
Optimisation du budget de crawl : 8 conseils pour arrêter le budget de crawl gaspillé
Publié: 2022-07-26Conclusion : si Google n'est pas en mesure d'explorer vos pages importantes, elles n'apparaîtront pas dans les résultats de recherche. Cela pourrait entraîner un trafic organique inférieur aux attentes et un classement déprimé.
L'optimisation du budget d'exploration permet à Google d'accéder, d'explorer et d'indexer plus facilement chacune de vos pages importantes afin que vous puissiez atteindre plus de clients via la recherche. Voici ce que vous devez savoir sur le budget de crawl, comment identifier le gaspillage de budget de crawl et ce que vous pouvez faire pour optimiser votre site afin d'éviter tout problème de budget de crawl SEO.
Qu'est-ce qu'un budget de crawl ?
Votre budget d'exploration fait référence au nombre de pages de votre site que Google explore chaque jour. Il est basé sur votre limite de vitesse d'exploration et votre demande d'exploration.
Votre limite de vitesse d'exploration correspond au nombre de pages que Google peut explorer sans affecter l'expérience utilisateur de votre site Web. Essentiellement, Google ne veut pas surcharger votre serveur de requêtes, il trouve donc un juste milieu entre ce que votre serveur peut gérer (les ressources de votre serveur) et combien il « veut » explorer votre site.
Votre demande de crawl est déterminée par la popularité d'une URL et sa fraîcheur. Si une URL est obsolète et que peu de personnes la recherchent, Google l'explorera moins fréquemment.
Bien que vous ne puissiez pas influer sur votre taux de crawl, vous pouvez avoir un impact sur votre demande de crawl en créant du nouveau contenu, en optimisant votre site avec les meilleures pratiques de référencement et en résolvant les problèmes de référencement tels que les 404 et les redirections inutiles.
Qu'est-ce que l'optimisation du budget de crawl ?
L'optimisation du budget d'exploration consiste à faciliter l'accès, l'exploration et l'indexation de votre site pour Googlebot en améliorant la navigabilité des robots d'exploration et en réduisant le gaspillage du budget d'exploration. Cela inclut la réduction des erreurs et des liens rompus, l'amélioration des liens internes, la non-indexation du contenu en double, etc.
Le budget d'exploration peut devenir un problème lorsque Google n'explore pas suffisamment de pages sur votre site ou ne les explore pas assez fréquemment.
Parce qu'il ne dispose que d'un certain nombre de ressources avec lesquelles travailler, Google ne peut allouer qu'un certain nombre de crawls à un site donné au cours d'une journée donnée. Si votre site est volumineux, cela signifie que Google ne dispose peut-être que des ressources nécessaires pour explorer quotidiennement une petite partie des pages de votre site. Cela peut avoir un impact sur le temps qu'il faut pour que vos pages soient indexées ou pour que les mises à jour de contenu soient reflétées dans les classements Google.
Heureusement, si vous pensez que votre site souffre de problèmes de budget de crawl Google, vous pouvez faire certaines choses pour optimiser votre site et tirer le meilleur parti de votre budget de crawl.
Comment vérifier votre rapport de statistiques de crawl
Vous pouvez identifier les problèmes de budget de crawl en vérifiant vos statistiques de crawl dans Google Search Console ou en analysant les journaux de fichiers de votre serveur.
L'affichage de votre rapport de statistiques d'exploration dans Google Search Console peut vous aider à mieux comprendre comment Googlebot interagit avec votre site Web. Voici comment vous pouvez l'utiliser pour voir ce que le robot d'exploration de Google a fait.
Ouvrez Google Search Console, connectez-vous et choisissez votre site Web. Sélectionnez ensuite l'option "Paramètres" dans le menu de la console de recherche.
Vous pouvez voir votre rapport de crawl pour les 90 derniers jours dans la section des statistiques de crawl. Ouvrez-le en cliquant sur "Ouvrir le rapport".
Ce que signifie votre rapport de statistiques de crawl
Maintenant que vous pouvez voir l'activité de Googlebot, il est temps de décoder les données. Voici une ventilation rapide du type d'informations que vous pouvez obtenir à partir de votre rapport d'exploration.
