
Comment créer un DataFrame Pandas [avec exemples]
Publié: 2022-12-08Apprenez les bases du travail avec pandas DataFrames : la structure de données de base dans pandas, une puissante bibliothèque de manipulation de données.
Si vous souhaitez vous lancer dans l'analyse de données en Python, pandas est l'une des premières bibliothèques avec lesquelles vous devriez apprendre à travailler. De l'importation de données à partir de plusieurs sources telles que des fichiers CSV et des bases de données à la gestion des données manquantes et à leur analyse pour obtenir des informations - les pandas vous permettent de faire tout ce qui précède.
Pour commencer à analyser des données avec des pandas, vous devez comprendre la structure de données fondamentale dans les pandas : les trames de données .
Dans ce didacticiel, vous apprendrez les bases des dataframes pandas et les méthodes courantes pour créer des dataframes. Vous apprendrez ensuite à sélectionner des lignes et des colonnes à partir du dataframe pour récupérer des sous-ensembles de données.
Pour tout cela et plus encore, commençons.
Installer et importer des pandas
Comme pandas est une bibliothèque d'analyse de données tierce, vous devez d'abord l'installer. Il est recommandé d'installer des packages externes dans un environnement virtuel pour votre projet.
Si vous utilisez la distribution Anaconda de Python, vous pouvez utiliser conda pour la gestion des packages.
conda install pandasVous pouvez également installer des pandas en utilisant pip :
pip install pandasLa bibliothèque pandas nécessite NumPy comme dépendance. Donc, si NumPy n'est pas déjà installé, il sera également installé pendant le processus d'installation.
Après avoir installé pandas, vous pouvez l'importer dans votre environnement de travail. En général, pandas est importé sous l'alias pd :
import pandas as pdQu'est-ce qu'un DataFrame dans Pandas ?

La structure de données fondamentale dans les pandas est la trame de données . Un bloc de données est un tableau de données à deux dimensions avec un index étiqueté et des colonnes nommées . Chaque colonne du bloc de données, appelée pandas series , partage un index commun.
Voici un exemple de bloc de données que nous allons créer à partir de zéro au cours des prochaines minutes. Cette base de données contient des données sur les dépenses de six étudiants en quatre semaines.

Les noms des élèves sont les étiquettes de ligne. Et les colonnes sont nommées 'Week1' à 'Week4'. Notez que toutes les colonnes partagent le même ensemble d'étiquettes de ligne, également appelé index .
Comment créer un DataFrame Pandas
Il existe plusieurs façons de créer une trame de données pandas. Dans ce tutoriel, nous aborderons les méthodes suivantes :
- Créer une trame de données à partir de tableaux NumPy
- Créer une trame de données à partir d'un dictionnaire Python
- Créer une trame de données en lisant des fichiers CSV
À partir de tableaux NumPy
Créons une trame de données à partir d'un tableau NumPy.
Créons le tableau de données de forme (6,4) en supposant qu'au cours d'une semaine donnée, chaque élève dépense entre 0 $ et 100 $. La fonction randint() du module random de NumPy renvoie un tableau d'entiers aléatoires dans un intervalle donné, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Pour créer une trame de données pandas, vous pouvez utiliser le constructeur DataFrame et transmettre le tableau NumPy comme argument de data , comme indiqué :
students_df = pd.DataFrame(data=data) Nous pouvons maintenant appeler la fonction intégrée type() pour vérifier le type de students_df . Nous voyons qu'il s'agit d'un objet DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 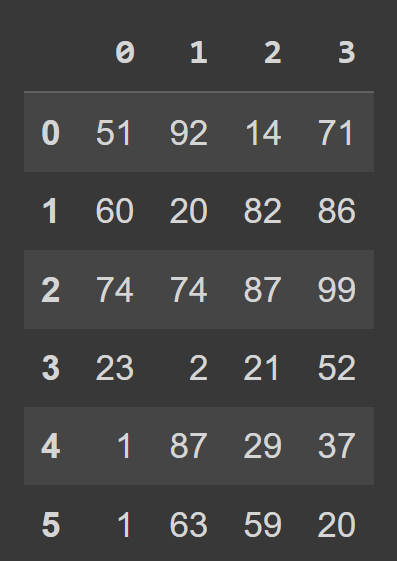
Nous voyons que par défaut, nous avons une indexation de plage qui va de 0 au numRows - 1, et les étiquettes de colonne sont 0, 1, 2, …, numCols -1. Cependant, cela réduit la lisibilité. Il sera utile d'ajouter des noms de colonne descriptifs et des étiquettes de ligne au bloc de données.
