
Machine à vecteurs de support (SVM) dans l'apprentissage automatique
Publié: 2023-01-04Support Vector Machine est l'un des algorithmes d'apprentissage automatique les plus populaires. Il est efficace et peut s'entraîner dans des ensembles de données limités. Mais qu'est-ce que c'est?
Qu'est-ce qu'une machine à vecteurs de support (SVM) ?
La machine à vecteurs de support est un algorithme d'apprentissage automatique qui utilise l'apprentissage supervisé pour créer un modèle de classification binaire. C'est une bouchée. Cet article explique SVM et son lien avec le traitement du langage naturel. Mais d'abord, analysons le fonctionnement d'une machine à vecteurs de support.
Comment fonctionne SVM ?
Considérons un problème de classification simple où nous avons des données qui ont deux caractéristiques, x et y, et une sortie - une classification qui est rouge ou bleue. Nous pouvons tracer un jeu de données imaginaire qui ressemble à ceci :
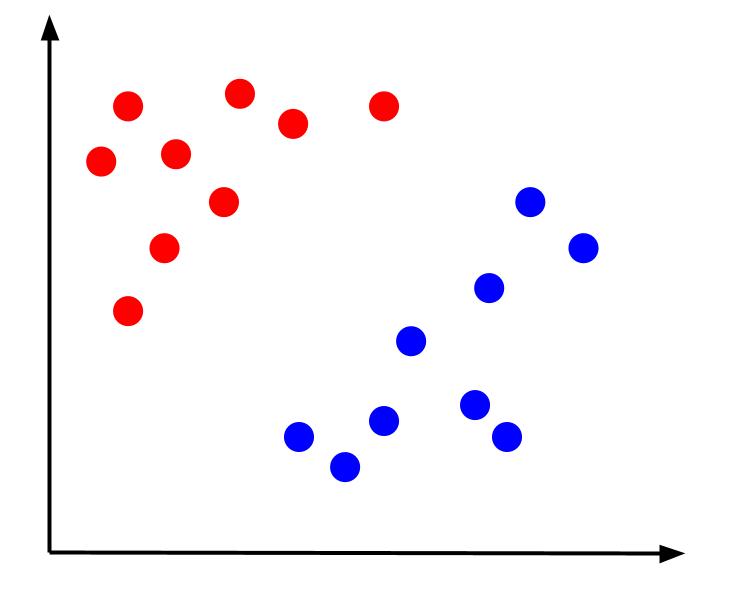
Avec des données comme celle-ci, la tâche serait de créer une limite de décision. Une frontière de décision est une ligne qui sépare les deux classes de nos points de données. Il s'agit du même jeu de données mais avec une limite de décision :
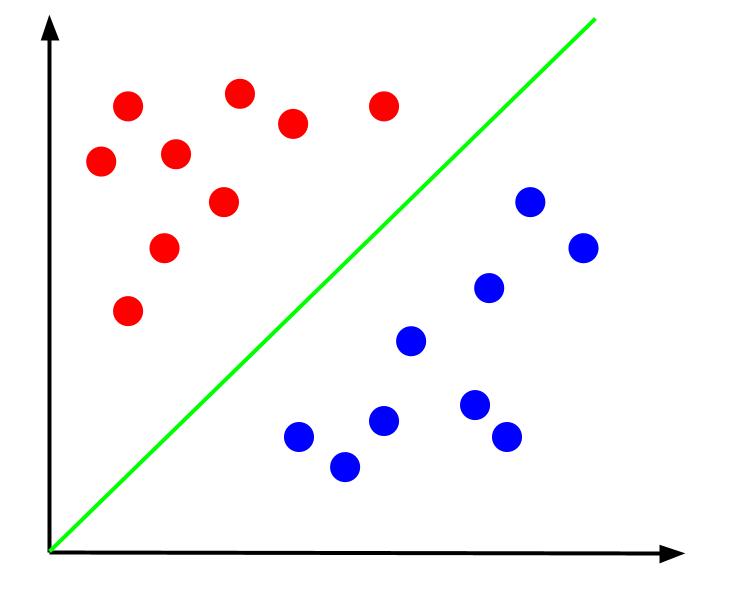
Avec cette frontière de décision, nous pouvons alors faire des prédictions pour la classe à laquelle appartient un point de données, étant donné où il se situe par rapport à la frontière de décision. L'algorithme Support Vector Machine crée la meilleure limite de décision qui sera utilisée pour classer les points.
