
Démystifier 3 mythes courants derrière l'exploration de sites, l'indexation et les plans de site XML
Publié: 2018-03-07Beaucoup d'entre nous croient à tort que le lancement d'un site Web équipé d'un plan de site XML entraînera automatiquement l'exploration et l'indexation de toutes ses pages.
À cet égard, certains mythes et idées fausses s'accumulent. Les plus courants sont :
- Google explore automatiquement tous les sites et le fait rapidement.
- Lors de l'exploration d'un site Web, Google suit tous les liens et visite toutes ses pages et les inclut toutes dans l'index immédiatement.
- L'ajout d'un sitemap XML est le meilleur moyen d'explorer et d'indexer toutes les pages du site.
Malheureusement, faire entrer votre site Web dans l'index de Google est une tâche un peu plus compliquée. Lisez la suite pour avoir une meilleure idée du fonctionnement du processus d'exploration et d'indexation, et du rôle qu'un sitemap XML y joue.
Avant de nous atteler à démystifier les mythes mentionnés ci-dessus, apprenons quelques notions SEO essentielles :
L'exploration est une activité mise en œuvre par les moteurs de recherche pour suivre et rassembler des URL de partout sur le Web.
L'indexation est le processus qui suit l'exploration. Fondamentalement, il s'agit d'analyser et de stocker des données Web qui sont ensuite utilisées lors de la diffusion de résultats pour les requêtes des moteurs de recherche. L'index des moteurs de recherche est l'endroit où toutes les données Web collectées sont stockées pour une utilisation ultérieure.
Crawl Rank est la valeur que Google attribue à votre site et à ses pages. On ne sait toujours pas comment cette métrique est calculée par le moteur de recherche. Google a confirmé à plusieurs reprises que la fréquence d'indexation n'est pas liée au classement, il n'y a donc pas de corrélation directe entre une autorité de classement de sites Web et son rang d'exploration.
Les sites Web d'actualités, les sites au contenu précieux et les sites mis à jour régulièrement ont plus de chances d'être explorés régulièrement.
Le budget de crawl est une quantité de ressources de crawl que le moteur de recherche alloue à un site Web. Habituellement, Google calcule ce montant en fonction du Crawl Rank de votre site.
La profondeur d'exploration est la mesure dans laquelle Google explore un niveau de site Web lors de son exploration.
La priorité d'exploration est un nombre ordinal attribué à une page de site qui signifie son importance par rapport à l'exploration.
Maintenant, connaissant toutes les bases du processus, débarrassons-nous de ces 3 mythes derrière les sitemaps XML, l'exploration et l'indexation !
Table des matières
- Mythe 1. Google explore automatiquement tous les sites et le fait rapidement.
- Plats à emporter
- Mythe 2. L'ajout d'un sitemap XML est le meilleur moyen d'explorer et d'indexer toutes les pages du site.
- Plats à emporter
- Mythe 3. Un sitemap XML peut résoudre tous les problèmes d'exploration et d'indexation.
- Plats à emporter
Mythe 1. Google explore automatiquement tous les sites et le fait rapidement.
Google affirme que lorsqu'il s'agit de collecter des données Web, il est agile et flexible.
Mais à vrai dire, car pour le moment, il y a des milliards de pages sur le Web, techniquement, le moteur de recherche ne peut pas toutes les explorer rapidement.
Sélection des sites Web auxquels allouer le budget de crawl
L'algorithme intelligent de Google (alias Crawl Budget) distribue les ressources du moteur de recherche et décide quels sites valent la peine d'être explorés et lesquels ne le sont pas.
Habituellement, Google donne la priorité aux sites Web de confiance qui correspondent aux exigences définies et servent de base pour définir la façon dont les autres sites se mesurent.
Donc, si vous avez un site Web tout juste sorti du four, ou un site Web avec un contenu gratté, dupliqué ou léger, les chances qu'il soit correctement exploré sont assez faibles.
Les facteurs importants qui peuvent également influencer l'allocation du budget de crawl sont :
- la taille du site Web,
- sa santé générale (cet ensemble de métriques est déterminé par le nombre d'erreurs que vous pouvez avoir sur chaque page),
- et le nombre de liens entrants et internes.
