
Comment synchroniser votre base de données Oracle sur site avec AWS
Publié: 2023-01-11En observant le développement de logiciels d'entreprise depuis deux décennies, la tendance indéniable de ces dernières années est claire : déplacer les bases de données vers le cloud.
J'étais déjà impliqué dans quelques projets de migration, dont l'objectif était d'intégrer la base de données existante sur site dans la base de données cloud d'Amazon Web Services (AWS). Alors que dans les documents de documentation AWS, vous apprendrez à quel point cela peut être facile, je suis ici pour vous dire que l'exécution d'un tel plan n'est pas toujours facile et qu'il y a des cas où cela peut échouer.

Dans cet article, je couvrirai l'expérience du monde réel pour le cas suivant :
- La source : Bien qu'en théorie, peu importe quelle est votre source (vous pouvez utiliser une approche très similaire pour la majorité des bases de données les plus populaires), Oracle a été le système de base de données de choix dans les grandes entreprises pendant de nombreuses années, et c'est là que je me concentrerai.
- La Cible : Aucune raison d'être précis de ce côté. Vous pouvez choisir n'importe quelle base de données cible dans AWS, et l'approche conviendra toujours.
- Le mode : Vous pouvez avoir un rafraîchissement complet ou un rafraîchissement incrémentiel. Un chargement de données par lots (les états source et cible sont retardés) ou un chargement de données (presque) en temps réel. Les deux seront abordés ici.
- La fréquence : Vous pouvez souhaiter une migration unique suivie d'un basculement complet vers le cloud ou nécessiter une période de transition et avoir les données à jour des deux côtés simultanément, ce qui implique de développer une synchronisation quotidienne entre sur site et AWS. Le premier est plus simple et a beaucoup plus de sens, mais le second est plus souvent demandé et a beaucoup plus de points de rupture. Je couvrirai les deux ici.
Description du problème
Le besoin est souvent simple :
Nous voulons commencer à développer des services au sein d'AWS, veuillez donc copier toutes nos données dans la base de données "ABC". Rapidement et simplement. Nous devons utiliser les données à l'intérieur d'AWS maintenant. Plus tard, nous déterminerons quelles parties des conceptions de base de données doivent être modifiées pour correspondre à nos activités.
Avant d'aller plus loin, il y a quelque chose à considérer :
- Ne sautez pas trop vite dans l'idée de "copier simplement ce que nous avons et de le traiter plus tard". Je veux dire, oui, c'est le plus simple que vous puissiez faire, et ce sera fait rapidement, mais cela a le potentiel de créer un problème architectural aussi fondamental qu'il sera impossible de résoudre plus tard sans une refactorisation sérieuse de la majorité de la nouvelle plate-forme cloud . Imaginez simplement que l'écosystème cloud est complètement différent de celui sur site. Plusieurs nouveaux services seront introduits au fil du temps. Naturellement, les gens commenceront à utiliser le même très différemment. Ce n'est presque jamais une bonne idée de répliquer l'état sur site dans le cloud de manière 1:1. Cela pourrait être dans votre cas particulier, mais assurez-vous de bien vérifier cela.
- Remettez en question l'exigence avec quelques doutes significatifs comme :
- Qui sera l'utilisateur typique utilisant la nouvelle plate-forme ? Sur site, il peut s'agir d'un utilisateur métier transactionnel ; dans le cloud, il peut s'agir d'un scientifique des données ou d'un analyste d'entrepôt de données, ou l'utilisateur principal des données peut être un service (par exemple, Databricks, Glue, modèles d'apprentissage automatique, etc.).
- Les tâches quotidiennes régulières sont-elles censées rester même après la transition vers le cloud ? Si non, comment sont-ils censés changer ?
- Prévoyez-vous une croissance substantielle des données au fil du temps ? Très probablement, la réponse est oui, car c'est souvent la raison la plus importante de migrer vers le cloud. Un nouveau modèle de données doit être prêt pour cela.
- Attendez-vous à ce que l'utilisateur final réfléchisse à certaines requêtes générales anticipées que la nouvelle base de données recevra des utilisateurs. Cela définira dans quelle mesure le modèle de données existant doit changer pour rester pertinent en termes de performances.