Mais qu'entend-on par meilleure limite de décision ?
La meilleure frontière de décision peut être considérée comme celle qui maximise sa distance à l'un ou l'autre des vecteurs de support. Les vecteurs de support sont des points de données de l'une ou l'autre des classes les plus proches de la classe opposée. Ces points de données présentent le plus grand risque d'erreur de classification en raison de leur proximité avec l'autre classe.
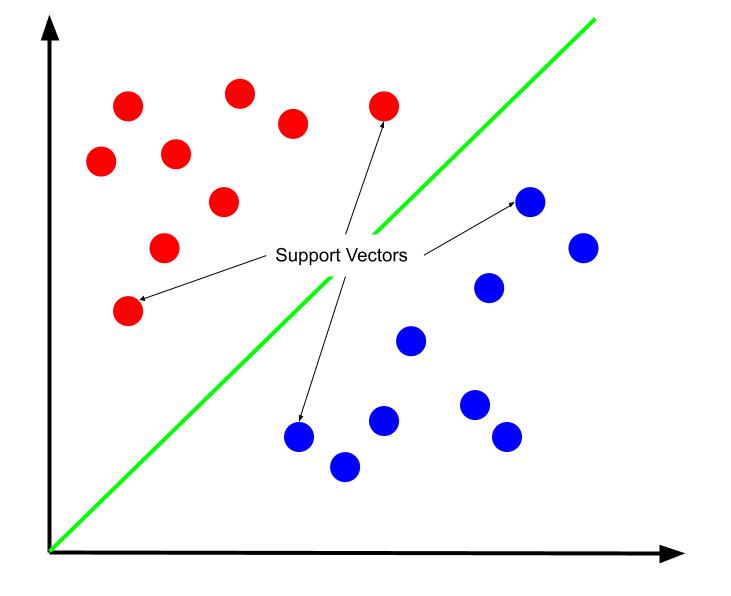
La formation d'une machine à vecteurs de support implique donc d'essayer de trouver une ligne qui maximise la marge entre les vecteurs de support.
Il est également important de noter que parce que la frontière de décision est positionnée par rapport aux vecteurs de support, ils sont les seuls déterminants de la position de la frontière de décision. Les autres points de données sont donc redondants. Et ainsi, la formation ne nécessite que les vecteurs de support.
Dans cet exemple, la frontière de décision formée est une ligne droite. C'est uniquement parce que l'ensemble de données n'a que deux caractéristiques. Lorsque le jeu de données comporte trois entités, la limite de décision formée est un plan plutôt qu'une ligne. Et lorsqu'il a quatre caractéristiques ou plus, la limite de décision est connue sous le nom d'hyperplan.
Données non linéairement séparables
L'exemple ci-dessus considère des données très simples qui, une fois tracées, peuvent être séparées par une limite de décision linéaire. Considérons un cas différent où les données sont tracées comme suit :
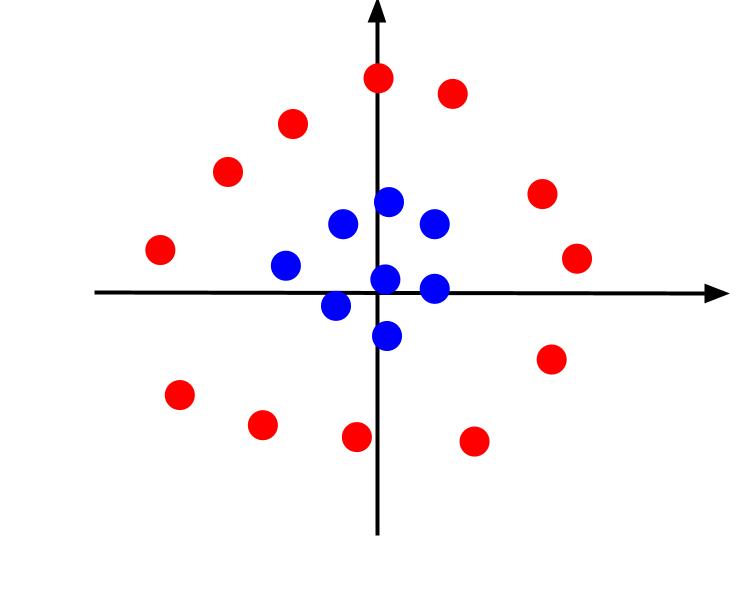
Dans ce cas, séparer les données à l'aide d'une ligne est impossible. Mais nous pouvons créer une autre fonctionnalité, z. Et cette caractéristique peut être définie par l'équation : z = x^2 + y^2. Nous pouvons ajouter z comme troisième axe au plan pour le rendre tridimensionnel.