Créons deux listes : une pour stocker les noms des élèves et une autre pour stocker les étiquettes des colonnes.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Lors de l'appel du constructeur DataFrame , vous pouvez définir l' index et les columns sur les listes d'étiquettes de ligne et d'étiquettes de colonne à utiliser, respectivement.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Nous avons maintenant le students_df de données Students_df avec des étiquettes descriptives de ligne et de colonne.
print(students_df) 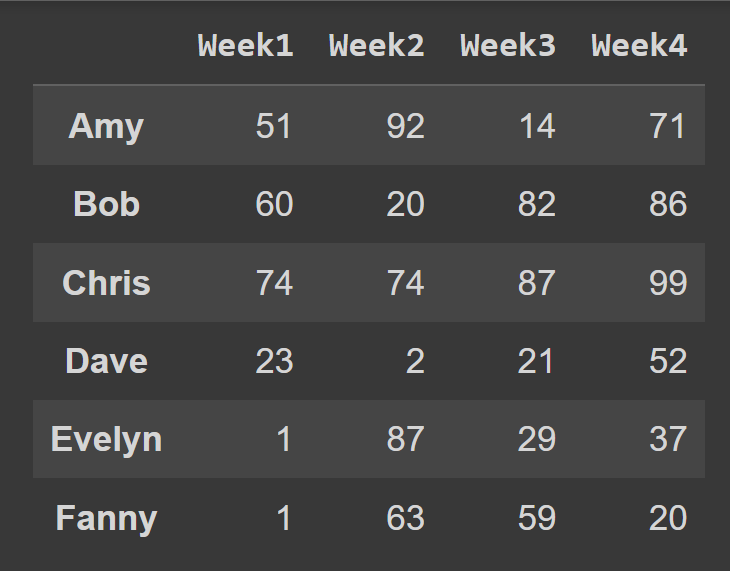
Pour obtenir des informations de base sur le bloc de données, telles que les valeurs manquantes et les types de données, vous pouvez appeler la méthode info() sur l'objet de bloc de données.
students_df.info() 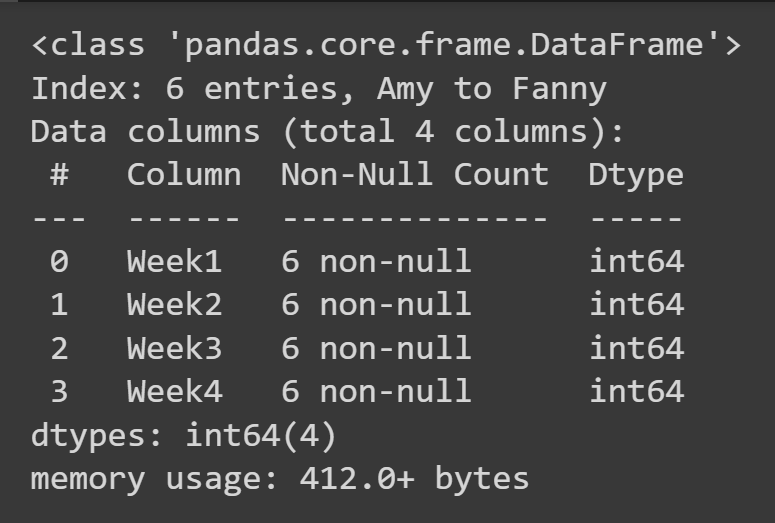
À partir d'un dictionnaire Python
Vous pouvez également créer une trame de données pandas à partir d'un dictionnaire Python.
Ici, data_dict est le dictionnaire contenant les données des étudiants :
- Les noms des élèves sont les clés.
