
Qui est responsable de la qualité des données ? Matrice de responsabilité pour les équipes d'analyse
Publié: 2022-06-11Étant donné que des données de mauvaise qualité peuvent rendre toute action ultérieure inutile (telle que le calcul de l'attribution, l'envoi d'offres aux services publicitaires ou la création de rapports), garantir la qualité des données reste le plus grand défi de l'analyse numérique. Il est courant de dire que les analystes sont responsables de tous les problèmes liés aux données. Mais est-ce vrai ?
Qui est responsable de la qualité des données dans une entreprise ? Contrairement à la croyance populaire, il n'y a pas que les analystes. Par exemple, les spécialistes du marketing travaillent avec des balises UTM, les ingénieurs appliquent des codes de suivi, etc. Il n'est donc pas surprenant que le chaos se produise lorsque vous travaillez avec des données : chaque employé a de nombreuses tâches, et il n'est pas clair qui fait quoi, qui est responsable de quoi, et à qui demander le résultat.
Dans cet article, nous essayons de comprendre qui est responsable de la qualité des données à chaque étape et comment la gérer.
Table des matières
- Flux de travail de données
- 1. Collecte des données primaires
- 2. Importation des données dans l'entrepôt de données
- 3. Préparation de la vue SQL
- 4. Préparer des données prêtes pour l'entreprise
- 5. Préparation du magasin de données
- 6. Visualiser les données
- Points clés à retenir
- Liens utiles
Flux de travail de données
Même au sein d'une entreprise, le monde des données peut être rempli de divergences et de malentendus. Pour donner aux utilisateurs professionnels des données de qualité et éviter de manquer des données précieuses, vous devez planifier la collecte de toutes les données marketing nécessaires. En préparant le workflow de données, vous démontrez comment les données sont liées pour les collègues de tous les départements afin qu'il devienne facile de relier les points. Cependant, ce n'est que la première étape. Voyons quelles sont les autres étapes de la préparation des données pour les rapports et les tableaux de bord :
- Configurer la collecte de données primaires.
- Collectez des données brutes dans un stockage de données ou une base de données.
- Transformez les données brutes en données prêtes à l'emploi, avec un balisage, nettoyées et dans une structure compréhensible pour l'entreprise.
- Préparez un magasin de données - une structure plate qui sert de source de données pour visualiser les données.
- Visualisez les données du tableau de bord.
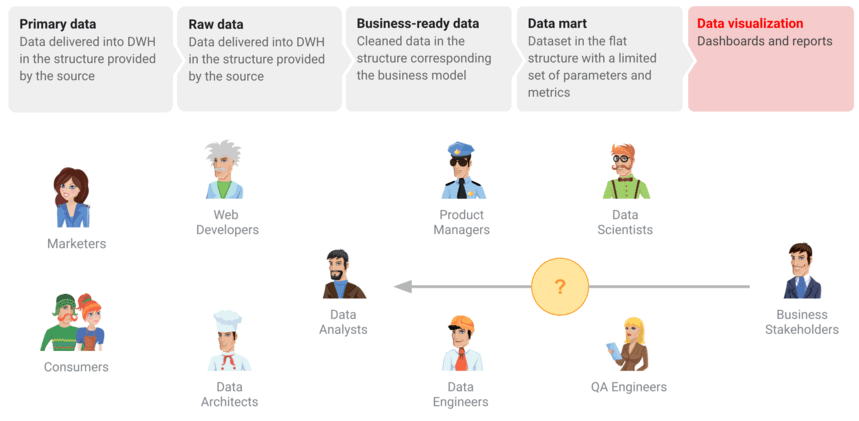
Pourtant, quelle que soit la préparation, les décideurs sont souvent confrontés à un rapport ou à un tableau de bord contenant des données de mauvaise qualité. Et la première chose qu'ils font est de se tourner vers l'analyste avec la question : pourquoi y a-t-il un écart ? ou Les données sont-elles pertinentes ici ?
Cependant, la réalité est que différents spécialistes sont impliqués dans ces processus : les ingénieurs de données sont engagés dans la mise en place du système d'analyse, les spécialistes du marketing ajoutent des balises UTM, les utilisateurs saisissent des données. Voyons en détail quelles étapes vous devez franchir et comment elles doivent être mises en œuvre pour fournir aux utilisateurs des données de haute qualité.