Pour augmenter vos chances d'obtenir un budget de crawl, assurez-vous que votre site répond à toutes les exigences de Google mentionnées ci-dessus, ainsi que d'optimiser son efficacité de crawl (voir la section suivante de l'article).
Prévision du calendrier d'exploration
Google n'annonce pas ses projets d'exploration des URL Web. Aussi, il est difficile de deviner la périodicité avec laquelle le moteur de recherche visite certains sites.
Il se peut que pour un site, il effectue des explorations au moins une fois par jour, tandis que pour un autre, il est visité une fois par mois ou même moins fréquemment.
- La périodicité des crawls dépend de :
- la qualité du contenu du site,
- la nouveauté et la pertinence des informations fournies par un site Web,
- et sur l'importance ou la popularité que le moteur de recherche pense des URL du site.
En tenant compte de ces facteurs, vous pouvez essayer de prédire la fréquence à laquelle Google visitera votre site Web.
Le rôle des liens externes/internes et des sitemaps XML
En tant que voies, les Googlebots utilisent des liens qui relient les pages du site et le site Web les uns aux autres. Ainsi, le moteur de recherche atteint des trillions de pages interconnectées qui existent sur le Web.
Le moteur de recherche peut commencer à analyser votre site Web à partir de n'importe quelle page, pas nécessairement à partir de la page d'accueil. La sélection du point d'entrée du crawl dépend de la source d'un lien entrant. Supposons que certaines de vos pages de produits contiennent de nombreux liens provenant de divers sites Web. Google relie les points et visite ces pages populaires au premier tour.
Un sitemap XML est un excellent outil pour construire une structure de site bien pensée. De plus, cela peut rendre le processus d'exploration du site plus ciblé et intelligent.
Fondamentalement, le plan du site est un hub avec tous les liens du site. Chaque lien qui y est inclus peut être équipé de quelques informations supplémentaires : la date de la dernière mise à jour, la fréquence de mise à jour, sa relation avec d'autres URL du site, etc.
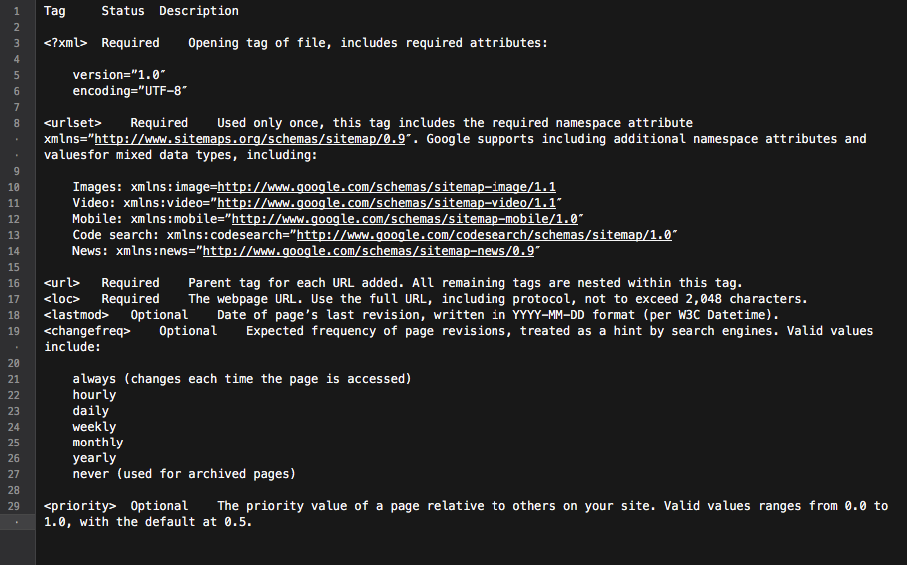 Tout cela fournit aux Googlebots une feuille de route détaillée pour l'exploration de sites Web et rend l'exploration plus informée. De plus, tous les principaux moteurs de recherche donnent la priorité aux URL répertoriées dans un sitemap.
Tout cela fournit aux Googlebots une feuille de route détaillée pour l'exploration de sites Web et rend l'exploration plus informée. De plus, tous les principaux moteurs de recherche donnent la priorité aux URL répertoriées dans un sitemap.