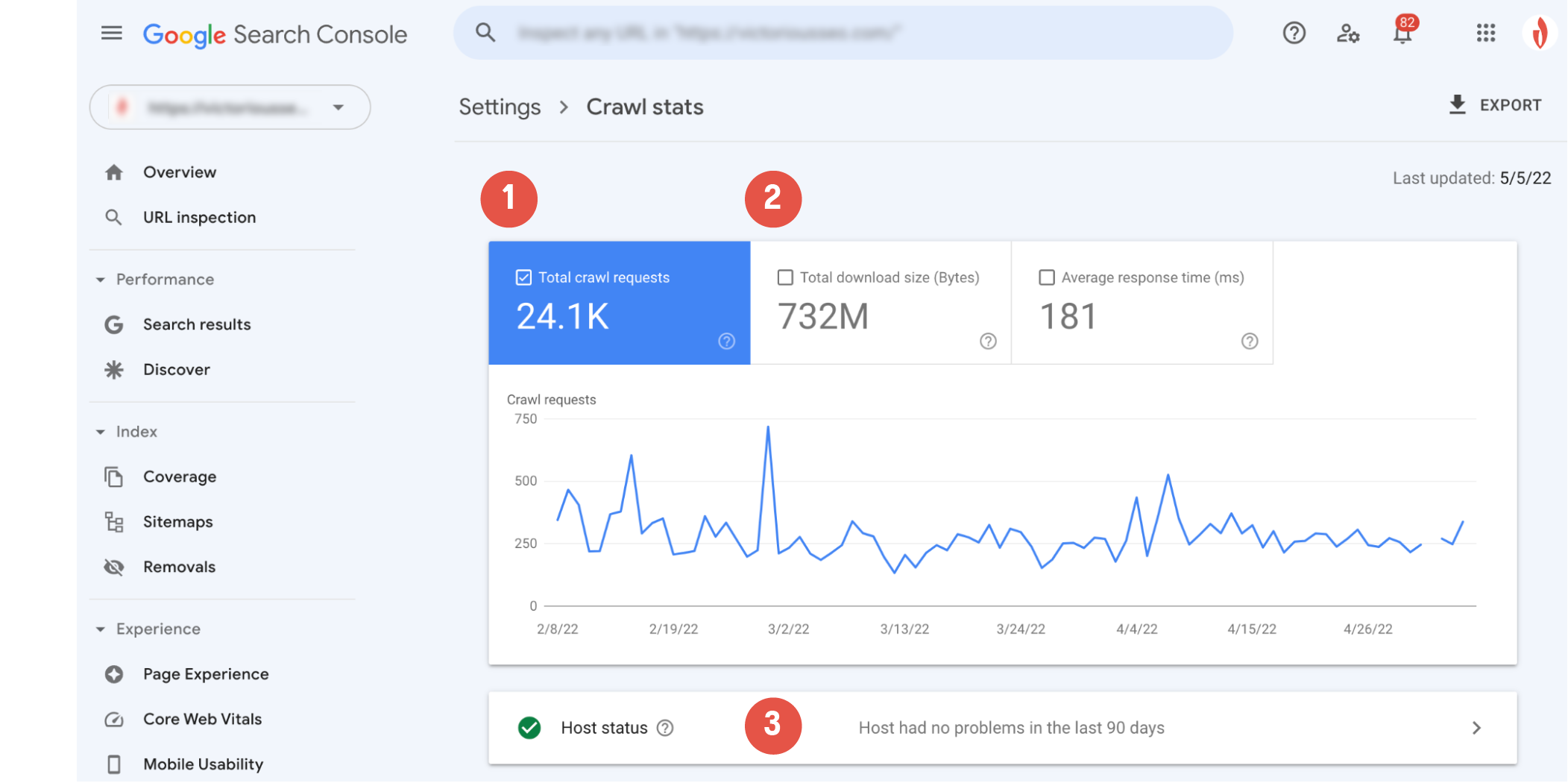
Le graphique d'exploration principal vous montrera une représentation visuelle de l'activité d'exploration de Googlebot. Ici, vous pouvez voir (1) le nombre de demandes d'exploration effectuées par Google au cours des 90 derniers jours et (2) le temps de réponse moyen du serveur de votre site et le nombre total d'octets téléchargés lors de l'exploration.