Nos clients
grandir 22 % plus rapide
Développez-vous plus rapidement en mesurant ce qui fonctionne le mieux dans votre marketing
Analysez votre efficacité marketing, trouvez les zones de croissance, augmentez le ROI
Obtenir une démo1. Collecte des données primaires
Bien que cette étape semble être la plus simple, il existe plusieurs obstacles cachés. Tout d'abord, vous devez planifier la collecte de toutes les données de toutes les sources, en tenant compte de tous les points de contact avec les clients. Parfois, cette étape de planification est ignorée, mais cela est déraisonnable et risqué. Adopter une approche non structurée conduit à obtenir des données incomplètes ou incorrectes.
Le principal défi est que vous devez collecter des données fragmentées à partir de différentes plateformes et services publicitaires avec lesquels vous travaillez. Étant donné que le traitement de tableaux de données massifs dans les plus brefs délais est compliqué et gourmand en ressources, voyons quels goulots d'étranglement possibles peuvent apparaître :
- Toutes les pages n'ont pas de conteneur GTM installé et, par conséquent, les données ne sont pas envoyées à Google Analytics.
- Un nouveau compte sur une plate-forme publicitaire est créé, mais les analystes ne sont pas informés et aucune donnée n'est collectée à partir de celui-ci.
- Une API ne prend pas en charge les paramètres dynamiques dans les balises UTM et ne les collecte ni ne les transfère.
- La carte connectée au projet Google Cloud n'a pas suffisamment de fonds ou de crédit.
- Validation incorrecte des données saisies par un utilisateur.
Au cours de cette étape, parmi tous les autres défis, vous devez envisager de contrôler l'accès aux données. Pour cela, nous vous recommandons d'utiliser la matrice RACI classique qui définit les rôles des processus et met l'accent sur qui fait, contrôle, gère et est responsable de quoi. Voici les rôles possibles :
- R (responsable) - quelqu'un qui est responsable et qui est l'exécuteur d'un processus particulier
- C (Consulté) — une personne qui consulte et fournit les données nécessaires pour mettre en œuvre le processus
- A (responsable ou approbateur) — quelqu'un qui est responsable du résultat du travail
- I (Informé) - une personne qui doit être informée de l'avancement des travaux
Selon la matrice RACI, les rôles et responsabilités pour la collecte de données ressemblent à ceci :

2. Importation des données dans l'entrepôt de données
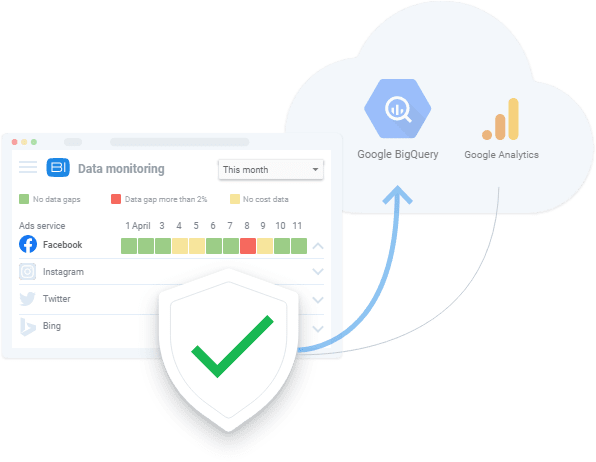
L'étape suivante consiste à décider où stocker toutes les données obtenues. Si vous souhaitez avoir un contrôle total sur vos données brutes sans les modifier, nous vous recommandons d'utiliser un stockage unique avec importation automatisée des données. Étant donné que l'utilisation de vos propres serveurs pour stocker chaque octet de données coûtera une fortune, nous vous recommandons d'utiliser des solutions cloud qui économisent vos ressources et donnent accès aux données partout.
La meilleure option pour cette tâche est Google BigQuery, car il prend en compte les besoins des spécialistes du marketing et peut être utilisé pour stocker les données brutes des sites Web, des systèmes CRM, des plateformes publicitaires, etc. Aujourd'hui, il existe des tonnes de solutions logicielles de marketing. Nous recommandons OWOX BI, qui collecte automatiquement les données dans un entrepôt de données (ou lac de données) à partir de différents services et sites Web.
Voyons quelles erreurs classiques peuvent se produire lors de la collecte de données brutes :
- L'API du service de publicité a changé. En conséquence, le format des données a également changé.
- L'API de service externe n'est pas disponible. L'intervenant voit certains chiffres dans son compte personnel, mais l'API du même service publicitaire donne d'autres données. Ces données ne correspondent pas car, comme dans tout système distribué, la source de données de l'API du service publicitaire est différente de la source de données du portail Web.