En résumé, pour placer les pages de votre site sur le radar de Googlebot, vous devez créer un site Web avec un excellent contenu et optimiser sa structure de liens internes.
Plats à emporter
• Google n'explore pas automatiquement tous vos sites Web.
• La périodicité de l'exploration du site dépend de l'importance ou de la popularité du site et de ses pages.
• La mise à jour du contenu incite Google à visiter un site Web plus fréquemment.
• Les sites Web qui ne correspondent pas aux exigences des moteurs de recherche ont peu de chances d'être explorés correctement.
• Les sites Web et les pages de site qui n'ont pas de liens internes/externes sont généralement ignorés par les robots des moteurs de recherche.
• L'ajout d'un sitemap XML peut améliorer le processus d'exploration du site Web et le rendre plus intelligent.
Mythe 2. L'ajout d'un sitemap XML est le meilleur moyen d'explorer et d'indexer toutes les pages du site.
Chaque propriétaire de site Web souhaite que Googlebot visite toutes les pages importantes du site (à l'exception de celles qui ne sont pas indexées), et explore instantanément le contenu nouveau et mis à jour.
Cependant, le moteur de recherche a sa propre vision des priorités d'exploration du site.
Lorsqu'il s'agit de vérifier un site Web et son contenu, Google utilise un ensemble d'algorithmes appelés budget de crawl. Fondamentalement, il permet au moteur de recherche de scanner les pages du site, tout en utilisant judicieusement ses propres ressources.
Vérification d'un budget de crawl de site Web
Il est assez facile de comprendre comment votre site est exploré et si vous avez des problèmes de budget d'exploration.
Il vous suffit de :
- compter le nombre de pages sur votre site et dans votre sitemap XML,
- visitez Google Search Console, accédez à la section Crawl -> Crawl Stats et vérifiez combien de pages sont explorées quotidiennement sur votre site,
- divisez le nombre total de pages de votre site par le nombre de pages explorées par jour.
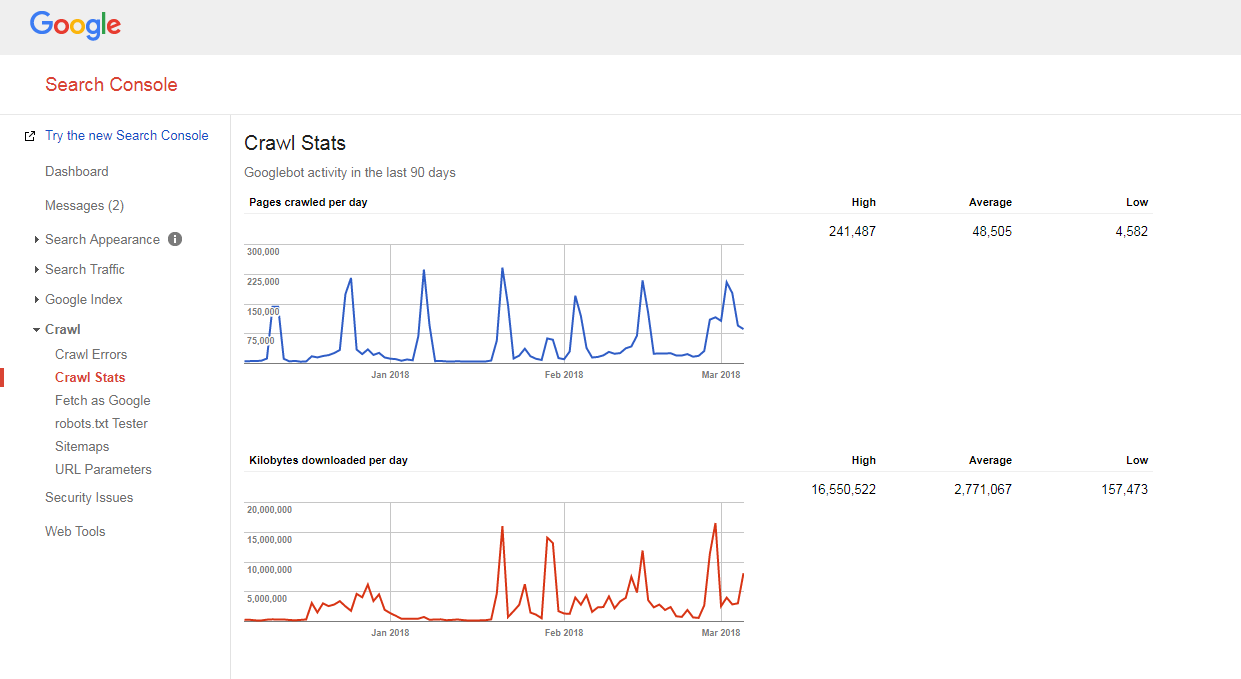 Si le nombre que vous avez est supérieur à 10 (il y a 10 fois plus de pages sur votre site que ce que Google crawle quotidiennement), nous avons une mauvaise nouvelle pour vous : votre site Web a des problèmes de crawl.
