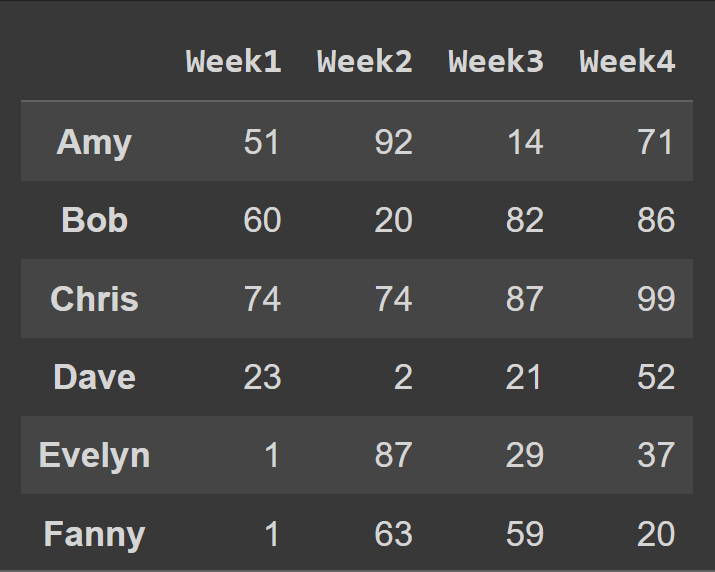
Baca dalam File CSV Ke dalam Pandas DataFrame
Misalkan data siswa tersedia file CSV. Anda dapat menggunakan fungsi read_csv() untuk membaca data dari file ke dalam bingkai data panda. pd.read_csv('file-path') adalah sintaks umum, di mana file-path adalah path ke file CSV. Kita dapat mengatur parameter names ke daftar nama kolom yang akan digunakan.
students_df = pd.read_csv('/content/students.csv',names=cols)Sekarang setelah kita mengetahui cara membuat bingkai data, mari pelajari cara memilih baris dan kolom.
Pilih Kolom dari Pandas DataFrame
Ada beberapa metode bawaan yang bisa Anda gunakan untuk memilih baris dan kolom dari bingkai data. Tutorial ini akan membahas cara paling umum untuk memilih kolom, baris, dan baris serta kolom dari bingkai data.
Memilih Satu Kolom
Untuk memilih satu kolom, Anda dapat menggunakan df_name[col_name] di mana col_name adalah string yang menunjukkan nama kolom.
Di sini, kami hanya memilih kolom 'Minggu1'.
week1_df = students_df['Week1'] print(week1_df) 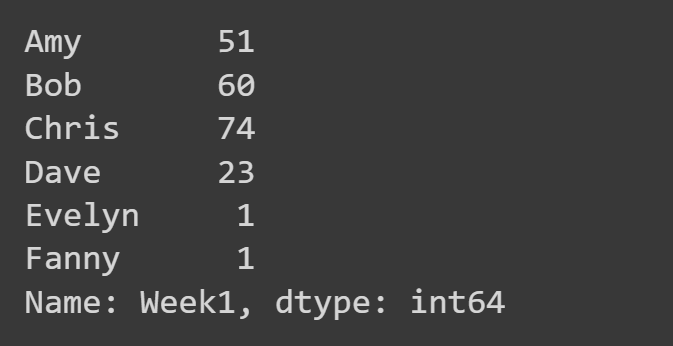
Memilih Beberapa Kolom
Untuk memilih beberapa kolom dari bingkai data, berikan daftar semua nama kolom untuk dipilih.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 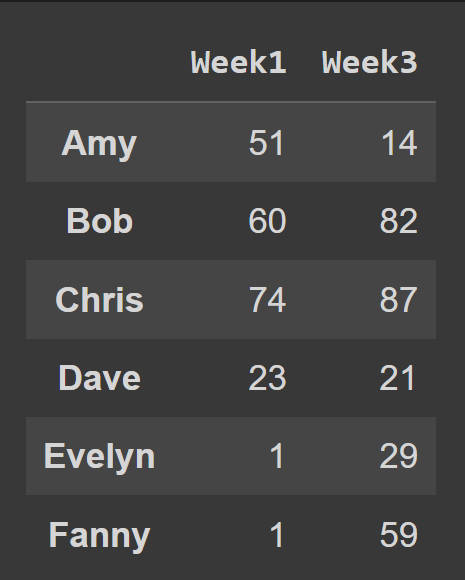
Selain metode ini, Anda juga dapat menggunakan metode iloc() dan loc() untuk memilih kolom. Kami akan memberi kode contoh nanti.
