
Apa itu Pengelompokan Failover? Bagaimana Cara Kerjanya + Solusi
Diterbitkan: 2023-09-22Perusahaan yang membutuhkan transaksi online tidak mampu menanggung kerusakan server. Akibatnya, bisnis-bisnis ini mencari cara untuk membuat prosedur failsafe yang menjaga data mereka tetap aman bahkan jika servernya rusak. Salah satu metode tersebut adalah pengelompokan failover.
Pengelompokan failover dapat diatur oleh solusi penyedia sistem nama domain terkelola (DNS); namun, memahami mekanisme dan fitur utamanya dapat membantu membatasi tantangan failover apa pun.
Apa itu pengelompokan failover?
Pengelompokan failover beroperasi pada sekelompok server komputer untuk memastikan ketersediaan tinggi (HA) atau ketersediaan berkelanjutan (CA) untuk aplikasi server. Teknologi ini memastikan bahwa jika satu server atau node gagal, node cluster lainnya siap mengambil beban kerja tanpa gangguan.
Pendekatan ini menjaga beban kerja server Anda tetap terukur dan tersedia. Banyak program server utama, seperti Microsoft Exchange , Microsoft SQL Server , dan Hyper-V , mengandalkan pengelompokan failover untuk melindungi dirinya sendiri.
Beberapa kluster failover menggunakan server fisik, sementara kluster lainnya menggunakan mesin virtual (VM) . Setiap orang memilih jenis cluster yang mereka butuhkan berdasarkan kebutuhan aplikasi server mereka.
Sebuah cluster terdiri dari dua atau lebih node yang bertukar data dan perangkat lunak untuk diproses melalui kabel fisik atau jaringan aman khusus. Beberapa jenis teknologi clustering dapat digunakan untuk penyeimbangan beban, penyimpanan, dan komputasi bersamaan atau paralel. Dalam beberapa kasus, klaster failover digabungkan dengan teknologi pengelompokan tambahan.
Fungsi utama kluster failover adalah menyediakan CA atau HA untuk aplikasi dan layanan. Klaster CA, juga dikenal sebagai klaster toleransi kegagalan (FT), memungkinkan pengguna akhir terus menggunakan aplikasi dan layanan meskipun server mengalami kegagalan. Anda mungkin melihat gangguan singkat dalam layanan yang disebabkan oleh cluster HA, namun sistem dapat pulih tanpa kehilangan data dan sedikit waktu henti.
Mengapa pengelompokan failover penting?
Dengan pengelompokan failover, Anda dapat memperbaiki node yang tidak aktif tanpa mematikan database Anda, menghindari kekhawatiran waktu henti sekaligus memperbaiki server yang rusak dengan cepat. Selanjutnya, jika terjadi kegagalan perangkat keras, teknik ini menghentikan database untuk melindungi node yang aktif.
Pengelompokan failover juga mengotomatiskan pemulihan data jika terjadi kegagalan. Hal ini mengurangi ketergantungan Anda pada kru teknologi informasi (TI) dan memungkinkan server Anda pulih dengan cepat. Ini juga memberikan ketersediaan klaster bahasa kueri terstruktur (SQL) yang sangat baik dengan waktu henti minimal. Fungsi failover otomatis dari pengelompokan failover mempertahankan fungsi database Anda, meskipun terjadi kerusakan perangkat keras.
Bagaimana cara kerja kluster failover?
Pengelompokan failover terdiri dari dua proses mendasar, HA dan CA, untuk aplikasi server.
Sementara klaster failover CA mencoba mencapai ketersediaan 100%, klaster HA berupaya mencapai 99,999%, yang umumnya dikenal sebagai lima sembilan. Total waktu henti ini tidak lebih dari 5,26 menit setiap tahun. Klaster CA memiliki ketersediaan yang lebih tinggi tetapi memerlukan lebih banyak perangkat keras untuk beroperasi, sehingga meningkatkan biaya keseluruhannya.