La section "Statut de l'hôte" (3) vous permettra de savoir si le crawler a rencontré des problèmes de disponibilité lors de l'accès à votre site Web.
Un cercle vert avec une coche blanche signifie que Googlebot n'a rencontré aucun problème et indique que votre hébergeur fonctionne correctement.
Un cercle blanc avec une coche verte signifie que Googlebot a rencontré un problème il y a plus d'une semaine, mais tout fonctionne bien maintenant.
Un cercle rouge avec un point d'exclamation blanc indique que Googlebot a rencontré au moins un problème important au cours de la semaine écoulée.
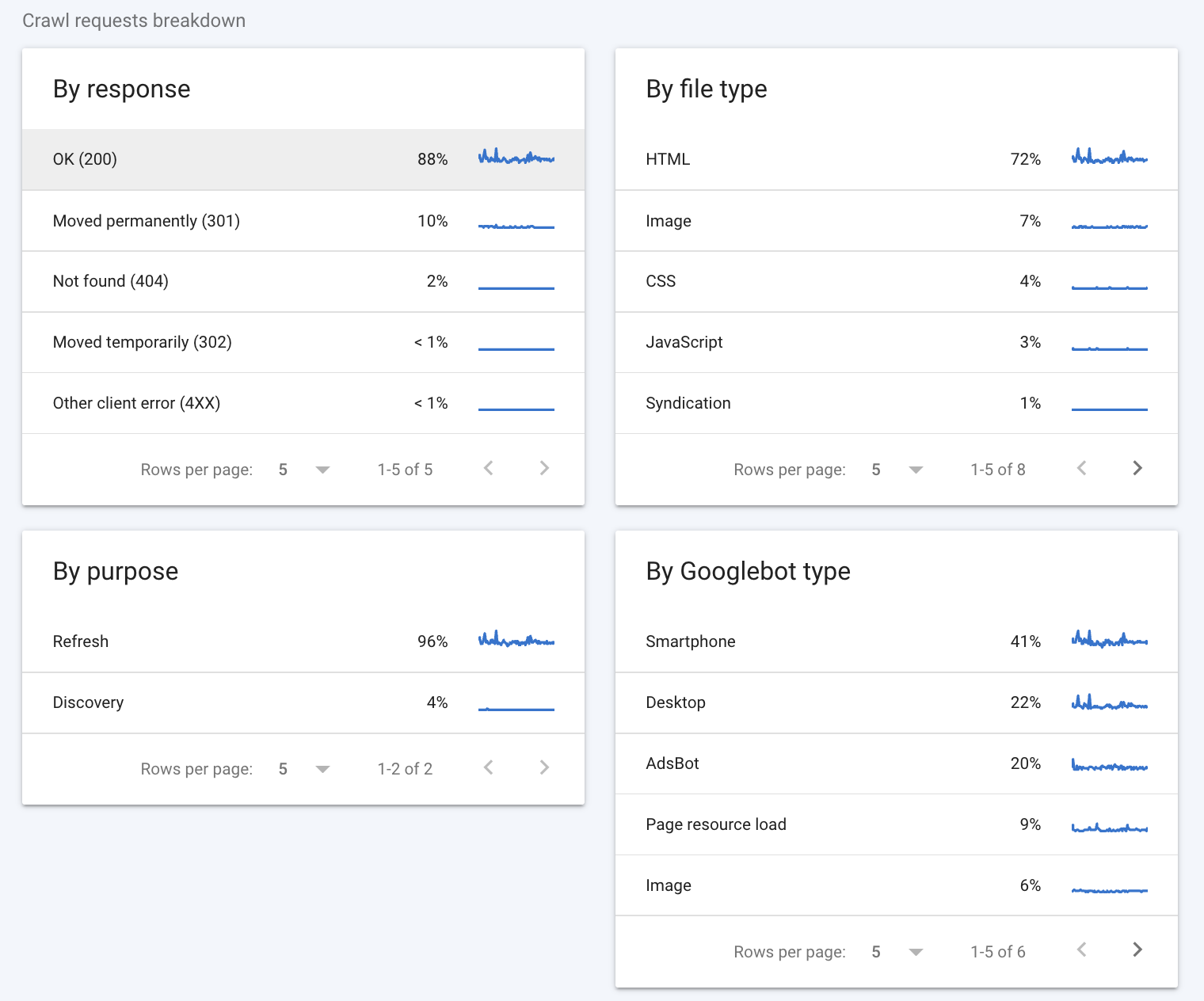
La ventilation des demandes d'exploration fournit des informations plus détaillées sur la manière dont les robots d'exploration de Google interagissent avec votre site.