- Chaque valeur est une liste de combien chaque élève dépense de la première à la quatrième semaine.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Pour créer une trame de données à partir d'un dictionnaire Python, utilisez from_dict , comme indiqué ci-dessous. Le premier argument correspond au dictionnaire contenant les données ( data_dict ). Par défaut, les clés sont utilisées comme noms de colonne du bloc de données. Comme nous aimerions définir les clés comme étiquettes de ligne , définissez orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 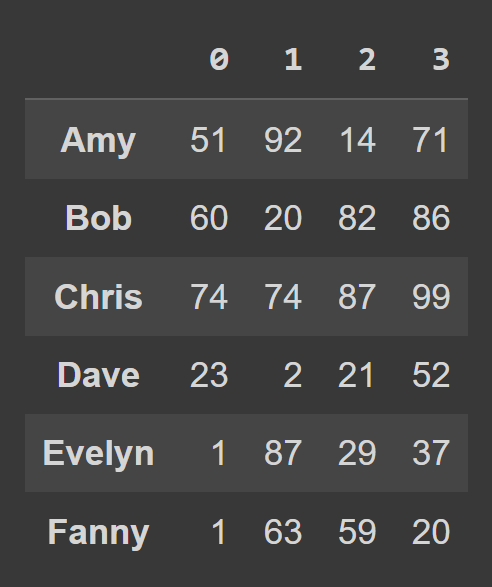
Pour remplacer les noms de colonne par le numéro de semaine, nous définissons les cols sur la liste des colonnes :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 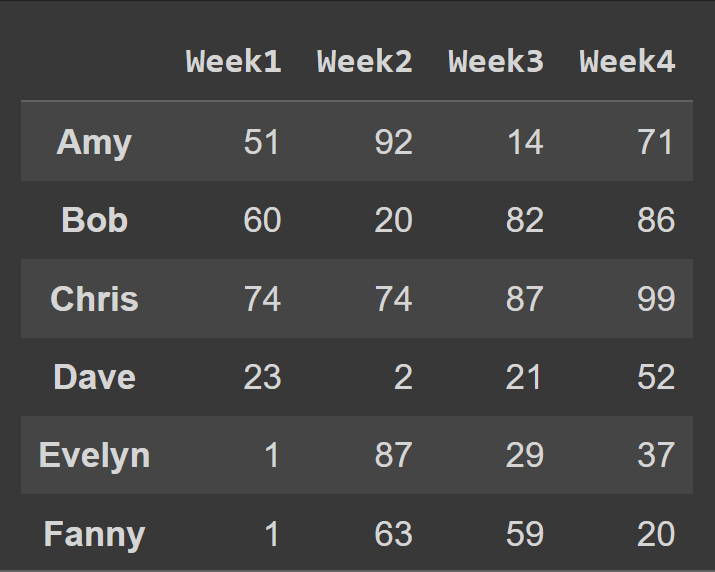
Lire dans un fichier CSV dans un Pandas DataFrame
Supposons que les données des étudiants soient disponibles dans un fichier CSV. Vous pouvez utiliser la fonction read_csv() pour lire les données du fichier dans une trame de données pandas. pd.read_csv('file-path') est la syntaxe générale, où file-path est le chemin d'accès au fichier CSV. Nous pouvons définir le paramètre names sur la liste des noms de colonnes à utiliser.
students_df = pd.read_csv('/content/students.csv',names=cols)Maintenant que nous savons comment créer un bloc de données, apprenons à sélectionner des lignes et des colonnes.
Sélectionner des colonnes à partir d'un DataFrame Pandas
Il existe plusieurs méthodes intégrées que vous pouvez utiliser pour sélectionner des lignes et des colonnes à partir d'un bloc de données. Ce didacticiel passera en revue les méthodes les plus courantes pour sélectionner des colonnes, des lignes, ainsi que des lignes et des colonnes à partir d'un bloc de données.
Sélection d'une seule colonne
Pour sélectionner une seule colonne, vous pouvez utiliser df_name[col_name] où col_name est la chaîne indiquant le nom de la colonne.
Ici, nous sélectionnons uniquement la colonne 'Week1'.
