
Comment automatiser l'orchestration des droits d'accès dans les compartiments AWS S3
Publié: 2023-01-13Il y a des années, lorsque les serveurs Unix sur site avec de grands systèmes de fichiers étaient chose courante, les entreprises élaboraient des règles et des stratégies de gestion de dossiers étendues pour administrer les droits d'accès à différents dossiers pour différentes personnes.
Habituellement, la plate-forme d'une organisation sert différents groupes d'utilisateurs avec des intérêts, des restrictions de niveau de confidentialité ou des définitions de contenu complètement distincts. Dans le cas des organisations mondiales, cela pourrait même signifier séparer le contenu en fonction de l'emplacement, donc fondamentalement, entre les utilisateurs appartenant à différents pays.

D'autres exemples typiques pourraient inclure :
- séparation des données entre les environnements de développement, de test et de production
- contenu de vente non accessible à un large public
- contenu législatif spécifique à un pays qui ne peut pas être vu ou accessible depuis une autre région
- contenu lié au projet où les "données de leadership" ne doivent être fournies qu'à un groupe limité de personnes, etc.
Il existe une liste potentiellement interminable d'exemples de ce type. Le fait est qu'il existe toujours une sorte de besoin d'orchestrer les droits d'accès aux fichiers et aux données entre tous les utilisateurs auxquels la plate-forme donne accès.
Dans le cas des solutions sur site, il s'agissait d'une tâche de routine. L'administrateur du système de fichiers vient de définir certaines règles, d'utiliser un outil de choix, puis les personnes ont été mappées dans des groupes d'utilisateurs, et les groupes d'utilisateurs ont été mappés dans une liste de dossiers ou de points de montage auxquels ils pourront accéder. En cours de route, le niveau d'accès a été défini comme un accès en lecture seule ou en lecture et écriture.
En examinant maintenant les plates-formes cloud AWS, il est évident de s'attendre à ce que les gens aient des exigences similaires en matière de restrictions d'accès au contenu. La solution à ce problème doit être, cependant maintenant, différente. Les fichiers ne résistent plus sur les serveurs Unix mais dans le cloud (et potentiellement accessibles non seulement à toute l'organisation mais même au monde entier), et le contenu n'est pas stocké dans des dossiers mais dans des buckets S3.

Ci-dessous décrit est une alternative pour aborder ce problème. Il s'appuie sur l'expérience du monde réel que j'ai eue lorsque je concevais de telles solutions pour un projet concret.
Approche simple mais largement manuelle
Une façon de résoudre ce problème sans aucune automatisation est relativement simple et directe :
- Créez un nouveau bucket pour chaque groupe de personnes distinct.
- Attribuez des droits d'accès au compartiment afin que seul ce groupe spécifique puisse accéder au compartiment S3.
C'est certainement possible si l'exigence est d'aller avec une résolution très simple et rapide. Il y a cependant quelques limites à connaître.
Par défaut, seuls 100 compartiments S3 au maximum peuvent être créés sous un compte AWS. Cette limite peut être étendue à 1 000 en soumettant une augmentation de la limite de service au ticket AWS. Si ces limites ne préoccupent pas votre cas de mise en œuvre particulier, vous pouvez laisser chacun de vos utilisateurs de domaine distincts fonctionner sur un compartiment S3 distinct et l'appeler un jour.
Les problèmes peuvent survenir s'il existe des groupes de personnes ayant des responsabilités interfonctionnelles ou simplement des personnes qui ont besoin d'accéder au contenu de plusieurs domaines en même temps. Par example:
- Analystes de données évaluant le contenu des données pour plusieurs domaines, régions, etc.
- L'équipe de test a partagé des services au service de différentes équipes de développement.
- Utilisateurs de rapports nécessitant de créer une analyse de tableau de bord sur différents pays de la même région.
Comme vous pouvez l'imaginer, cette liste peut à nouveau s'allonger autant que vous pouvez l'imaginer, et les besoins des organisations peuvent générer toutes sortes de cas d'utilisation.
Plus cette liste devient complexe, plus l'orchestration des droits d'accès sera nécessaire pour accorder à tous ces différents groupes différents droits d'accès aux différents compartiments S3 de l'organisation. Des outils supplémentaires seront nécessaires, et peut-être même une ressource dédiée (administrateur) devra maintenir les listes de droits d'accès et les mettre à jour chaque fois qu'un changement est demandé (ce qui sera très souvent, surtout si l'organisation est grande).
Alors, comment réaliser la même chose de manière plus organisée et automatisée ?
Introduire des balises pour les buckets
Si l'approche compartiment par domaine ne fonctionne pas, toute autre solution se retrouvera avec des compartiments partagés pour davantage de groupes d'utilisateurs. Dans de tels cas, il est nécessaire de construire toute la logique d'attribution des droits d'accès dans un domaine facile à modifier ou à mettre à jour dynamiquement.