Par réponse
La première section à consulter est la section "Par réponse". Cette section vous indique le type de réponses que Googlebot a reçues lorsqu'il a tenté d'explorer les pages de votre site. Google considère les éléments suivants comme de bonnes réponses :
- D'accord (200)
- Déménagé définitivement (301)
- Déménagé temporairement (302)
- Déménagé (autre)
- Non modifié (304)
Idéalement, la majorité des réponses devrait être de 200 (quelques 301 sont acceptables aussi). Des codes comme « Non trouvé (404) » indiquent qu'il y a probablement des impasses sur votre site Web, ce qui pourrait affecter votre budget de crawl.
Type de fichier
La section "Par type de fichier" vous indique le type de fichier rencontré par Googlebot lors de l'exploration. Les valeurs de pourcentage que vous voyez sont représentatives du pourcentage de réponses de ce type et non du pourcentage d'octets de chaque type de fichier.
Volontairement
La section "Par objectif" indique si la page explorée était une page déjà vue par le robot (une actualisation) ou une nouvelle pour le robot (une découverte).
Par type de Googlebot
Enfin, la section "Par type de Googlebot" vous indique les types d'agents d'exploration Googlebot utilisés pour effectuer des requêtes et explorer votre site. Par exemple, le type "Smartphone" indique une visite par le robot d'exploration pour smartphone de Google, tandis que le type "AdsBot" indique une exploration par l'un des robots d'exploration AdsBot de Google. En passant, vous pouvez toujours empêcher certains types de Googlebots d'explorer votre site Web en modifiant le fichier robots.txt.
Consultez le guide de Google sur les rapports d'exploration de la Search Console si vous souhaitez en savoir plus sur la façon d'interpréter les données de votre rapport d'exploration.
Comment savoir si vous gaspillez votre budget de crawl
Un moyen rapide de déterminer si l'optimisation du budget d'exploration aidera Googlebot à explorer davantage de vos pages est de voir quel pourcentage des pages de votre site sont réellement explorées par jour.
Découvrez exactement combien de pages uniques vous avez sur votre site Web et divisez-le par le nombre "moyenne explorée par jour". Si vous avez dix fois ou plus le nombre total de pages que de pages explorées par jour, vous devriez envisager une optimisation du budget d'exploration.
Si vous pensez que vous rencontrez des problèmes de budget d'exploration, commencez par consulter la section "Par réponse" pour voir quels types d'erreurs le robot d'exploration peut rencontrer. Vous devrez probablement effectuer une analyse plus approfondie pour voir exactement ce qui ronge votre budget. Un coup d'œil aux journaux de votre serveur peut vous donner plus d'informations sur la façon dont le robot d'exploration interagit avec votre site.
Vérifiez les journaux de votre serveur
Une autre façon de vérifier si vous gaspillez votre budget de crawl consiste à consulter les journaux du serveur de votre site. Ces journaux stockent chaque requête adressée à votre site Web, y compris les requêtes effectuées par Googlebot lorsqu'il explore votre site. L'analyse des journaux de votre serveur peut vous indiquer la fréquence à laquelle Google explore votre site Web, les pages auxquelles le robot d'exploration accède le plus souvent et le type d'erreurs rencontrées par le robot d'exploration.

Vous pouvez vérifier ces journaux manuellement, bien que la recherche de ces données puisse être un peu fastidieuse. Heureusement, plusieurs outils d'analyse de journaux différents peuvent vous aider à trier et à donner un sens à vos données de journal, comme l'analyseur de fichiers journaux SEMRush ou l'analyseur de fichiers journaux Screaming Frog SEO.
Crawl Budget SEO : 8 façons d'optimiser votre budget de crawl
Avez-vous découvert un budget de crawl gaspillé ? Les stratégies d'optimisation SEO du budget de crawl peuvent vous aider à réduire le gaspillage. Voici huit conseils pour vous aider à optimiser votre budget de crawl SEO pour de meilleures performances.