- Les données de l'interface Web et de l'API du service externe sont différentes. Les formats de documentation et de traitement des données peuvent être différents. Par exemple, une erreur intéressante dans l'un des services de publicité populaires est que les dépenses sont nulles à la fois lorsqu'elles n'existent pas et lorsqu'elles sont en fait nulles. Tous les ingénieurs et analystes de données savent que zéro et Null sont des valeurs différentes et sont traités différemment. Dans un cas, ces dépenses peuvent apparaître et doivent être redemandées, et zéro signifie qu'elles ne sont vraiment pas là et sont comptées comme zéro.
- L'API d'un service externe fournit des données incorrectes.
Selon la matrice, dans ce processus, le spécialiste du marketing est un consultant et une source de connaissances : par exemple, des connaissances sur les comptes à partir desquels vous devez télécharger des données, les balises UTM et le balisage sur les campagnes publicitaires.

Il y a aussi des développeurs qui veulent savoir quels changements arriveraient aux conteneurs si Google Tag Manager était utilisé, car ils sont responsables de la vitesse de téléchargement du site Web.
À ce stade, les ingénieurs de données jouent déjà le rôle responsable car ils configurent les pipelines de données. Et les analystes sont responsables du résultat du travail. Même si un employé remplit ces fonctions, il y aura en fait deux rôles. Ainsi, si l'entreprise ne compte qu'un seul analyste, nous recommandons tout de même d'implémenter la matrice par rôles. Ensuite, avec la croissance de l'entreprise, vous aurez une description de poste pour un nouveau collègue, et il sera clair quelles sont les responsabilités pour un rôle spécifique.
La partie prenante à ce stade souhaite savoir quelles données sont disponibles et quels sont les problèmes de qualité, car elle identifie les priorités et les ressources destinées à la collecte des données. Par exemple, la fonctionnalité OWOX BI Data Monitoring est largement appliquée par nos clients.
3. Préparation de la vue SQL
La préparation des données est la prochaine étape. C'est ce qu'on appelle souvent la préparation du magasin de données - il s'agit d'une structure plate contenant les paramètres et les métriques qui seront présentés sur le tableau de bord. Un analyste dont les outils, le budget et le temps sont limités saute souvent l'étape de préparation des données commerciales et prépare immédiatement un magasin de données. Cela ressemble à des données brutes collectées dans un entrepôt de données. Ensuite, il y a un million de requêtes SQL différentes ainsi que des scripts Python et R - et ce gâchis se traduira par quelque chose sur le tableau de bord.
Si vous continuez à sauter la préparation de données prêtes pour l'entreprise, cela entraînera des erreurs répétées qui devront être corrigées dans chacune des sources. D'autres choses qui pourraient mal tourner incluent:
- Erreurs régulières dans les données primaires
- La logique métier est dupliquée dans toutes les requêtes SQL
- Beaucoup de temps nécessaire pour trouver les causes des écarts de données
- Le temps nécessaire pour affiner les datamarts existants étant comparable au temps nécessaire pour réécrire une requête
- La logique du rapport est incompréhensible pour le client
L'exemple le plus simple et le plus courant d'erreur est la définition d'un nouvel utilisateur et d'un utilisateur renvoyé . La plupart des entreprises ne font pas cette distinction de la même manière que Google Analytics. Par conséquent, la logique des définitions de type d'utilisateur est souvent dupliquée dans différents rapports. Les erreurs fréquentes incluent également une logique de rapport incompréhensible. La première chose que le client professionnel demandera en consultant le rapport est de savoir comment il a été construit, sur quelles hypothèses il était basé, pourquoi les données ont été utilisées, etc. Par conséquent, la préparation des données d'entreprise est une étape à ne pas manquer. Construire un datamart à partir de données brutes, c'est comme ne pas laver les légumes et les fruits avant de les manger.

Si nous attribuons des responsabilités selon la matrice, alors pour la préparation des données, nous obtiendrons ceci :

4. Préparer des données prêtes pour l'entreprise
Les données prêtes pour l'entreprise sont un ensemble de données final nettoyé qui correspond au modèle commercial. Ce sont des données prêtes à l'emploi qui peuvent être envoyées à n'importe quel service de visualisation de données (Power BI, Tableau, Google Data Studio, etc.).
Naturellement, différentes entreprises fonctionnent avec différents modèles. Par exemple, les définitions d'"utilisateurs", "utilisateurs B2B", "transactions", "prospects", etc. signifieront différentes choses pour différentes entreprises. Ces objets métier répondent en fait à la question de savoir comment une entreprise pense son modèle économique en termes de données. Il s'agit d'une description de l'activité principale et non de la structure des événements dans Google Analytics.
Le modèle de données permet à tous les employés de se synchroniser et d'avoir une compréhension générale de la façon dont les données sont utilisées et de ce qu'on en comprend. Par conséquent, la conversion des données brutes en données prêtes pour l'entreprise est une étape importante qui ne peut être ignorée.