Mise en place de la migration
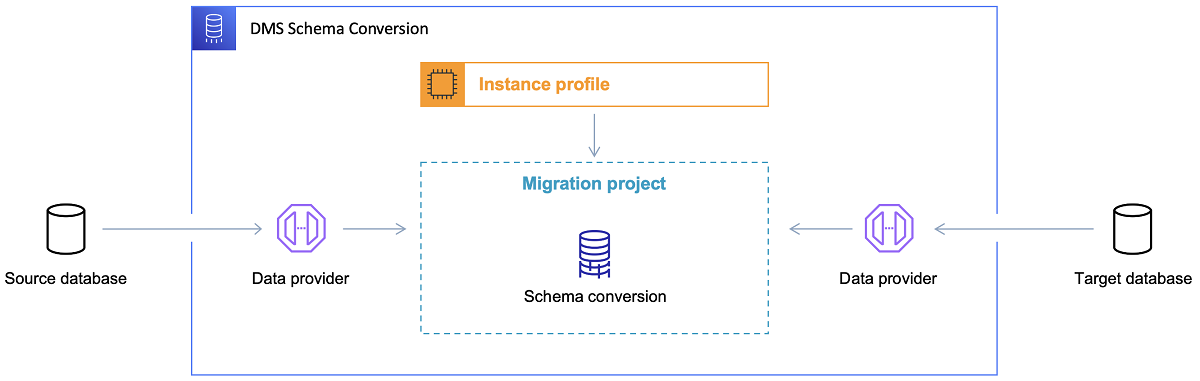
Une fois la base de données cible choisie et le modèle de données discuté de manière satisfaisante, l'étape suivante consiste à se familiariser avec AWS Schema Conversion Tool. Il existe plusieurs domaines dans lesquels cet outil peut servir :
- Analysez et extrayez le modèle de données source. SCT lira ce qui se trouve dans la base de données actuelle sur site et générera un modèle de données source pour commencer.
- Suggérez une structure de modèle de données cible basée sur la base de données cible.
- Générez des scripts de déploiement de base de données cible pour installer le modèle de données cible (en fonction de ce que l'outil a découvert à partir de la base de données source). Cela générera des scripts de déploiement et, après leur exécution, la base de données dans le cloud sera prête pour les chargements de données à partir de la base de données sur site.
Voici maintenant quelques astuces pour utiliser l'outil de conversion de schéma.
Premièrement, il ne devrait presque jamais être possible d'utiliser directement la sortie. Je considérerais cela plutôt comme des résultats de référence, à partir desquels vous ferez vos ajustements en fonction de votre compréhension et de l'objectif des données et de la manière dont les données seront utilisées dans le cloud.
Deuxièmement, auparavant, les tables étaient probablement sélectionnées par des utilisateurs qui attendaient des résultats courts et rapides sur une entité concrète du domaine des données. Mais maintenant, les données pourraient être sélectionnées à des fins d'analyse. Par exemple, les index de base de données qui fonctionnaient auparavant dans la base de données sur site seront désormais inutiles et n'amélioreront certainement pas les performances du système de base de données liées à cette nouvelle utilisation. De même, vous souhaiterez peut-être partitionner les données différemment sur le système cible, comme c'était le cas auparavant sur le système source.
En outre, il peut être judicieux d'envisager d'effectuer certaines transformations de données pendant le processus de migration, ce qui signifie essentiellement modifier le modèle de données cible pour certaines tables (afin qu'elles ne soient plus des copies 1:1). Plus tard, les règles de transformation devront être implémentées dans l'outil de migration.
Configuration de l'outil de migration
Si les bases de données source et cible sont du même type (par exemple, Oracle sur site contre Oracle dans AWS, PostgreSQL contre Aurora Postgresql, etc.), il est préférable d'utiliser un outil de migration dédié que la base de données concrète prend en charge de manière native ( ex., exportations et importations de pompe de données, Oracle Goldengate, etc.).
Cependant, dans la plupart des cas, la base de données source et cible ne seront pas compatibles, et l'outil de choix évident sera AWS Database Migration Service.