1. Ajustez les balises Robots.txt et Meta Robots
Une façon de limiter le gaspillage du budget d'exploration consiste à empêcher le robot d'exploration de Google d'explorer certaines pages en premier lieu. En éloignant Googlebot des pages que vous ne souhaitez pas indexer, vous pouvez concentrer son attention sur vos pages les plus importantes.
Le fichier robots.txt définit les limites des robots de recherche en déclarant les pages que vous souhaitez explorer et celles qui sont interdites. L'ajout d'une commande d'interdiction dans votre fichier robots.txt empêchera les robots d'exploration d'accéder, d'explorer et d'indexer les sous-répertoires spécifiés, sauf s'il existe des liens pointant vers ces pages.
Au niveau de la page, vous pouvez utiliser des balises meta robots pour ne pas indexer des pages particulières. Une balise noindex permet à Googlebot d'accéder à votre page et de suivre ses liens, mais elle indique à Googlebot de s'abstenir d'indexer la page elle-même. Cette balise va directement dans l'élément <head> de votre code HTML et ressemble à ceci :
<meta name=”robots” content=”noindex” />2. Élaguer le contenu
L'hébergement d'URL de faible valeur ou de contenu dupliqué sur votre site peut être un frein à votre budget de crawl. Une analyse approfondie des pages de votre site Web peut vous aider à identifier les pages inutiles qui peuvent grignoter le budget d'exploration et empêcher l'exploration et l'indexation de contenus plus précieux.
Qu'est-ce qui peut être qualifié d'URL de faible valeur ? Selon Google, les URL de faible valeur appartiennent généralement à l'une des catégories suivantes :
- Contenu dupliqué
- Identifiants de session
- Pages d'erreur logicielles
- Pages piratées
- Contenu de mauvaise qualité et spam
Le contenu dupliqué n'est pas toujours facile à identifier. Si la plupart du contenu d'une page est le même que celui d'une autre page - même si vous avez ajouté plus de contenu ou modifié certains mots - Google le considérera comme sensiblement similaire. Utilisez les balises meta noindex et les balises canoniques pour indiquer quelle page est l'original qui doit être indexé.
En mettant à jour, en supprimant ou en n'indexant pas le contenu susceptible d'être enregistré comme étant de faible valeur, vous donnez à Googlebot davantage d'opportunités d'explorer les pages de votre site qui sont vraiment importantes.
lecture recommandée
- SEO de contenu dupliqué : Comment vérifier le contenu dupliqué
- Pourquoi l'élagage de contenu aide votre référencement (et comment le faire)
3. Supprimer ou rendre JavaScript
Googlebot n'a aucun problème à lire le HTML, cependant, il doit restituer le JavaScript avant de pouvoir le lire et l'indexer. Ainsi, plutôt que d'explorer et d'indexer un élément JavaScript sur une page, Google analyse le contenu HTML de la page, puis place la page dans une file d'attente de rendu. Lorsqu'il aura le temps et les ressources à consacrer au rendu, il rendra le JavaScript et le "lira", puis l'indexera finalement. Cette étape supplémentaire ne prend pas seulement plus de temps, elle nécessite un budget de crawl plus important.
JavaScript peut également affecter les temps de chargement de vos pages, et puisque la vitesse du site et la charge du serveur ont un impact sur votre budget d'exploration, Google peut explorer votre site moins fréquemment que vous ne le souhaiteriez s'il est embourbé avec trop de JavaScript.
Pour conserver le budget d'exploration, vous pouvez ne pas indexer les pages avec JavaScript, supprimer vos éléments JavaScript ou utiliser un outil tel que Prerender qui affiche le contenu JavaScript dynamique sous forme de code HTML statique et facilite la compréhension et l'exploration par Google.
4. Supprimer les chaînes de redirection 301
Les redirections 301 sont un moyen utile et convivial pour le référencement de transférer le trafic et l'équité des liens d'une URL que vous souhaitez supprimer vers une autre URL pertinente.