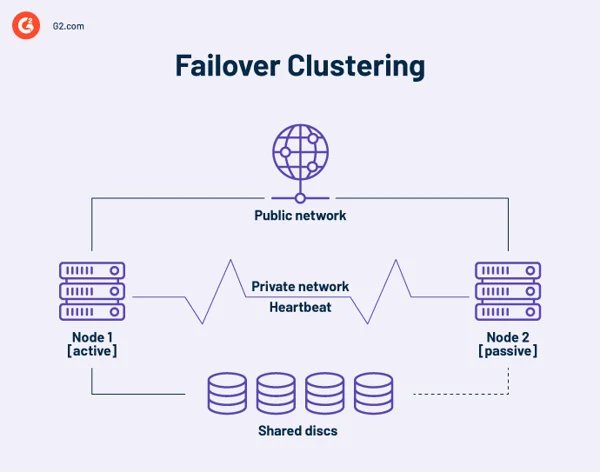
Kluster failover ketersediaan tinggi
Cluster ketersediaan tinggi adalah kumpulan komputer independen yang berbagi sumber daya dan data. Node kluster failover memiliki akses ke penyimpanan bersama. Tautan pemantauan juga disertakan dalam cluster ketersediaan tinggi untuk memeriksa detak jantung atau kesehatan server lain. Detak jantung adalah jaringan pribadi yang hanya digunakan bersama oleh node di cluster. Itu tidak dapat diakses dari luar.
Pada titik mana pun, setidaknya satu node dalam cluster aktif, dan setidaknya satu lagi tidak aktif atau pasif.
Dalam pengaturan dua node dasar, jika Node 1 gagal, Node 2 mengenali kegagalan tersebut melalui koneksi detak jantung dan mengkonfigurasi dirinya sendiri sebagai node aktif. Perangkat lunak pengelompokan pada setiap node menjamin klien terhubung ke node aktif.
Instalasi yang lebih besar mungkin menggunakan server khusus untuk mengelola cluster. Server manajemen cluster selalu mengirimkan sinyal detak jantung untuk mengidentifikasi node mana pun yang gagal dan, jika demikian, memberi tahu node lain untuk melakukan pekerjaan tersebut.
Beberapa alat perangkat lunak manajemen klaster menangani HA untuk VM dengan mengelompokkan mesin dan server ke dalam sebuah klaster. Jika sebuah host gagal, host lain akan melanjutkan VM.
Sebagai kemungkinan titik kegagalan tunggal, penyimpanan bersama mewakili sebuah risiko. Namun, menggabungkan susunan disk independen 6 dan 10 yang berlebihan – alias RAID 6 dan RAID 10 – dapat membantu mempertahankan layanan bahkan jika dua hard drive rusak.
Daya listrik mungkin menjadi titik kegagalan lainnya jika semua server terhubung ke jaringan yang sama. Menyediakan setiap node dengan catu daya tak terputus (UPS) sendiri akan menjaga mereka tetap terlindungi.
Kluster failover ketersediaan berkelanjutan
Berbeda dengan paradigma HA, cluster yang toleran terhadap kesalahan terdiri dari banyak komputer yang berbagi satu salinan sistem operasi (OS) komputer. Perintah perangkat lunak yang diberikan pada satu sistem juga dijalankan pada sistem lainnya.
CA menegaskan bahwa organisasi tersebut menggunakan peralatan komputer yang telah diformat dan UPS cadangan. CA memerlukan replika sistem fisik atau virtual yang dapat diakses secara konstan dan hampir sempurna yang menjalankan layanan. Model redundansi ini dikenal sebagai 2N.
Sistem CA dapat mengkompensasi berbagai macam kesalahan. Sistem yang toleran terhadap kesalahan dapat mengidentifikasi kerusakan pada:
- Sebuah harddisk
- Unit pemrosesan di komputer
- Subsistem untuk input dan output (I/O)
- Sumber listrik
- Sebuah komponen jaringan
Titik kegagalan dapat segera ditemukan, dan komponen atau metode cadangan dapat segera dilakukan tanpa mengganggu layanan berikutnya.
Perangkat lunak clustering dapat menghubungkan dua atau lebih server untuk berperilaku sebagai server virtual tunggal atau membangun berbagai konfigurasi cluster failover CA alternatif. Misalnya, jika salah satu server virtual gagal, server lainnya akan merespons dengan menghapus sementara server virtual dari kuorum cluster. Server virtual kemudian mendistribusikan kembali beban ke server lain hingga server yang mogok siap untuk dimulai ulang.
Server perangkat keras ganda dengan semua komponen fisik direplikasi merupakan alternatif untuk kluster failover CA. Mereka menghitung secara terpisah dan bersamaan pada berbagai platform perangkat keras dan melakukan sinkronisasi menggunakan node khusus yang memantau hasil dari kedua server fisik. Meskipun solusi ini memberikan perlindungan, namun mungkin lebih mahal.
Fitur pengelompokan failover
Banyak organisasi menggunakan pengelompokan failover untuk aplikasi yang sangat penting. Hal ini karena karakteristik berikut membuat pengelompokan failover menjadi teknik yang signifikan.