Lorsque nous regardons le tracé 3D sous un angle tel que l'axe x est horizontal tandis que l'axe z est vertical, c'est la vue que nous obtenons quelque chose qui ressemble à ceci :
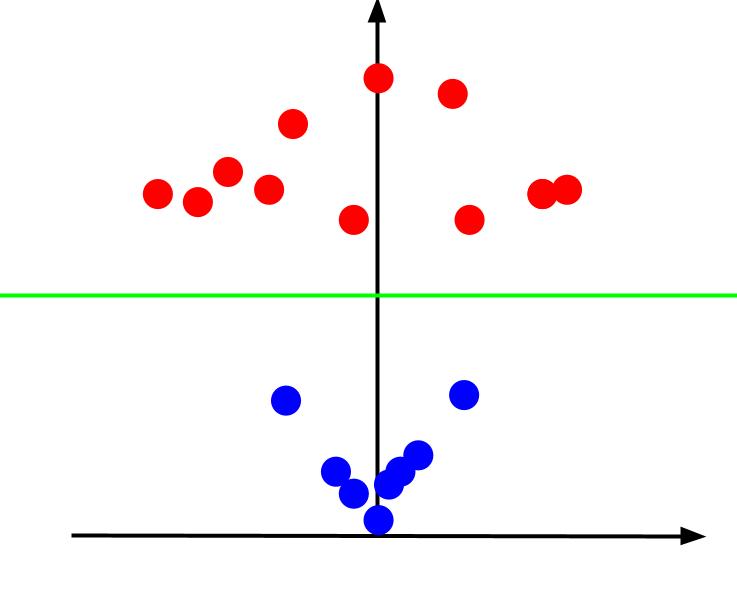
La valeur z représente la distance entre un point et l'origine par rapport aux autres points de l'ancien plan XY. Par conséquent, les points bleus les plus proches de l'origine ont des valeurs z faibles.
Alors que les points rouges plus éloignés de l'origine avaient des valeurs z plus élevées, les tracer par rapport à leurs valeurs z nous donne une classification claire qui peut être délimitée par une limite de décision linéaire, comme illustré.
C'est une idée puissante qui est utilisée dans les machines à vecteurs de support. Plus généralement, c'est l'idée de mapper les dimensions dans un nombre plus élevé de dimensions afin que les points de données puissent être séparés par une frontière linéaire. Les fonctions qui en sont responsables sont les fonctions du noyau. Il existe de nombreuses fonctions de noyau, telles que sigmoïde, linéaire, non linéaire et RBF.
Pour rendre le mappage de ces fonctionnalités plus efficace, SVM utilise une astuce du noyau.
SVM dans l'apprentissage automatique
Support Vector Machine est l'un des nombreux algorithmes utilisés dans l'apprentissage automatique aux côtés d'algorithmes populaires tels que les arbres de décision et les réseaux de neurones. Il est préféré car il fonctionne bien avec moins de données que les autres algorithmes. Il est couramment utilisé pour effectuer les opérations suivantes :
- Classification de texte : classification des données textuelles telles que les commentaires et les critiques dans une ou plusieurs catégories
- Détection de visage : Analyser des images pour détecter des visages pour faire des choses comme ajouter des filtres pour la réalité augmentée
- Classification des images : les machines à vecteurs de support peuvent classer les images efficacement par rapport à d'autres approches.
