
Comment optimiser votre site Web pour les robots des moteurs de recherche ?
Publié: 2023-04-27Les robots d'exploration Web parcourent constamment les sites Web pour déterminer de quoi parle chaque page. Les données peuvent être indexées et modifiées et trouvées lorsque l'utilisateur soumet la demande. Certains sites Web utilisent des robots d'exploration Web pour mettre à jour le contenu de leur site Web.
Les moteurs de recherche comme Google ou Bing utilisent un moteur de recherche en conjonction avec la collecte d'informations par les robots d'exploration Web pour afficher les sites Web pertinents et les informations pertinentes à la suite des recherches des utilisateurs.
Si une conception Web l'entreprise ou le propriétaire du site souhaite voir son site Web apparaître dans les résultats de recherche, il doit être exploré et indexé. Si les sites ne sont pas explorés ou indexés, les moteurs de recherche ne pourront pas les localiser de manière organique.
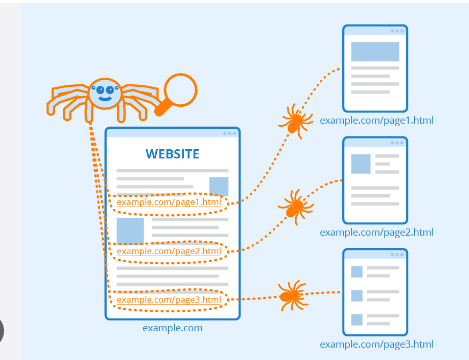
Les robots d'exploration Web commencent par explorer des pages particulières, puis en suivant des hyperliens sur les pages vers de nouvelles.
Les sites Web qui ne souhaitent pas être explorés ou découverts par les moteurs de recherche peuvent utiliser des outils tels que ceux trouvés dans le fichier robots.txt pour demander aux robots de ne pas indexer un site Web ou de n'en indexer qu'une petite partie.
La réalisation d'inspections de site avec des outils d'exploration peut aider les propriétaires de sites Web à identifier les hyperliens brisés ou le contenu en double. Titres absents ou trop longs ou courts d'un titre.
Table des matières
Rôle des moteurs de recherche dans le Web Crawling :
1. Crunching : Recherchez des informations sur Internet, puis le code source/contenu de chaque URL rencontrée.
2. Indexation : gérez et stockez les informations recueillies au cours du processus d'exploration. Une fois qu'une page est incluse dans l'index, l'afficher à la suite de recherches pertinentes peut être un processus continu.
3. Classement : présente les portions d'information les plus susceptibles de répondre aux besoins de l'utilisateur.
Qu'est-ce que crawling exactement dans Google ?
L'exploration est la méthode de recherche que les moteurs de recherche utilisent pour distribuer un ensemble de robots (araignées et robots) afin de trouver du contenu frais et mis à jour.
Le contenu peut être sous différents formats, tels que des images, des pages Web ou des vidéos, des PDF, etc. Quel que soit le type de format, le contenu se trouve via des hyperliens.
Googlebot commence par rechercher certains sites Web ; après cela, il analyse les hyperliens des pages pour trouver de nouvelles URL.
En parcourant les hyperliens, le crawler peut découvrir de nouveaux contenus qu'il peut inclure dans son index appelé Caffeine.
Il s'agit d'une base de données massive d'URL récemment découvertes qui peuvent être récupérées lorsque quelqu'un recherche des informations sur un site dont l'URL de contenu correspond parfaitement.
Classement des moteurs de recherche :
Lorsqu'une personne effectue une recherche sur Google, les moteurs de recherche analysent leurs index pour trouver un contenu pertinent, puis organisent le contenu pour résoudre la question.
L'ordre dans lequel les résultats de la recherche sont classés en fonction de leur pertinence est appelé classement.
Vous pouvez empêcher les robots des moteurs de recherche d'explorer une partie particulière ou même la totalité de votre site ou demander aux moteurs de recherche de ne pas inclure de sites Web particuliers dans leur index.
Si vous souhaitez voir votre site Web indexé via les résultats des moteurs de recherche, vous devez vous assurer qu'il est accessible aux robots d'exploration et indexable.