week1_df = students_df['Week1'] print(week1_df) 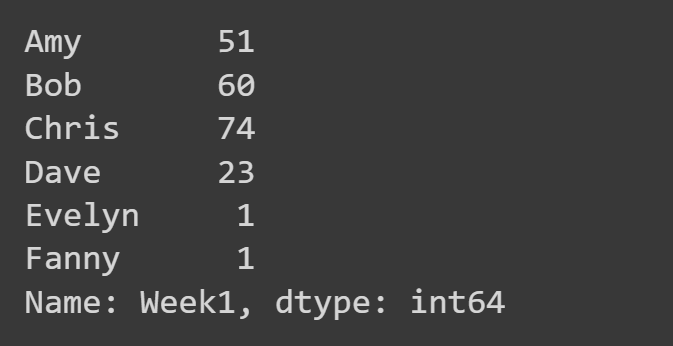
Sélection de plusieurs colonnes
Pour sélectionner plusieurs colonnes dans le bloc de données, transmettez la liste de tous les noms de colonne à sélectionner.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 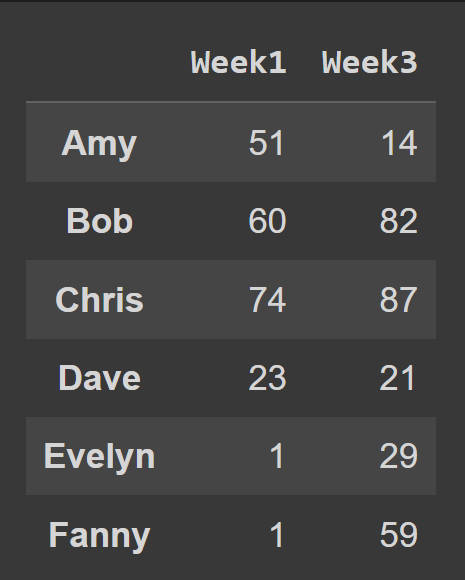
En plus de cette méthode, vous pouvez également utiliser les iloc() et loc() pour sélectionner des colonnes. Nous coderons un exemple plus tard.
Sélectionner des lignes à partir d'un DataFrame Pandas

Utilisation de la méthode .iloc()
Pour sélectionner des lignes à l'aide de la méthode iloc() , passez les indices correspondant à toutes les lignes sous forme de liste.
Dans cet exemple, nous sélectionnons les lignes à l'indice impair.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 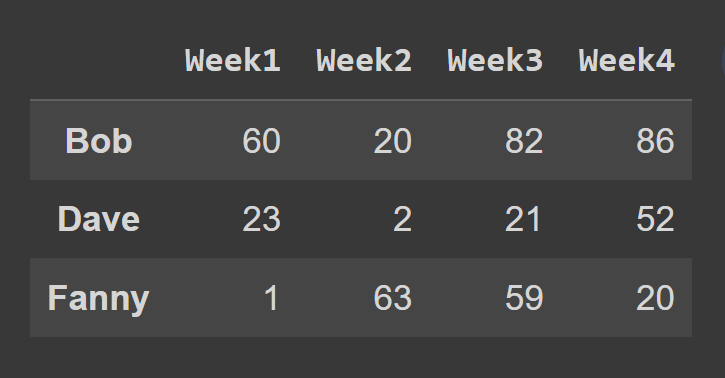
Ensuite, nous sélectionnons un sous-ensemble du bloc de données contenant les lignes aux index 0 à 2, le point final 3 est exclu par défaut.
slice1 = students_df.iloc[0:3] print(slice1) 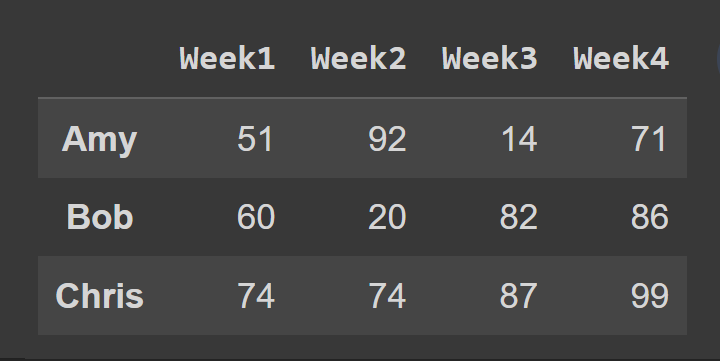
Utilisation de la méthode .loc()
Pour sélectionner les lignes d'un bloc de données à l'aide de la méthode loc() , vous devez spécifier les étiquettes correspondant aux lignes que vous souhaitez sélectionner.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 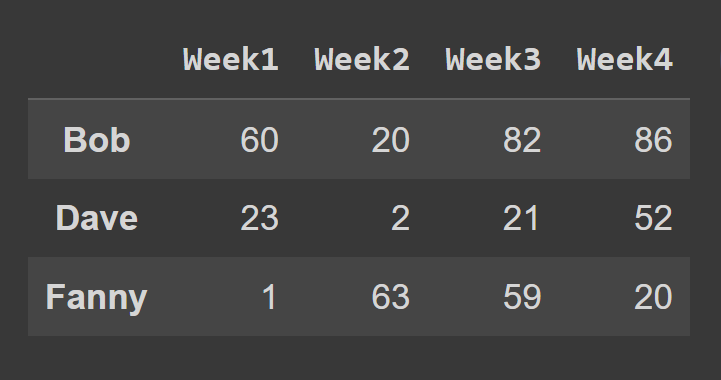
Si les lignes du bloc de données sont indexées à l'aide de la plage par défaut 0, 1, 2, jusqu'à
numRows-1, l'utilisationiloc()etloc()est équivalente.