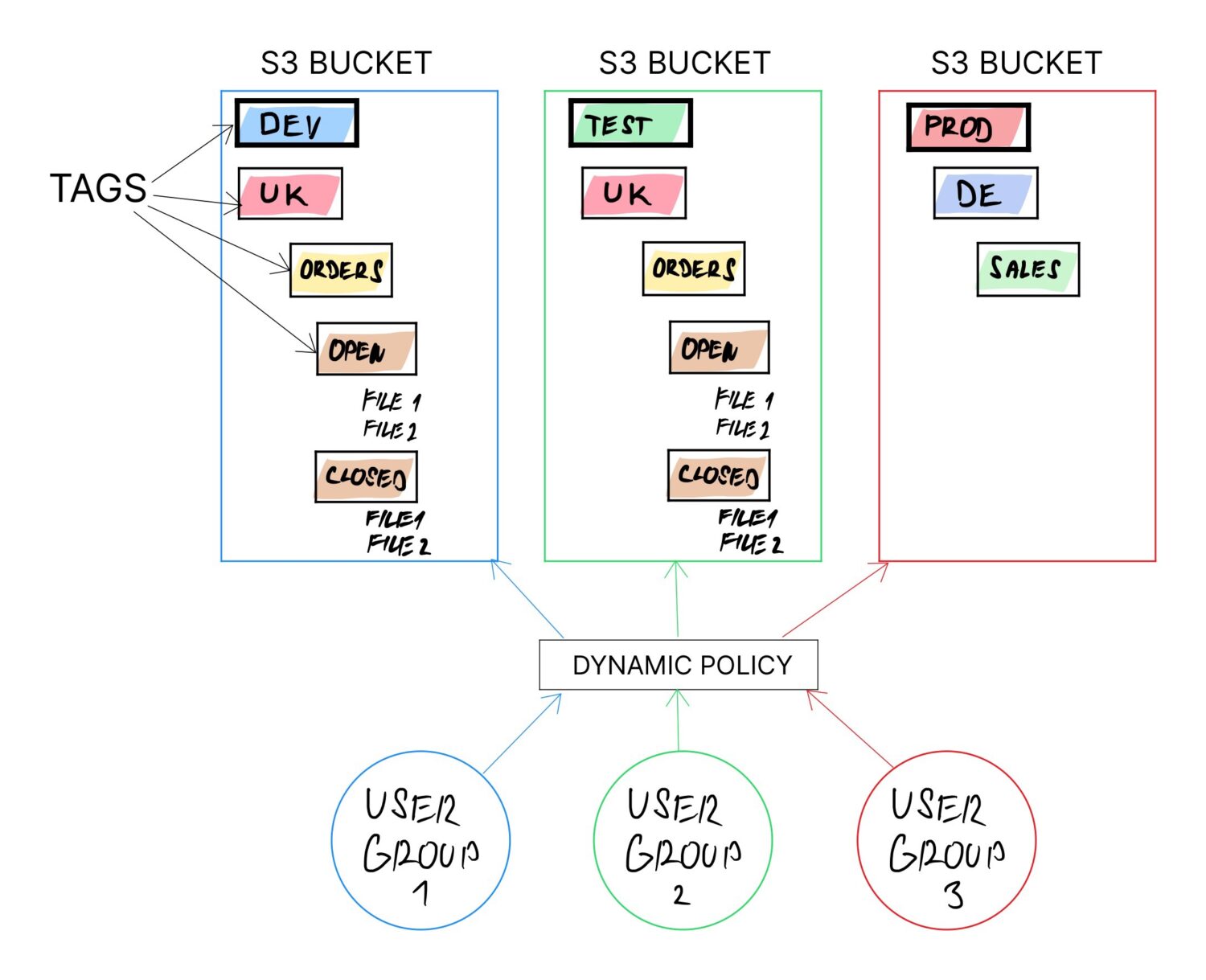
L'une des façons d'y parvenir consiste à utiliser des balises sur les compartiments S3. Il est recommandé d'utiliser les balises dans tous les cas (ne serait-ce que pour permettre une catégorisation plus facile de la facturation). Cependant, la balise peut être modifiée à tout moment dans le futur pour n'importe quel bucket.
Si toute la logique est construite sur la base des balises du compartiment et que le reste dépend de la configuration des valeurs des balises, la propriété dynamique est assurée car on peut redéfinir l'objectif du compartiment simplement en mettant à jour les valeurs des balises.
Quel type de balises utiliser pour que cela fonctionne ?