Si le nombre que vous avez est supérieur à 10 (il y a 10 fois plus de pages sur votre site que ce que Google crawle quotidiennement), nous avons une mauvaise nouvelle pour vous : votre site Web a des problèmes de crawl.
Mais avant d'apprendre à les réparer, vous devez comprendre une autre notion, c'est-à-dire…
Profondeur de crawl
La profondeur de l'exploration est la mesure dans laquelle Google continue d'explorer un site Web jusqu'à un certain niveau.
Généralement, la page d'accueil est considérée comme étant de niveau 1, une page à 1 clic est de niveau 2, etc.
Les pages de niveau profond ont un Pagerank inférieur (ou n'en ont pas du tout) et sont moins susceptibles d'être explorées par Googlebot. Habituellement, le moteur de recherche ne creuse pas plus loin que le niveau 4.
Dans le scénario idéal, une page spécifique devrait être à 1-4 clics de la page d'accueil ou des catégories principales du site. Plus le chemin d'accès à cette page est long, plus les moteurs de recherche doivent allouer de ressources pour y accéder.
Si vous êtes sur un site Web, Google estime que le chemin est beaucoup trop long, il arrête d'explorer davantage.
Optimisation de la profondeur de crawl et du budget
Pour éviter que Googlebot ne ralentisse, optimisez le budget et la profondeur de crawl de votre site Web, vous devez :
- corriger toutes les erreurs 404, JS et autres erreurs de page ;
Un nombre excessif d'erreurs de page peut ralentir considérablement la vitesse du robot d'exploration de Google. Pour trouver toutes les principales erreurs du site, connectez-vous à votre panneau Google (Bing, Yandex) Webmaster Tools et suivez toutes les instructions données ici.

- optimiser la pagination ;
Si vous avez des listes de pagination trop longues ou si votre schéma de pagination ne permet pas de cliquer plus loin que quelques pages dans la liste, le robot d'exploration du moteur de recherche est susceptible d'arrêter de creuser une telle pile de pages.
De plus, s'il y a peu d'éléments sur une telle page, elle peut être considérée comme une page à contenu léger et ne sera pas parcourue.
- vérifier les filtres de navigation ;
Certains schémas de navigation peuvent être accompagnés de plusieurs filtres qui génèrent de nouvelles pages (par exemple, des pages filtrées par navigation en couches). Bien que ces pages puissent avoir un potentiel de trafic organique, elles peuvent également créer une charge indésirable sur les robots des moteurs de recherche.
La meilleure façon de résoudre ce problème est de limiter les liens systématiques vers les listes filtrées. Idéalement, vous devriez utiliser 1 à 2 filtres maximum. Par exemple, si vous avez un magasin avec 3 filtres LN (couleur/taille/genre), vous devez autoriser la combinaison systématique de seulement 2 filtres (par exemple, couleur-taille, sexe-taille). Si vous avez besoin d'ajouter des combinaisons de plusieurs filtres, vous devez ajouter manuellement des liens vers ceux-ci.
- Optimiser les paramètres de suivi dans les URL ;
Divers paramètres de suivi d'URL (par exemple '?source=cettepage') peuvent créer des pièges pour les robots, car ils génèrent une quantité massive de nouvelles URL. Ce problème est typique des pages avec des blocs « produits similaires » ou « histoires connexes », où ces paramètres sont utilisés pour suivre le comportement des utilisateurs.