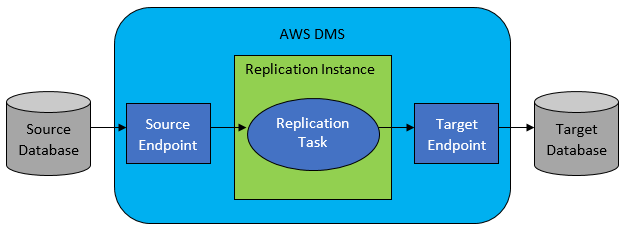
AWS DMS permet essentiellement de configurer une liste de tâches au niveau de la table, qui définira :
- Quelle est la base de données source exacte et la table à laquelle se connecter ?
- Spécifications d'instruction qui seront utilisées pour obtenir les données de la table cible.
- Outils de transformation (le cas échéant), définissant comment les données source doivent être mappées dans les données de la table cible (si ce n'est pas 1:1).
- Quelle est la base de données et la table cible exactes dans lesquelles charger les données ?
La configuration des tâches DMS se fait dans un format convivial comme JSON.
Maintenant, dans le scénario le plus simple, il vous suffit d'exécuter les scripts de déploiement sur la base de données cible et de démarrer la tâche DMS. Mais il y a bien plus à cela.

Migration complète des données en une seule fois

Le cas le plus simple à exécuter est lorsque la demande consiste à déplacer l'intégralité de la base de données une fois dans la base de données cloud cible. Ensuite, fondamentalement, tout ce qu'il faut faire ressemblera à ce qui suit :
- Définissez la tâche DMS pour chaque table source.
- Assurez-vous de spécifier correctement la configuration des tâches DMS. Cela signifie la mise en place d'un parallélisme raisonnable, la mise en cache des variables, la configuration du serveur DMS, le dimensionnement du cluster DMS, etc. Il s'agit généralement de la phase la plus longue car elle nécessite des tests approfondis et un réglage fin de l'état de configuration optimal.
- Assurez-vous que chaque table cible est créée (vide) dans la base de données cible dans la structure de table attendue.
- Planifiez une fenêtre de temps dans laquelle la migration des données sera effectuée. Avant cela, bien sûr, assurez-vous (en faisant des tests de performances) que la fenêtre de temps sera suffisante pour que la migration se termine. Pendant la migration elle-même, la base de données source peut être restreinte du point de vue des performances. En outre, il est prévu que la base de données source ne changera pas pendant la durée de la migration. Sinon, les données migrées peuvent être différentes de celles stockées dans la base de données source une fois la migration effectuée.
Si la configuration de DMS est bonne, rien de mal ne se produira dans ce scénario. Chaque table source unique sera récupérée et copiée dans la base de données cible AWS. Les seules préoccupations seront les performances de l'activité et s'assurer que le dimensionnement est correct à chaque étape afin qu'il n'échoue pas en raison d'un espace de stockage insuffisant.
Synchronisation quotidienne incrémentielle

C'est là que les choses commencent à se compliquer. Je veux dire, si le monde était idéal, alors ça marcherait probablement très bien tout le temps. Mais le monde n'est jamais idéal.
DMS peut être configuré pour fonctionner en deux modes :
- Pleine charge – mode par défaut décrit et utilisé ci-dessus. Les tâches DMS sont démarrées soit lorsque vous les démarrez, soit lorsqu'elles sont planifiées pour démarrer. Une fois terminées, les tâches DMS sont terminées.
- Change Data Capture (CDC) - dans ce mode, la tâche DMS s'exécute en continu. DMS analyse la base de données source pour un changement au niveau de la table. Si le changement se produit, il essaie immédiatement de répliquer le changement dans la base de données cible en fonction de la configuration à l'intérieur de la tâche DMS liée à la table modifiée.
Lorsque vous optez pour CDC, vous devez faire un autre choix, à savoir comment le CDC extraira les modifications delta de la base de données source.
#1. Lecteur de journaux de rétablissement Oracle
Une option consiste à choisir le lecteur de journaux de rétablissement de base de données natif d'Oracle, que CDC peut utiliser pour obtenir les données modifiées et, en fonction des dernières modifications, répliquer les mêmes modifications sur la base de données cible.
Bien que cela puisse sembler un choix évident s'il s'agit d'Oracle comme source, il y a un hic : le lecteur de journaux redo Oracle utilise le cluster Oracle source et affecte ainsi directement toutes les autres activités exécutées dans la base de données (il crée en fait directement des sessions actives dans la base de données).