Cela dépend de votre cas d'utilisation concret. Par example:
- Il peut être nécessaire de séparer les compartiments par type d'environnement. Ainsi, dans ce cas, l'un des noms de balises doit être quelque chose comme "ENV" et avec les valeurs possibles "DEV", "TEST", "PROD", etc.
- Peut-être que vous voulez séparer l'équipe en fonction du pays. Dans ce cas, une autre balise sera "COUNTRY" et valorise un nom de pays.
- Ou vous pouvez séparer les utilisateurs en fonction du service fonctionnel auquel ils appartiennent, comme les analystes commerciaux, les utilisateurs de l'entrepôt de données, les scientifiques des données, etc. Vous créez donc une balise avec le nom "USER_TYPE" et la valeur respective.
- Une autre option pourrait être que vous souhaitiez définir explicitement une structure de dossiers fixe pour des groupes d'utilisateurs spécifiques qu'ils sont tenus d'utiliser (pour ne pas créer leur propre encombrement de dossiers et s'y perdre au fil du temps). Vous pouvez le refaire avec des balises, où vous pouvez spécifier plusieurs répertoires de travail comme : "data/import", "data/processed", "data/error", etc.
Idéalement, vous souhaitez définir les balises afin qu'elles puissent être combinées de manière logique et les faire former une structure de dossiers complète sur le bucket.

Par exemple, vous pouvez combiner les balises suivantes des exemples ci-dessus pour créer une structure de dossiers dédiée pour différents types d'utilisateurs de différents pays avec des dossiers d'importation prédéfinis qu'ils sont censés utiliser :
- /<ENV>/<USER_TYPE>/<COUNTRY>/<UPLOAD>
En changeant simplement la valeur <ENV>, vous pouvez redéfinir l'objectif de la balise (si elle doit être affectée à l'écosystème de l'environnement de test, au développement, à la production, etc.)
Cela permettra l'utilisation du même compartiment pour de nombreux utilisateurs différents. Les buckets ne prennent pas explicitement en charge les dossiers, mais ils prennent en charge les "étiquettes". Ces étiquettes fonctionnent finalement comme des sous-dossiers car les utilisateurs doivent passer par une série d'étiquettes pour accéder à leurs données (comme ils le feraient avec des sous-dossiers).
Créez des politiques dynamiques et mappez des balises de compartiment à l'intérieur
Après avoir défini les balises sous une forme utilisable, l'étape suivante consiste à créer des stratégies de compartiment S3 qui utiliseraient les balises.
Si les politiques utilisent les noms de balises, vous créez quelque chose appelé "politiques dynamiques". Cela signifie essentiellement que votre politique se comportera différemment pour les compartiments avec différentes valeurs de balise auxquelles la politique fait référence dans le formulaire ou les espaces réservés.
Cette étape implique évidemment un codage personnalisé des politiques dynamiques, mais vous pouvez simplifier cette étape à l'aide de l'outil d'éditeur de politiques Amazon AWS, qui vous guidera tout au long du processus.
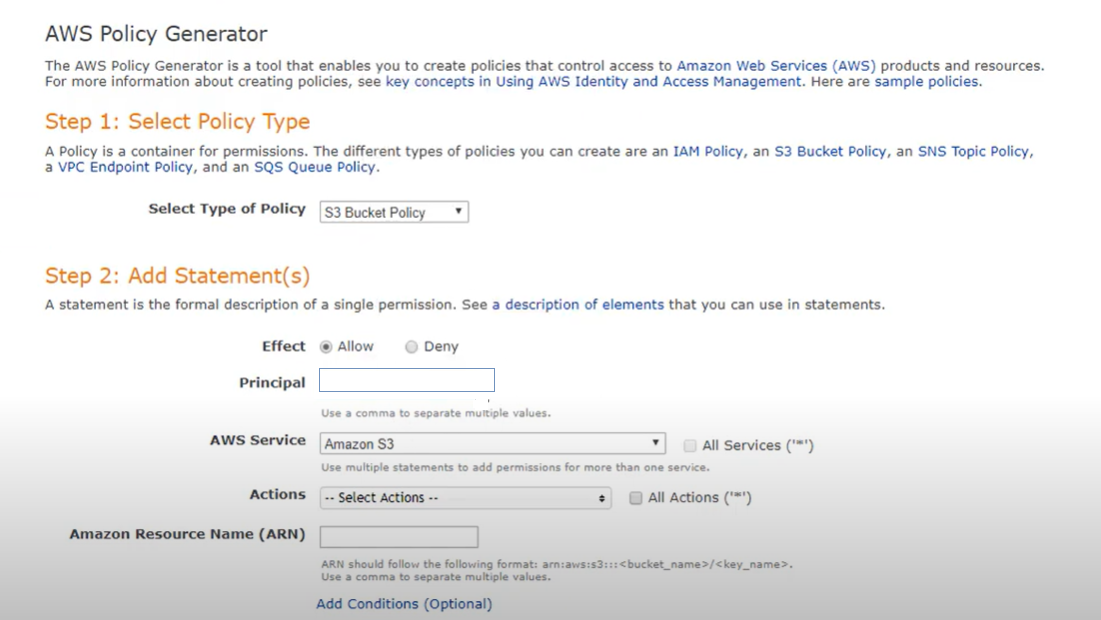
Dans la politique elle-même, vous souhaiterez coder les droits d'accès concrets qui seront appliqués au compartiment et le niveau d'accès de ces droits (lecture, écriture). La logique lira les balises sur les compartiments et créera la structure de dossiers sur le compartiment (créant des étiquettes basées sur les balises). Sur la base des valeurs concrètes des balises, les sous-dossiers seront créés et les droits d'accès requis seront attribués le long de la ligne.