Sélectionnez des lignes et des colonnes à partir d'un DataFrame Pandas
Jusqu'à présent, vous avez appris à sélectionner des lignes ou des colonnes à partir d'un bloc de données pandas. Cependant, vous devrez parfois sélectionner un sous-ensemble de lignes et de colonnes. Alors, comment faites-vous? Vous pouvez utiliser les iloc() et loc() dont nous avons parlé.
Par exemple, dans l'extrait de code ci-dessous, nous sélectionnons toutes les lignes et colonnes aux index 2 et 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 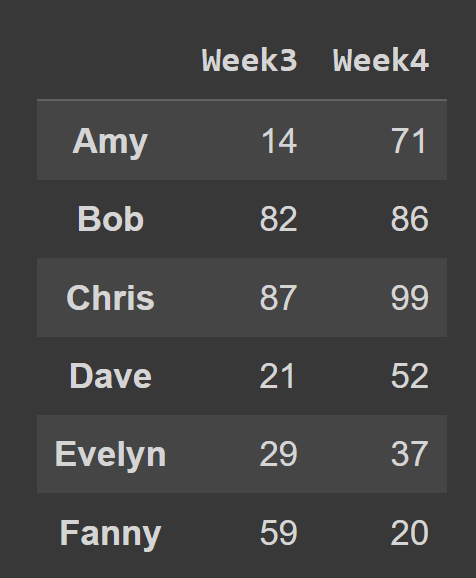
L'utilisation de start:stop crée une tranche de start jusqu'à mais sans inclure stop . Ainsi, lorsque vous ignorez les valeurs de start et stop , lorsque vous ignorez les valeurs de début et de fin, la tranche commence au début et s'étend jusqu'à la fin du bloc de données, en sélectionnant toutes les lignes.
Lorsque vous utilisez la méthode loc() , vous devez transmettre les étiquettes des lignes et des colonnes que vous souhaitez sélectionner, comme indiqué :
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 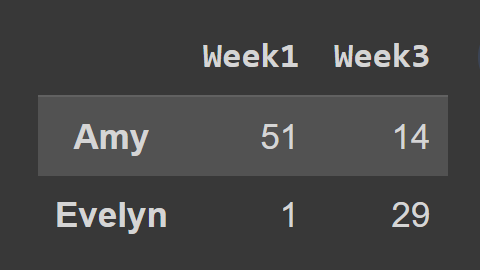
Ici, le dataframe subset_df2 contient l'enregistrement d'Amy et Evelyn pour Week1 et Week3.
Conclusion
Voici un bref aperçu de ce que vous avez appris dans ce didacticiel :
- Après avoir installé pandas, vous pouvez l'importer sous l'alias
pd. Pour créer un objet de cadre de données pandas, vous pouvez utiliser lepd.DataFrame(data), oùdatafait référence au tableau à N dimensions ou à un itérable contenant les données. Vous pouvez spécifier les étiquettes de ligne et d'index et de colonne en définissant respectivement les paramètres facultatifs d'index et de colonnes. - L'utilisation
pd.read_csv(path-to-the-file)lit le contenu du fichier dans une trame de données. - Vous pouvez appeler la méthode
info()sur l'objet de bloc de données pour obtenir des informations sur les colonnes, le nombre de valeurs manquantes, les types de données et la taille du bloc de données. - Pour sélectionner une seule colonne, utilisez
df_name[col_name], et pour sélectionner plusieurs colonnes, une colonne particulière,df_name[[col1,col2,...,coln]]. - Vous pouvez également sélectionner des colonnes et des lignes à l'aide des méthodes
loc()etiloc(). - Alors que la méthode
iloc()prend l'index (ou la tranche d'index) des lignes et des colonnes à sélectionner, la méthodeloc()prend les étiquettes de ligne et de colonne.
Vous trouverez les exemples utilisés dans ce didacticiel dans ce notebook Colab.
Ensuite, consultez cette liste de cahiers collaboratifs de science des données.