- Skalabilitas : Karena pengelompokan failover didasarkan pada sekelompok klaster yang berkolaborasi untuk mencegah kegagalan server, Anda dapat dengan mudah dan mudah melakukan penskalaan sesuai kebutuhan dengan menambahkan klaster baru.
- Stabilitas: Server cluster terhubung melalui kabel. Cluster yang tersisa masih dapat menawarkan layanan meskipun satu atau lebih gagal karena faktor eksternal.
- Pemantauan real-time: Node cluster terus dipantau untuk memastikan node berfungsi dengan baik. Saat sebuah klaster dimulai ulang atau ditransfer ke node lain.
- Volume bersama kluster (CSV): Fitur ini menyediakan namespace yang konsisten dan terdistribusi untuk digunakan node saat bekerja dengan penyimpanan bersama. Sangat penting untuk menjaga aplikasi server tetap berjalan tanpa gangguan dari awal hingga akhir.
Jenis cluster failover
Kemajuan signifikan dalam pengelompokan failover telah terjadi dalam dekade terakhir, dengan banyak organisasi kini menawarkan solusi pengelompokan versi mereka sendiri. Beberapa layanan cluster yang paling umum dirinci di sini.

Kluster failover VMware
VMware menyediakan berbagai teknologi virtualisasi untuk cluster VM. Arsitektur CA vSphere vMotion secara tepat menduplikasi mesin virtual VMware dan jaringannya antara jaringan pusat data fisik.
VMware vSphere HA, produk kedua, menyediakan HA untuk VM dengan mengelompokkannya dan hostnya ke dalam sebuah cluster untuk failover otomatis. Selain itu, program ini tidak bergantung pada komponen eksternal seperti DNS, sehingga mengurangi kemungkinan titik kegagalan.
Kluster failover server Windows
Metode cluster failover server Windows (WSFC) mendorong pembuatan server failover Hyper-V. Antara tahun 2016 dan 2019, strategi ini semakin populer di kalangan pengguna Microsoft Windows. WSFC memungkinkan pemantauan cluster dan menawarkan mekanisme failover yang diperlukan secara otomatis. Jika terjadi kehilangan server, WFSC memindahkan cluster ke node terpisah atau mencoba memulai ulang cluster tersebut. Selain itu, teknologi CSV-nya menyediakan namespace terdistribusi yang memungkinkan beberapa node berbagi memori.
server SQL
Produk Microsoft ini, yang diperkenalkan dengan SQL Server 2017, memiliki solusi HA tangguh yang menggunakan teknologi WSFC. Komponen server SQL dianggap sebagai sumber daya cluster WSFC dalam konteks ini. Mereka selanjutnya terintegrasi dengan sumber daya lain yang bergantung pada WSFC. Akibatnya, WSFC memiliki wewenang untuk mengidentifikasi dan mengkomunikasikan perintah untuk memulai ulang instance server SQL atau untuk memindahkan instance seperti itu ke node baru.
Linux Topi Merah
Selain Microsoft, vendor sistem operasi lain hadir dengan solusi cluster failover mereka sendiri. Misalnya, penggemar Red Hat Enterprise Linux (RHEL) dapat menggunakan ekstensi HA dan Red Hat Global File System (GFS/GFS2) untuk membuat cluster failover HA. Klaster bentangan klaster tunggal yang mencakup banyak lokasi dan klaster multi-lokasi yang tahan bencana didukung. Replikasi penyimpanan data jaringan area penyimpanan (SAN) biasanya digunakan dalam cluster multi-situs.
Penerapan pengelompokan failover
Mekanisme yang kuat ini memfasilitasi aplikasi real-time berikut.
Ketersediaan aplikasi yang sangat penting.
Komputer pemrosesan transaksi online (OLTP) harus memiliki sistem yang tahan kesalahan. OLTP yang memerlukan ketersediaan lengkap digunakan untuk sistem reservasi maskapai penerbangan, perdagangan saham elektronik, dan ATM perbankan.
Banyak industri, seperti manufaktur, perkapalan, dan ritel, menggunakan cluster CA atau komputer tahan kegagalan untuk aplikasi yang sangat penting. E-commerce, manajemen pesanan , dan sistem jam waktu staf dihitung sebagai contoh.
Kluster ketersediaan tinggi sering kali dapat diterima untuk mengelompokkan aplikasi dan layanan yang hanya memerlukan waktu aktif lima-sembilan.
Bantuan bencana
Pemulihan bencana juga mendapat manfaat dari pengelompokan failover. Sangat disarankan agar server failover dihosting di lokasi terpencil karena bencana seperti kebakaran atau banjir menghancurkan semua perangkat keras dan perangkat lunak fisik.