Pilih Baris dari Pandas DataFrame

Menggunakan Metode .iloc()
Untuk memilih baris menggunakan metode iloc() , berikan indeks yang sesuai dengan semua baris sebagai daftar.
Dalam contoh ini, kami memilih baris dengan indeks ganjil.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 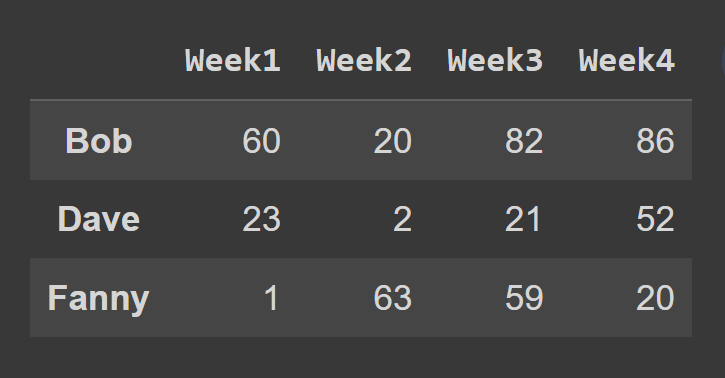
Selanjutnya, kami memilih subset dari bingkai data yang berisi baris pada indeks 0 hingga 2, titik akhir 3 dikecualikan secara default.
slice1 = students_df.iloc[0:3] print(slice1) 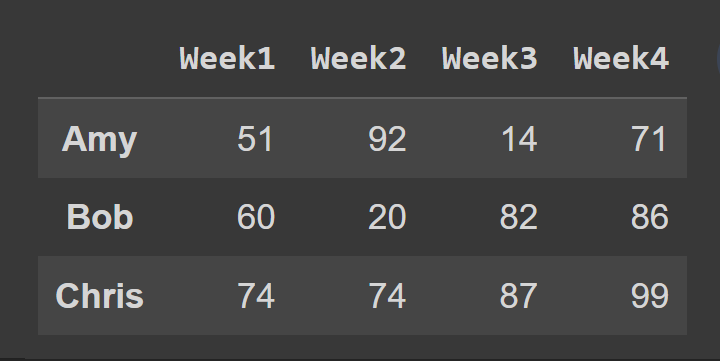
Menggunakan Metode .loc()
Untuk memilih baris bingkai data menggunakan metode loc() , Anda harus menentukan label yang sesuai dengan baris yang ingin Anda pilih.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 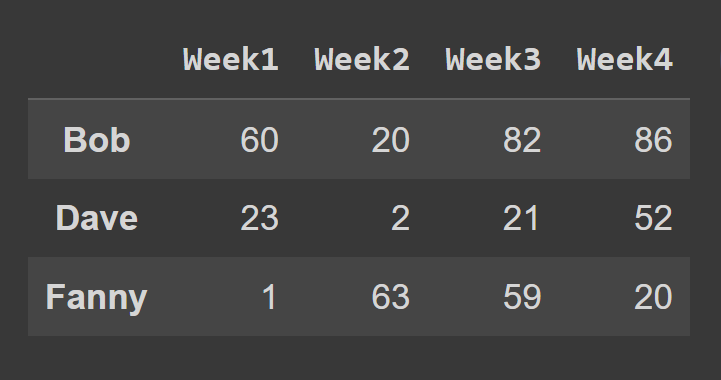
Jika baris bingkai data diindeks menggunakan rentang default 0, 1, 2, hingga
numRows-1, maka penggunaaniloc()danloc()keduanya setara.