Cependant, il est facile de créer accidentellement des chaînes de redirection si vous ne suivez pas vos redirections. Non seulement cela peut entraîner une augmentation des temps de chargement pour les visiteurs de votre site, mais cela peut également amener les robots à explorer plusieurs URL uniquement pour accéder à une page de contenu réel. Cela signifie que Google devra explorer chaque URL de la chaîne de redirection pour accéder à la page de destination, ce qui consommera votre budget d'exploration dans le processus.
Pour éviter cela, assurez-vous que toutes vos redirections pointent vers leur destination finale. C'est toujours une bonne pratique d'éviter d'utiliser des chaînes de redirection dans la mesure du possible. Pourtant, des erreurs se produisent, alors prenez le temps de parcourir votre site manuellement ou utilisez un outil de vérification de redirection pour repérer et nettoyer les chaînes de redirection 301.
5. Suivez les meilleures pratiques de plan de site XML
Votre sitemap partage toutes vos pages importantes avec les robots de recherche - ou du moins il le devrait. Les moteurs de recherche parcourent les sitemaps pour trouver facilement des pages. Alors que Google dit qu'il n'en a pas besoin pour trouver vos pages, c'est toujours une bonne idée d'en maintenir un.
Pour bien fonctionner, votre sitemap ne doit inclure que les pages que vous souhaitez indexer. Vous devez supprimer toutes les URL non indexées ou redirigées de votre sitemap. Un moyen simple de le faire est d'utiliser un sitemap XML généré dynamiquement. Les sitemaps générés dynamiquement se mettent à jour, vous n'avez donc pas à vous soucier de modifier le vôtre après chaque mise en œuvre de 301.
Si vous avez plusieurs sous-répertoires sur votre site, utilisez un index de plan de site qui contient des liens vers chacun des plans de site de vos sous-répertoires. Cela aide à présenter l'architecture de votre site Web et fournit une feuille de route facile à suivre pour les robots de recherche.
6. Créez une stratégie de liens internes
Les liens internes n'aident pas seulement les visiteurs du site à se déplacer ; ils créent également un chemin de déplacement plus clair pour les robots d'exploration.
Une stratégie de liens internes bien développée peut diriger les crawlers vers les pages que vous souhaitez explorer. Étant donné que les robots d'exploration utilisent des liens pour trouver d'autres pages, l'interconnexion de pages plus profondes avec un contenu de niveau supérieur peut aider le robot d'exploration à y accéder plus rapidement. Dans le même temps, la suppression des liens des pages de faible priorité que vous ne voulez pas grignoter dans votre budget de crawl peut aider à les repousser au fond de la file d'attente et à garantir que vos pages importantes soient explorées en premier.
7. Corrigez les erreurs du site
Les erreurs de site peuvent faire trébucher les robots de recherche et gaspiller un précieux budget d'exploration. Idéalement, vous voulez que le robot rencontre une page réelle ou une seule redirection vers cette page. S'il rencontre des chaînes de redirection ou une page d'erreur 404, vous gaspillez votre budget de crawl.
Utilisez votre rapport d'exploration Google Search Console pour identifier où le robot d'exploration rencontre des erreurs et de quels types d'erreurs il s'agit. La suppression de toutes les erreurs identifiables créera une expérience d'exploration plus fluide pour Googlebot.
8. Vérifiez les liens brisés
Une URL est essentiellement un pont entre deux pages. Il fournit au robot d'exploration des moteurs de recherche une voie pour trouver de nouvelles pages, mais certaines URL ne vont nulle part. Un lien brisé est une impasse pour les robots des moteurs de recherche et un gaspillage de votre budget d'exploration limité.
Prenez le temps de vérifier si votre site contient des liens brisés qui peuvent envoyer des robots de recherche vers des pages mortes et corrigez-les ou supprimez-les. En plus de réduire le gaspillage du budget de crawl, vous améliorerez également l'expérience de navigation des visiteurs en supprimant les liens brisés, donc faire une vérification périodique des liens est toujours une bonne idée.
Arrêtez le budget de crawl gaspillé avec un audit SEO
Vous vous sentez dépassé ou vous ne savez pas par où commencer pour optimiser le budget de crawl ou le référencement général de votre site ? Il n'est pas nécessaire d'y aller seul. Réservez une consultation avec Victorious dès aujourd'hui et laissez nos experts vous aider tout au long du processus d'audit SEO et de conception d'une stratégie pour optimiser le référencement de votre site.