Qu'est-ce qui pourrait mal tourner à ce stade :
- Pas clair quel modèle de données l'entreprise a/utilise
- Difficile de préparer et de maintenir des données simulées
- Difficile de contrôler les changements dans la logique de transformation
Ici, vous devez décider quel modèle de données choisir et comment contrôler les changements dans la logique de transformation des données. En conséquence, voici les rôles des participants au processus de changement :

L'acteur n'est plus seulement informé mais devient consultant. Ils prennent des décisions comme ce qui doit être compris comme un nouvel utilisateur ou un ancien utilisateur. La tâche de l'analyste à ce stade est d'impliquer autant que possible les parties prenantes dans la prise de ces décisions. Sinon, la meilleure chose qui puisse arriver est qu'on demande à l'analyste de refaire le rapport.
D'après notre expérience, certaines entreprises ne préparent toujours pas de données prêtes à l'emploi et ne créent pas de rapports à partir de données brutes. Le principal problème de cette approche est le débogage et la réécriture sans fin des requêtes SQL. À long terme, il est moins cher et plus facile de travailler avec des données préparées au lieu de parcourir des données brutes en faisant les mêmes choses encore et encore.
OWOX BI collecte automatiquement les données brutes de différentes sources et les convertit dans un format convivial pour les rapports. En conséquence, vous recevez des ensembles de données prêts à l'emploi qui sont automatiquement transformés dans la structure souhaitée, en tenant compte des nuances importantes pour les spécialistes du marketing. Vous n'aurez pas à passer du temps à développer et à prendre en charge des transformations complexes, à vous plonger dans la structure des données et à passer des heures à rechercher les causes des écarts.

Réservez une démo gratuite pour voir comment OWOX BI aide à préparer les données d'entreprise et comment vous pouvez bénéficier d'une gestion des données entièrement automatisée aujourd'hui.
5. Préparation du magasin de données
La prochaine étape est la préparation du magasin de données. En termes simples, il s'agit d'un tableau préparé contenant les données exactes nécessaires à certains utilisateurs d'un service particulier, ce qui facilite grandement son application.
Pourquoi les analystes ont-ils besoin d'un magasin de données et pourquoi ne devriez-vous pas sauter cette étape ? Les spécialistes du marketing et autres employés sans compétences analytiques ont du mal à travailler avec des données brutes. La tâche de l'analyste est de fournir à tous les employés un accès aux données sous la forme la plus pratique afin qu'ils n'aient pas à écrire des requêtes SQL complexes à chaque fois.
Un magasin de données aide à résoudre ce problème. En effet, avec un remplissage compétent, il inclura exactement la tranche de données nécessaire au travail d'un certain département. Et les collègues sauront exactement comment utiliser une telle base de données et comprendront le contexte des paramètres et des métriques qui y sont présentés.
Les principaux cas dans lesquels quelque chose peut mal se passer lors de la préparation du datamart sont :
- La logique de fusion des données est incompréhensible. Par exemple, il peut y avoir des données provenant d'une application mobile et d'un site Web, et vous devez décider comment les fusionner et par quelles clés, ou décider comment fusionner des campagnes publicitaires avec des activités dans une application mobile. Il y a beaucoup de questions. En prenant ces décisions lors de la préparation des données d'entreprise, nous les prenons une seule fois et leur valeur est supérieure à ces décisions prises ad hoc pour un rapport spécifique ici et maintenant. De telles décisions ad hoc doivent être prises à plusieurs reprises.
- Une requête SQL ne s'exécute pas en raison de limitations techniques de l'entrepôt de données. La préparation des données d'entreprise est un moyen de nettoyer les données et de les intégrer dans une structure simulée qui rendra le traitement et l'accélération des requêtes moins coûteux.
- Il n'est pas clair comment vérifier la qualité des données .
Voyons qui est responsable de quoi à ce stade selon la matrice :

Il est évident que la préparation des données relève de la responsabilité des analystes de données ainsi que des parties prenantes et des ingénieurs de données, qui sont des consultants dans le processus. Notez que les analystes OWOX BI peuvent gérer cette tâche pour vous. Nous pouvons collecter et fusionner des données, les modéliser pour votre modèle économique et préparer un data mart accompagné d'instructions détaillées avec une description de la logique de construction, vous permettant d'apporter des modifications de votre côté si nécessaire (par exemple, ajouter de nouveaux champs).