Replika Penyimpanan, sebuah teknologi yang menduplikasi volume antar server untuk pemulihan bencana , disertakan dalam Windows Server 2016 dan 2019. Stretch failover adalah fitur teknologi yang memungkinkan kluster failover menjangkau dua lokasi.
Organisasi dapat mereplikasi data melalui berbagai pusat dengan memperluas cluster failover. Jika tragedi terjadi di satu lokasi, semua data disimpan di server failover di lokasi lain.
Replikasi database
Menurut Microsoft, WSFC pertama kali diluncurkan pada Windows Server 2016 untuk melindungi layanan "penting", seperti database server SQL dan server komunikasi Microsoft Exchange.
Untuk replikasi database , vendor lain menyediakan teknologi failover cluster. Misalnya, Cluster MySQL memiliki metode detak jantung yang memungkinkan deteksi kegagalan dengan cepat ke node lain dalam cluster, seringkali dalam waktu kurang dari satu detik, tanpa gangguan layanan pada klien.
Basis data dapat direplikasi ke situs yang jauh menggunakan kemampuan replikasi geografis.
Manfaat cluster failover
Ide dari cluster failover adalah untuk memastikan bahwa pengguna mengalami gangguan minimal dalam layanan. Namun, manfaat tambahan lainnya dari pengelompokan failover dibahas di bawah.
- Peningkatan ketersediaan sumber daya: Jika satu server cerdas gagal, server lain dalam cluster akan menanggung bebannya. Ini menghemat waktu dan informasi penting.
- Alokasi sumber daya strategis: Anda dapat mendistribusikan proyek antar node dengan cara apa pun yang Anda pilih. Hal ini meminimalkan overhead karena tidak semua komputer diharuskan menjalankan semua proyek secara bersamaan, sehingga memberi Anda cara untuk menggunakan sumber daya dengan lebih bebas.
- Peningkatan kekuatan pemrosesan: Lebih banyak mesin, lebih banyak kekuatan.
- Skalabilitas yang lebih besar: Seiring dengan berkembangnya basis pengguna dan kompleksitas laporan Anda, sumber daya Anda juga meningkat.
- Manajemen yang disederhanakan: Pengelompokan membuat penanganan sistem yang signifikan atau cepat berubah menjadi lebih mudah.
Keterbatasan pengelompokan failover
Meskipun pengelompokan failover penting, hal ini juga menghadapi keterbatasan berikut.
- Konfigurasi kompleks: Konfigurasi pengelompokan failover untuk Windows mengharuskan Anda menangani banyak jaringan dan kartu jaringan sekaligus. Akibatnya, menerapkan metode ini menjadi sulit, terutama bagi pemula.
- Integrasi alat: Pengelompokan failover Windows dan Hyper-V harus terintegrasi lebih erat. Anda harus menyesuaikannya masing-masing untuk menyelesaikan pengelompokan failover dengan sukses.
- Antarmuka web: Tidak ada antarmuka web untuk menyesuaikan parameter cluster. Untuk mengakses fitur manajer cluster, Anda harus login secara manual ke desktop jarak jauh.
Solusi pengelompokan failover: penyedia DNS terkelola
Dengan bekerja sama dengan sistem pengelompokan failover, penyedia DNS terkelola mengalihkan lalu lintas ke server atau pusat data alternatif selama peristiwa failover, memastikan akses tanpa gangguan ke layanan Anda sehingga Anda mencapai ketersediaan tinggi dan meminimalkan waktu henti.
Lima penyedia DNS terkelola teratas:
- DNS Cloudflare
- Azure DNS
- Infoblox NIOS
- PERANGKAT WPMU
- Manajer DNS
* Di atas adalah lima perangkat lunak penyedia DNS terkelola terkemuka dari Laporan Grid Musim Gugur 2023 G2.

Modernisasi keandalan
Pengelompokan failover telah muncul sebagai pilihan yang andal dan penting untuk ketersediaan tinggi dan toleransi kesalahan dalam infrastruktur TI saat ini. Ini menyediakan operasi berkelanjutan meskipun terjadi kegagalan perangkat keras atau pemeliharaan terjadwal dengan secara otomatis menyebarkan beban kerja dan sumber daya ke berbagai node jaringan. Teknologi ini memberi Anda cara lain untuk menangani aspek terpenting bisnis Anda – menjadikan pengalaman setiap pelanggan aman dan menyenangkan.
Memperkuat ketahanan sistem Anda juga tidak ada salahnya!
Mulailah dengan panduan keamanan DNS untuk strategi sistem yang tangguh.