Explorer les moteurs de recherche :
Comme vous l'avez vu, il est essentiel de s'assurer que votre site est exploré, indexé et exploré pour qu'il apparaisse dans les résultats de recherche. Si votre entreprise site est dans l'index du site que vous consultez, c'est une bonne idée de commencer par regarder le nombre de pages dans les résultats de recherche.

Cela peut vous donner un excellent aperçu de la façon dont Google a exploré votre site Web pour trouver chaque page vers laquelle vous souhaitez créer un lien, mais pas pour découvrir les pages que vous n'êtes pas.
Résultats : le nombre de résultats affichés par Google n'est pas exact. Cependant, il vous permet de comprendre les pages trouvées sur votre site et la façon dont elles s'affichent sur les pages de résultats de recherche.
L'outil permet aux tendances de conception Web de télécharger des sitemaps sur votre site et de suivre le nombre de pages soumises à ajouter à l'index de Google et à d'autres aspects.
Si votre site n'apparaît pas sur la page de résultats, il y a de nombreuses raisons d'y jeter un coup d'œil :
- Votre site est nouveau et n'a pas encore été exploré.
- La navigation de votre site rend difficile la navigation efficace des robots d'exploration.
- Votre site Web contient un code élémentaire appelé directives du robot d'exploration qui bloque les instructions du robot d'exploration des moteurs de recherche.
- Votre site a été supprimé de la liste par Google car il utilisait des méthodes de spam.
Informez les moteurs de recherche de la manière dont ils peuvent accéder à votre site :
Si vous avez essayé Google Search Console ou le moteur de recherche avancé "site : domaine.com" et découvert que certaines de vos pages importantes ne sont pas répertoriées dans l'index ou que certaines pages qui ne sont pas aussi importantes n'ont pas été correctement indexées , il existe plusieurs façons de gérer Googlebot de la manière dont vous souhaitez que le contenu de votre site Web soit exploré.
Beaucoup se concentrent sur la garantie que Google trouvera leurs sites Web les plus importants, mais il est facile d'oublier ce qui est le plus susceptible d'être quelques pages que vous souhaitez éviter de trouver par Googlebot.
Il peut s'agir d'anciennes URL sans informations et de nombreuses URL (telles que des filtres et des paramètres de tri pour le commerce électronique), des codes promotionnels, des pages de mise en scène ou de test, et bien d'autres.
Conclusion:
Google fait un excellent travail pour déterminer l'URL correcte de votre site Web.
Cependant, vous pouvez également utiliser cette fonctionnalité dans la console de recherche pour indiquer à Google exactement comment vous préférez qu'ils gèrent vos sites Web.
Si vous utilisez cette fonctionnalité pour dire à Googlebot "explorer pour trouver des URL qui ne contiennent pas le paramètre ____", il essaie de convaincre Google de garder cette information hors de Googlebot et donc de supprimer ces pages des résultats de la recherche.
C'est ce que vous recherchez lorsque ces paramètres conduisent à des pages en double. Il existe cependant de meilleures alternatives à cela si vous souhaitez que ces pages soient incluses.
FAQ :
Trouvez-vous que le contenu de votre site Web disparaît lorsque vous utilisez le formulaire de connexion ?
Les moteurs de recherche ne pourront pas accéder aux pages protégées lorsque vous demandez aux utilisateurs de s'inscrire et de remplir des formulaires ou des enquêtes avant d'accéder à des sites Web particuliers. Un crawler a forcément besoin d'aide pour se connecter.
Devez-vous utiliser la page de recherche de Google ?
Les formulaires de recherche ne sont pas accessibles aux robots. Certaines personnes pensent que s'ils incluent des options de recherche sur leur site, les moteurs de recherche peuvent trouver ce que les utilisateurs recherchent.
Les moteurs de recherche peuvent-ils suivre la direction de votre site ?
Un robot d'exploration doit trouver votre site Web par le biais d'hyperliens vers d'autres sites Web et exiger une liste de liens qui dirigent l'utilisateur d'une page à une autre. Si vous avez une page que vous aimeriez que les moteurs de recherche trouvent, mais qu'elle n'est pas connectée à une autre page, c'est beaucoup plus efficace que de passer inaperçu.