6. Visualiser les données
La présentation visuelle des données dans des rapports et des tableaux de bord est la dernière étape pour laquelle tout a réellement commencé. De toute évidence, les données doivent être présentées de manière à la fois informative et conviviale. Sans oublier que les visualisations automatisées et correctement configurées réduisent considérablement le temps nécessaire pour trouver les zones à risque, les problèmes et les possibilités de croissance.
Si vous avez préparé des données prêtes à l'emploi et un magasin de données, vous n'aurez aucune difficulté avec les visualisations. Cependant, des erreurs peuvent également apparaître telles que :
- Données non pertinentes dans le magasin de données. Si une entreprise n'est pas sûre de la qualité des données, même si les données sont de haute qualité, la première étape consiste pour le client professionnel à demander à l'analyste de tout revérifier. C'est inefficace. Il est clair que l'entreprise veut être protégée des erreurs et ne pas se précipiter sur les conclusions. Par conséquent, la haute qualité des données est une garantie que quelqu'un les utilisera plus tard.
- Choisir une mauvaise méthode de visualisation des données.
- Ne pas expliquer correctement au client la logique des calculs de métriques et de paramètres. Souvent, pour un client professionnel qui ne vit pas dans SQL et les métriques pour interpréter correctement les données, il a besoin de voir ce que signifie chaque métrique dans le contexte du rapport, comment il est calculé et pourquoi. Les analystes ne doivent pas oublier que toute personne qui utilise le rapport doit avoir accès à une explication de ce qui se cache derrière le rapport, quelles hypothèses étaient au cœur du rapport, etc.
Selon la matrice RACI, l'analyste a déjà un double rôle — approbateur et responsable . La partie prenante est ici un consultant , et il est fort probable qu'elle ait répondu à l'avance à la question des décisions qu'elle envisage de prendre et des hypothèses qu'elle souhaite tester. Ces hypothèses forment la base de la conception de la visualisation avec laquelle l'analyste travaille.

Points clés à retenir
La matrice RACI n'est pas une réponse à toutes les questions possibles sur l'utilisation des données, mais elle peut certainement faciliter la mise en œuvre et l'application du flux de données dans votre entreprise.
Étant donné que des personnes occupant différents rôles sont impliquées à différentes étapes du flux de données, il est faux de supposer que l'analyste est seul responsable de la qualité des données. La qualité des données relève également de la responsabilité de tous les collègues impliqués dans le balisage, la livraison, la préparation ou les décisions de gestion des données.
Toutes les données sont toujours de mauvaise qualité et il est impossible de se débarrasser définitivement des écarts de données, de rendre les données cohérentes et de les débarrasser du bruit et des doublons. Cela se produit toujours, en particulier dans une réalité de données aussi rapide et dynamique que le marketing. Cependant, vous pouvez identifier ces problèmes de manière proactive et vous fixer un objectif pour faire connaître la qualité de vos données. Par exemple, vous pouvez obtenir des réponses à des questions telles que : Quand les données ont-elles été mises à jour ? Dans quelle granularité les données sont-elles disponibles ? Quelles erreurs dans les données connaissons-nous ? et avec quelles mesures pouvons-nous travailler ?
Pour ceux qui souhaitent contribuer à l'amélioration de la qualité des données de leur entreprise, nous recommandons trois étapes simples :
- Créez un schéma de flux de données. Par exemple, utilisez Miro et esquissez comment votre entreprise utilise les données. Vous serez surpris du nombre d'opinions différentes sur ce schéma au sein d'une même entreprise.
- Élaborez une matrice des responsabilités et convenez de qui est responsable de quoi, au moins sur papier.
- Décrire le modèle de données métier.
Ayant de nombreuses années d'expertise, l'équipe OWOX BI sait comment répartir les responsabilités et ce dont les analystes ont besoin. Sur la base de ces connaissances, nous avons préparé un modèle de matrice d'attribution des responsabilités pour les équipes d'analystes.
Obtenir la matrice
De plus, l'équipe OWOX BI peut vous aider à configurer et à automatiser toutes les étapes de données décrites dans cet article. Si vous avez besoin d'aide pour l'une de ces tâches ou si vous souhaitez auditer votre système d'analyse et de qualité des données, réservez une démonstration.
Liens utiles
- Dark Data : pourquoi ce que vous ne savez pas est important par David J. Hand
- Le signal et le bruit : pourquoi tant de prédictions échouent, mais certaines échouent par Nate Silver
- Prévisiblement irrationnel par le Dr Dan Ariely
- Le singe irrationnel : pourquoi nous tombons dans le piège de la désinformation, de la théorie du complot et de la propagande par David Robert Grimes
- Une expérience de « Data Ecosystem » par Antriksh Goel