Plus vous avez configuré de tâches DMS (ou plus de clusters DMS en parallèle), plus vous aurez probablement besoin de faire évoluer le cluster Oracle - en gros, ajustez la mise à l'échelle verticale de votre cluster de base de données Oracle principal. Cela influencera sûrement les coûts totaux de la solution, d'autant plus si la synchronisation quotidienne est sur le point de rester avec le projet pendant une longue période.
#2. Mineur de journaux AWS DMS
Contrairement à l'option ci-dessus, il s'agit d'une solution AWS native au même problème. Dans ce cas, DMS n'affecte pas la base de données Oracle source. Au lieu de cela, il copie les journaux redo Oracle dans le cluster DMS et y effectue tout le traitement. Bien qu'elle économise les ressources Oracle, c'est la solution la plus lente, car davantage d'opérations sont impliquées. Et aussi, comme on peut facilement le supposer, le lecteur personnalisé pour les journaux redo d'Oracle est probablement plus lent dans son travail que le lecteur natif d'Oracle.
En fonction de la taille de la base de données source et du nombre de modifications quotidiennes, dans le meilleur des cas, vous pourriez vous retrouver avec une synchronisation incrémentielle presque en temps réel des données de la base de données Oracle sur site dans la base de données cloud AWS.
Dans tous les autres scénarios, il ne s'agira toujours pas d'une synchronisation en temps réel, mais vous pouvez essayer de vous rapprocher le plus possible du délai accepté (entre la source et la cible) en réglant la configuration et le parallélisme des performances des clusters source et cible ou en expérimentant avec la quantité de tâches DMS et leur répartition entre les instances CDC.
Et vous voudrez peut-être savoir quelles modifications de la table source sont prises en charge par CDC (comme l'ajout d'une colonne, par exemple) car toutes les modifications possibles ne sont pas prises en charge. Dans certains cas, le seul moyen est de modifier manuellement la table cible et de redémarrer la tâche CDC à partir de zéro (en perdant toutes les données existantes dans la base de données cible en cours de route).
Quand les choses tournent mal, quoi qu'il arrive

J'ai appris cela à la dure, mais il existe un scénario spécifique lié au DMS où la promesse d'une réplication quotidienne est difficile à tenir.
Le DMS ne peut traiter les redo logs qu'avec une certaine vitesse définie. Peu importe s'il y a plus d'instances de DMS exécutant vos tâches. Pourtant, chaque instance DMS ne lit les redo logs qu'avec une seule vitesse définie, et chacun d'entre eux doit les lire en entier. Peu importe que vous utilisiez les journaux redo Oracle ou le mineur de journaux AWS. Les deux ont cette limite.
Si la base de données source inclut un grand nombre de modifications en une journée alors que les journaux redo d'Oracle deviennent vraiment volumineux (comme 500 Go + gros) chaque jour, CDC ne fonctionnera tout simplement pas. La réplication ne sera pas achevée avant la fin de la journée. Cela apportera du travail non traité au lendemain, où un nouvel ensemble de modifications à répliquer attend déjà. La quantité de données non traitées ne fera qu'augmenter de jour en jour.
Dans ce cas particulier, CDC n'était pas une option (après de nombreux tests de performance et essais que nous avons exécutés). La seule façon de s'assurer qu'au moins tous les changements delta du jour en cours seront répliqués le même jour était de l'aborder comme ceci :
- Séparez les très grandes tables qui ne sont pas utilisées si souvent et ne les reproduisez qu'une fois par semaine (par exemple, pendant les week-ends).
- Configurez la réplication de tables pas si grandes mais toujours grandes à répartir entre plusieurs tâches DMS ; une table a finalement été migrée par 10 tâches DMS séparées ou plus en parallèle, garantissant que la répartition des données entre les tâches DMS est distincte (codage personnalisé impliqué ici) et les exécute quotidiennement.
- Ajoutez plus (jusqu'à 4 dans ce cas) instances de DMS et répartissez les tâches DMS entre elles de manière égale, ce qui signifie non seulement par le nombre de tables mais aussi par la taille.
Fondamentalement, nous avons utilisé le mode de chargement complet de DMS pour répliquer les données quotidiennes, car c'était le seul moyen d'obtenir au moins l'achèvement de la réplication des données le jour même.
Pas une solution parfaite, mais elle est toujours là, et même après de nombreuses années, elle fonctionne toujours de la même manière. Donc, peut-être pas une si mauvaise solution après tout.