Le problème de classification de texte
Internet est rempli de beaucoup, beaucoup de données textuelles. Cependant, une grande partie de ces données sont non structurées et non étiquetées. Pour mieux utiliser ces données textuelles et mieux les comprendre, une classification est nécessaire. Voici des exemples de cas où le texte est classé :
- Lorsque les tweets sont classés en sujets afin que les gens puissent suivre les sujets qu'ils souhaitent
- Lorsqu'un e-mail est classé dans les catégories Social, Promotions ou Spam
- Lorsque les commentaires sont classés comme étant haineux ou obscènes dans les forums publics
Fonctionnement de SVM avec la classification en langage naturel
Support Vector Machine est utilisé pour classer le texte en texte qui appartient à un sujet particulier et en texte qui n'appartient pas au sujet. Ceci est réalisé en convertissant et en représentant d'abord les données textuelles dans un ensemble de données avec plusieurs fonctionnalités.
Une façon d'y parvenir consiste à créer des caractéristiques pour chaque mot de l'ensemble de données. Ensuite, pour chaque point de données de texte, vous enregistrez le nombre de fois où chaque mot apparaît. Supposons donc que des mots uniques apparaissent dans l'ensemble de données ; vous aurez des fonctionnalités dans le jeu de données.
De plus, vous fournirez des classifications pour ces points de données. Bien que ces classifications soient étiquetées par du texte, la plupart des implémentations SVM attendent des étiquettes numériques.
Par conséquent, vous devrez convertir ces étiquettes en nombres avant la formation. Une fois le jeu de données préparé, en utilisant ces caractéristiques comme coordonnées, vous pouvez ensuite utiliser un modèle SVM pour classer le texte.
Créer une SVM en Python
Pour créer une machine à vecteurs de support (SVM) en Python, vous pouvez utiliser la classe SVC de la bibliothèque sklearn.svm . Voici un exemple d'utilisation de la classe SVC pour créer un modèle SVM en Python :
from sklearn.svm import SVC # Load the dataset X = ... y = ... # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) # Create an SVM model model = SVC(kernel='linear') # Train the model on the training data model.fit(X_train, y_train) # Evaluate the model on the test data accuracy = model.score(X_test, y_test) print("Accuracy: ", accuracy) Dans cet exemple, nous importons d'abord la classe SVC depuis la bibliothèque sklearn.svm . Ensuite, nous chargeons l'ensemble de données et le divisons en ensembles d'apprentissage et de test.
Ensuite, nous créons un modèle SVM en instanciant un objet SVC et en spécifiant le paramètre du kernel comme "linéaire". Nous formons ensuite le modèle sur les données de formation à l'aide de la méthode fit et évaluons le modèle sur les données de test à l'aide de la méthode de score . La méthode score renvoie la précision du modèle, que nous imprimons à la console.
Vous pouvez également spécifier d'autres paramètres pour l'objet SVC , tels que le paramètre C qui contrôle la force de la régularisation et le paramètre gamma , qui contrôle le coefficient de noyau pour certains noyaux.
Avantages de SVM
Voici une liste de certains avantages de l'utilisation de machines à vecteurs de support (SVM) :
- Efficace : Les SVM sont généralement efficaces à former, surtout lorsque le nombre d'échantillons est important.
- Robuste au bruit : les SVM sont relativement robustes au bruit dans les données d'apprentissage car ils essaient de trouver le classificateur de marge maximale, qui est moins sensible au bruit que les autres classificateurs.
- Mémoire efficace : les SVM ne nécessitent qu'un sous-ensemble des données d'entraînement en mémoire à un moment donné, ce qui les rend plus efficaces en mémoire que les autres algorithmes.
- Efficace dans les espaces de grande dimension : les SVM peuvent toujours bien fonctionner même lorsque le nombre de fonctionnalités dépasse le nombre d'échantillons.
- Polyvalence : les SVM peuvent être utilisées pour des tâches de classification et de régression et peuvent gérer différents types de données, y compris des données linéaires et non linéaires.
Maintenant, explorons quelques-unes des meilleures ressources pour apprendre Support Vector Machine (SVM).

Ressources d'apprentissage
Une introduction aux machines à vecteurs de support
Ce livre sur l'introduction aux machines à vecteurs de support vous présente de manière complète et progressive les méthodes d'apprentissage basées sur le noyau.
| Aperçu | Produit | Notation | Prix | |
|---|---|---|---|---|
 | Une introduction aux machines à vecteurs de support et aux autres méthodes d'apprentissage basées sur le noyau | 75,00 $ | Acheter sur Amazon |
Il vous donne une base solide sur la théorie des machines à vecteurs de support.