L'avantage d'une telle politique dynamique est que vous pouvez créer une seule politique dynamique, puis attribuer la même politique dynamique à plusieurs compartiments. Cette politique se comportera différemment pour les compartiments avec des valeurs de balises différentes, mais elle sera toujours conforme à vos attentes pour un compartiment avec de telles valeurs de balises.
C'est un moyen vraiment efficace de gérer les attributions de droits d'accès de manière organisée et centralisée pour un grand nombre de compartiments, où l'on s'attend à ce que chaque compartiment suive certaines structures de modèles convenues à l'avance et qui seront utilisées par vos utilisateurs dans l'ensemble de l'organisation.
Automatisez l'intégration de nouvelles entités
Après avoir défini des politiques dynamiques et les avoir affectées aux buckets existants, les utilisateurs peuvent commencer à utiliser les mêmes buckets sans risquer que des utilisateurs de différents groupes n'accèdent pas au contenu (stocké sur le même bucket) situé sous une structure de dossiers où ils n'ont pas accès.
De plus, pour certains groupes d'utilisateurs avec un accès plus large, il sera facile d'accéder aux données car elles seront toutes stockées sur le même compartiment.
La dernière étape consiste à simplifier au maximum l'intégration de nouveaux utilisateurs, de nouveaux compartiments et même de nouvelles balises. Cela a conduit à un autre codage personnalisé, qui, cependant, n'a pas besoin d'être trop complexe, en supposant que votre processus d'intégration a des règles très claires qui peuvent être encapsulées avec une logique d'algorithme simple et directe (au moins vous pouvez prouver de cette manière que votre le processus a une certaine logique et ce n'est pas fait de manière trop chaotique).
Cela peut être aussi simple que de créer un script exécutable par la commande AWS CLI avec les paramètres nécessaires pour intégrer avec succès une nouvelle entité dans la plateforme. Il peut même s'agir d'une série de scripts CLI, exécutables dans un ordre spécifique, comme par exemple :
- create_new_bucket(<ENV>,<ENV_VALUE>,<COUNTRY>,<COUNTRY_VALUE>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<type_utilisateur>,<pays>,<env>)
- etc.
Tu obtiens le point.
Un conseil de pro
Il y a un Pro Tip si vous le souhaitez, qui peut être facilement appliqué en plus de ce qui précède.
Les politiques dynamiques peuvent être utilisées non seulement pour attribuer des droits d'accès aux emplacements de dossier, mais également pour attribuer automatiquement des droits de service pour les compartiments et les groupes d'utilisateurs !
Il suffirait d'étendre la liste des balises sur les compartiments, puis d'ajouter des droits d'accès à la politique dynamique pour utiliser des services spécifiques pour des groupes concrets d'utilisateurs.
Par exemple, il peut y avoir un groupe d'utilisateurs qui ont également besoin d'accéder au serveur de cluster de base de données spécifique. Cela peut sans aucun doute être réalisé par des politiques dynamiques tirant parti des tâches de compartiment, d'autant plus si les accès aux services sont pilotés par une approche basée sur les rôles. Ajoutez simplement au code de stratégie dynamique une partie qui traitera les balises concernant la spécification du cluster de base de données et attribuera directement les privilèges d'accès à la stratégie à ce cluster de base de données et à ce groupe d'utilisateurs particuliers.
De cette façon, l'intégration d'un nouveau groupe d'utilisateurs sera exécutable uniquement par cette seule politique dynamique. De plus, comme elle est dynamique, la même politique peut être réutilisée pour l'intégration de nombreux groupes d'utilisateurs différents (censés suivre le même modèle mais pas nécessairement les mêmes services).
Vous pouvez également consulter ces commandes AWS S3 pour gérer les compartiments et les données.