Pour optimiser l'efficacité du crawl dans ce cas, il est conseillé de transmettre les informations de suivi derrière un '#' à la fin de l'URL. De cette façon, une telle URL restera inchangée. De plus, il est également possible de rediriger des URL avec des paramètres de suivi vers les mêmes URL mais sans suivi.
- supprimer les redirections 301 excessives ;
Supposons que vous disposiez d'un grand nombre d'URL liées sans barre oblique finale. Lorsque le robot du moteur de recherche visite ces pages, il est redirigé vers la version avec une barre oblique.
Ainsi, le bot doit faire deux fois plus que ce qu'il est censé faire, et finalement il peut abandonner et arrêter de ramper. Pour éviter cela, essayez simplement de mettre à jour tous les liens de votre site chaque fois que vous modifiez les URL.
Priorité d'exploration
Comme indiqué ci-dessus, Google donne la priorité aux sites Web à explorer. Il n'est donc pas étonnant qu'il fasse la même chose avec les pages d'un site Web exploré.
Pour la majorité des sites Web, la page avec la priorité de crawl la plus élevée est la page d'accueil.
Cependant, comme indiqué précédemment, dans certains cas, il peut également s'agir de la catégorie la plus populaire ou de la page de produit la plus visitée. Pour trouver les pages qui obtiennent le plus grand nombre de crawls par Googlebot, il suffit de regarder les journaux de votre serveur.
Bien que Google n'annonce pas officiellement que les facteurs susceptibles d'influencer la priorité de crawl d'une page de site sont :
- inclusion dans un sitemap XML (et ajouter les balises Priority* pour les pages les plus importantes),
- le nombre de liens entrants,
- le nombre de liens internes,
- popularité de la page (nombre de visites),
- Classement.
Mais même après avoir ouvert la voie aux robots des moteurs de recherche pour explorer votre site Web, ils peuvent toujours l'ignorer. Lisez la suite pour savoir pourquoi.
Pour mieux comprendre comment crawler la priorité, regardez ce keynote virtuel de Gary Illyes.
En ce qui concerne les balises de priorité dans un sitemap XML, elles peuvent être ajoutées manuellement ou à l'aide de la fonctionnalité intégrée de la plate-forme sur laquelle votre site est basé. En outre, certaines plates-formes prennent en charge les extensions / applications de sitemap XML tierces qui simplifient le processus.
À l'aide de la balise Priorité du sitemap XML, vous pouvez attribuer les valeurs suivantes aux différentes catégories de pages du site :
- 0.0-0.3 aux pages utilitaires, au contenu obsolète et à toutes les pages d'importance mineure,
- 0.4-0.7 à vos articles de blog, FAQ et pages d'informations, pages de catégories et sous-catégories d'importance secondaire, et
- 0.8-1.0 aux principales catégories de votre site, aux principales pages de destination et à la page d'accueil.
Plats à emporter
• Google a sa propre vision des priorités du processus d'exploration.
• Une page qui est censée entrer dans l'index du moteur de recherche doit être à 1-4 clics de la page d'accueil, des catégories principales du site ou des pages du site les plus populaires.
• Pour empêcher Googlebot de ralentir et d'optimiser le budget d'exploration et la profondeur d'exploration de votre site Web, vous devez rechercher et corriger les erreurs 404, JS et autres erreurs de page, optimiser la pagination du site et les filtres de navigation, supprimer les redirections 301 excessives et optimiser les paramètres de suivi dans les URL.
• Pour améliorer la priorité d'exploration des pages importantes du site, assurez-vous qu'elles sont incluses dans un sitemap XML (avec des balises de priorité) et bien liées aux autres pages du site, qu'elles contiennent des liens provenant d'autres sites Web pertinents et faisant autorité.
Mythe 3. Un sitemap XML peut résoudre tous les problèmes d'exploration et d'indexation.
Tout en étant un bon outil de communication qui alerte Google sur les URL de votre site et les moyens de les atteindre, un sitemap XML ne donne AUCUNE garantie que votre site sera visité par les robots des moteurs de recherche (sans parler de l'inclusion de toutes les pages du site dans l'Index) .
En outre, vous devez comprendre que les sitemaps ne vous aideront pas à améliorer le classement de votre site. Même si une page est explorée et incluse dans l'index du moteur de recherche, ses performances de classement dépendent de nombreux autres facteurs (liens internes et externes, contenu, qualité du site, etc.).