Soutenir les applications des machines vectorielles
Alors que le premier livre portait sur la théorie des machines à vecteurs de support, ce livre sur les applications des machines à vecteurs de support se concentre sur leurs applications pratiques.
| Aperçu | Produit | Notation | Prix | |
|---|---|---|---|---|
 | Soutenir les applications des machines vectorielles | 15,52 $ | Acheter sur Amazon |
Il examine comment les SVM sont utilisées dans le traitement d'images, la détection de modèles et la vision par ordinateur.
Soutenir les machines vectorielles (sciences de l'information et statistiques)
Le but de ce livre sur les machines à vecteurs de support (sciences de l'information et statistiques) est de fournir un aperçu des principes qui sous-tendent l'efficacité des machines à vecteurs de support (SVM) dans diverses applications.
| Aperçu | Produit | Notation | Prix | |
|---|---|---|---|---|
 | Soutenir les machines vectorielles (sciences de l'information et statistiques) | 167,36 $ | Acheter sur Amazon |
Les auteurs mettent en évidence plusieurs facteurs qui contribuent au succès des SVM, notamment leur capacité à bien fonctionner avec un nombre limité de paramètres ajustables, leur résistance à divers types d'erreurs et d'anomalies, et leurs performances de calcul efficaces par rapport aux autres méthodes.
Apprendre avec les noyaux
"Learning with Kernels" est un livre qui présente aux lecteurs la prise en charge des machines vectorielles (SVM) et des techniques de noyau associées.
| Aperçu | Produit | Notation | Prix | |
|---|---|---|---|---|
 | Apprendre avec les noyaux : prendre en charge les machines vectorielles, la régularisation, l'optimisation et au-delà (adaptation… | 80,00 $ | Acheter sur Amazon |
Il est conçu pour donner aux lecteurs une compréhension de base des mathématiques et les connaissances dont ils ont besoin pour commencer à utiliser les algorithmes du noyau dans l'apprentissage automatique. Le livre vise à fournir une introduction complète mais accessible aux SVM et aux méthodes du noyau.
Soutenez les machines vectorielles avec Sci-kit Learn
Ce cours en ligne Support Vector Machines with Sci-kit Learn du réseau de projets Coursera enseigne comment implémenter un modèle SVM à l'aide de la célèbre bibliothèque d'apprentissage automatique Sci-Kit Learn.

De plus, vous apprendrez la théorie derrière les SVM et déterminerez leurs forces et leurs limites. Le cours est de niveau débutant et dure environ 2,5 heures.
Prise en charge des machines vectorielles en Python : concepts et code
Ce cours en ligne payant sur les machines à vecteurs de support en Python par Udemy comprend jusqu'à 6 heures d'instructions vidéo et est accompagné d'une certification.

Il couvre les SVM et comment elles peuvent être solidement implémentées en Python. En outre, il couvre les applications commerciales des machines à vecteurs de support.
Apprentissage automatique et IA : prendre en charge les machines vectorielles en Python
Dans ce cours sur l'apprentissage automatique et l'IA, vous apprendrez à utiliser les machines à vecteurs de support (SVM) pour diverses applications pratiques, notamment la reconnaissance d'images, la détection de spam, le diagnostic médical et l'analyse de régression.

Vous utiliserez le langage de programmation Python pour implémenter des modèles ML pour ces applications.
Derniers mots
Dans cet article, nous avons brièvement découvert la théorie derrière les machines à vecteurs de support. Nous avons découvert leur application dans l'apprentissage automatique et le traitement du langage naturel.
Nous avons également vu à quoi ressemble son implémentation à l'aide scikit-learn . De plus, nous avons parlé des applications pratiques et des avantages des machines à vecteurs de support.
Bien que cet article ne soit qu'une introduction, les ressources supplémentaires recommandaient d'aller plus en détail, en expliquant davantage sur les machines à vecteurs de support. Compte tenu de leur polyvalence et de leur efficacité, les SVM méritent d'être compris pour évoluer en tant que data scientist et ingénieur ML.
Ensuite, vous pouvez consulter les meilleurs modèles d'apprentissage automatique.