Pilih Baris dan Kolom dari Pandas DataFrame
Sejauh ini, Anda telah mempelajari cara memilih baris atau kolom dari bingkai data panda. Namun, terkadang Anda perlu memilih subset dari baris dan kolom. Jadi bagaimana Anda melakukannya? Anda dapat menggunakan metode iloc() dan loc() yang telah kita bahas.
Misalnya, dalam cuplikan kode di bawah ini, kami memilih semua baris dan kolom pada indeks 2 dan 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 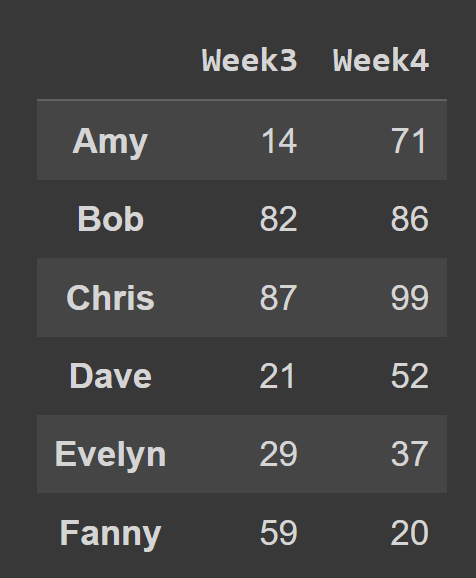
Menggunakan start:stop membuat irisan dari start up hingga tetapi tidak termasuk stop . Jadi, saat Anda mengabaikan nilai start dan stop , saat Anda mengabaikan nilai awal dan akhir, irisan dimulai dari awal—dan memanjang hingga akhir bingkai data—memilih semua baris.
Saat menggunakan metode loc() , Anda harus meneruskan label baris dan kolom yang ingin Anda pilih, seperti yang ditunjukkan:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 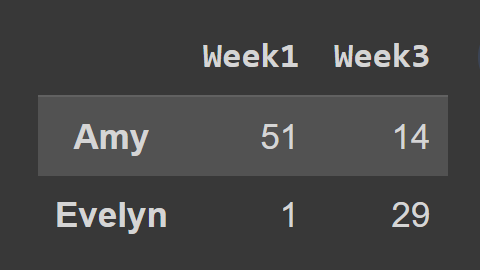
Di sini, kerangka data subset_df2 berisi catatan Amy dan Evelyn untuk Minggu1 dan Minggu3.
Kesimpulan
Berikut ulasan singkat tentang apa yang telah Anda pelajari dalam tutorial ini:
- Setelah menginstal panda, Anda dapat mengimpornya di bawah alias
pd. Untuk membuat objek bingkai data panda, Anda dapat menggunakanpd.DataFrame(data), di manadatamerujuk ke larik N-dimensi atau iterable yang berisi data. Anda dapat menentukan baris dan indeks, serta label kolom dengan menyetel parameter opsional indeks dan kolom. - Menggunakan
pd.read_csv(path-to-the-file)membaca konten file ke dalam bingkai data. - Anda dapat memanggil metode
info()pada objek bingkai data untuk mendapatkan informasi tentang kolom, jumlah nilai yang hilang, tipe data, dan ukuran bingkai data. - Untuk memilih satu kolom, gunakan
df_name[col_name], dan untuk memilih beberapa kolom, kolom tertentu,df_name[[col1,col2,...,coln]]. - Anda juga dapat memilih kolom dan baris menggunakan metode
loc()daniloc(). - Sementara metode
iloc()mengambil indeks (atau irisan indeks) dari baris dan kolom untuk dipilih, metodeloc()mengambil label baris dan kolom.
Anda dapat menemukan contoh yang digunakan dalam tutorial ini di notebook Colab ini.
Selanjutnya, lihat daftar buku catatan sains data kolaboratif ini.