Cependant, lorsqu'il est utilisé correctement, un sitemap XML peut considérablement améliorer l'efficacité de l'exploration de votre site. Vous trouverez ci-dessous quelques conseils sur la façon de maximiser le potentiel SEO de cet outil.
Être cohérent
Lors de la création d'un sitemap, n'oubliez pas qu'il servira de feuille de route pour les robots d'exploration Google. Par conséquent, il est important de ne pas tromper le moteur de recherche en fournissant de mauvaises directions.
Par exemple, vous pouvez occasionnellement inclure dans votre sitemap XML des pages utilitaires (pages Contactez-nous, ou TOS, pages de connexion, page de restauration de mot de passe perdu, pages de partage de contenu , etc.).
Ces pages sont généralement cachées de l'indexation avec des balises meta robots noindex ou interdites dans le fichier robots.txt.
Ainsi, les inclure dans un plan de site XML ne fera que confondre Googlebots, ce qui peut influencer négativement le processus de collecte des informations sur votre site Web.
Mettre à jour régulièrement
La plupart des sites Web sur le Web changent presque tous les jours. Surtout le site Web de commerce électronique avec des produits et des catégories qui circulent régulièrement sur et hors du site.
Pour que Google reste bien informé, vous devez maintenir à jour votre sitemap XML.
Certaines plates-formes (Magento, Shopify) ont soit une fonctionnalité intégrée qui vous permet de mettre à jour périodiquement vos sitemaps XML, soit prennent en charge certaines solutions tierces capables de faire cette tâche.
Par exemple, dans Magento 2, vous pouvez connaître la périodicité des cycles de mise à jour du sitemap. Lorsque vous le définissez dans les paramètres de configuration de la plateforme, vous signalez au crawler que les pages de votre site sont mises à jour à un certain intervalle de temps (horaire, hebdomadaire, mensuel) et que votre site a besoin d'un autre crawl.
Cliquez ici pour en savoir plus à ce sujet.
Mais rappelez-vous que bien que la définition de la priorité et de la fréquence des mises à jour du sitemap soit utile, elles peuvent ne pas rattraper les changements réels et parfois ne pas donner une image fidèle.
C'est pourquoi assurez-vous que votre sitemap reflète toutes les modifications récemment apportées.
 Segmentez le contenu du site et définissez les bonnes priorités d'exploration
Segmentez le contenu du site et définissez les bonnes priorités d'exploration
Google travaille dur pour mesurer la qualité globale du site et afficher uniquement les sites Web les meilleurs et les plus pertinents.
Mais comme cela arrive souvent, tous les sites ne sont pas créés égaux et capables de fournir une valeur réelle.
Disons qu'un site Web peut contenir 1 000 pages, et seulement 50 d'entre elles sont de niveau «A». Les autres sont soit purement fonctionnels, ont un contenu obsolète ou pas de contenu du tout.
Si Google commence à explorer un tel site Web, il décidera probablement qu'il est assez trash en raison du pourcentage élevé de pages de faible valeur, de spam ou obsolètes.
C'est pourquoi, lors de la création d'un sitemap XML, il est conseillé de segmenter le contenu du site Web et de guider les robots des moteurs de recherche uniquement vers les zones du site dignes d'intérêt.
Et comme vous vous en souvenez peut-être, les balises de priorité, attribuées aux pages de site les plus importantes de votre plan de site XML, peuvent également être d'une grande aide.
Plats à emporter
• Lors de la création d'un sitemap, assurez-vous de ne pas inclure de pages cachées à l'indexation avec des balises meta noindex robots ou non autorisées dans le fichier robots.txt.
• Mettez à jour les sitemaps XML (manuellement ou automatiquement) juste après avoir apporté des modifications à la structure et au contenu du site Web.
• Segmentez le contenu de votre site pour n'inclure que des pages de niveau « A » dans le plan du site.
• Définir la priorité d'exploration pour différents types de pages.
C'est essentiellement ça.
Vous avez quelque chose à dire sur le sujet ? N'hésitez pas à partager votre opinion sur l'exploration, l'indexation ou les sitemaps dans la section des commentaires ci-dessous.