
Tirez le meilleur parti d'Apache Solr : une exploration technique de l'indexation de la recherche
Publié: 2023-02-21Une fonction de recherche améliore l'expérience utilisateur d'un site Web en permettant à l'utilisateur de trouver facilement et rapidement ce qu'il recherche. Plus encore pour les grands sites Web, les sites de commerce électronique et les sites à contenu dynamique (sites d'actualités, blogs).
Apache Solr est l'une des plateformes de recherche les plus populaires utilisées par les sites Web de toutes tailles. Il s'agit d'un moteur de recherche open source basé sur Java qui vous permet de rechercher dans de grandes quantités de données, telles que des articles, des produits, des avis clients, etc. Examinez plus en détail Apache Solr dans cet article.
Consultez cet article pour savoir comment configurer Apache Solr dans Drupal

Pourquoi Apache Solr est-il si populaire ?
Apache Solr est rapide et flexible et permet la recherche en texte intégral, la mise en surbrillance des résultats (met en surbrillance le terme de recherche correspondant), la recherche à facettes (une recherche plus précise), l'indexation en temps réel (permet d'indexer immédiatement le nouveau contenu), le regroupement dynamique ( organise les résultats de recherche en groupes), l'intégration de bases de données, les fonctionnalités NoSQL (base de données non relationnelle) et la gestion de documents riches (pour indexer une grande variété de formats de documents tels que PDF, MS Office, Open Office).
Quelques faits bons à savoir sur Apache Solr :
- Il a été initialement développé par CNET networks, inc. comme moteur de recherche pour leurs sites Web et leurs articles. Plus tard, il a été open-source et est devenu un projet Apache de haut niveau.
- Prend en charge plusieurs langages de programmation tels que PHP, Java, Python et Ruby. Il fournit également des API pour ces langages.
- A un support intégré pour la recherche géospatiale, permettant de rechercher du contenu en fonction de son emplacement. Particulièrement utile pour les sites tels que les sites immobiliers, les sites de voyage, etc.
- Prend en charge les fonctionnalités de recherche avancées telles que la vérification orthographique, la saisie semi-automatique et la recherche personnalisée via des API et des plugins.
- Utilise Lucene pour l'indexation et la recherche.
Qu'est-ce que la lucène
Apache Lucene est une bibliothèque de recherche Java open source qui vous permet d'ajouter facilement la recherche ou la récupération d'informations à l'application. Il est polyvalent, puissant, précis et fonctionne sur un algorithme de recherche efficace.
Bien que connu pour ses capacités de recherche en texte intégral, Lucene peut également être utilisé pour la classification de documents, l'analyse de données et la recherche d'informations. Il prend également en charge de nombreuses langues autres que l'anglais comme l'allemand, le français, l'espagnol, le chinois, le japonais, etc.
Qu'est-ce que l'indexation ?
Tous les moteurs de recherche commencent par l'indexation. L'indexation est le traitement des données originales dans une recherche de références croisées très efficace pour faciliter une recherche rapide.
Les moteurs de recherche n'indexent pas directement les données. Les textes sont d'abord décomposés en jetons (éléments atomiques). La recherche est le processus de consultation de l'index de recherche et de récupération du document correspondant à la requête.
Avantages de l'indexation
- Recherche d'informations rapide et précise (collecte, analyse et stocke)
- Sans indexation, le moteur de recherche prend plus de temps pour scanner chaque document
Flux d'indexation
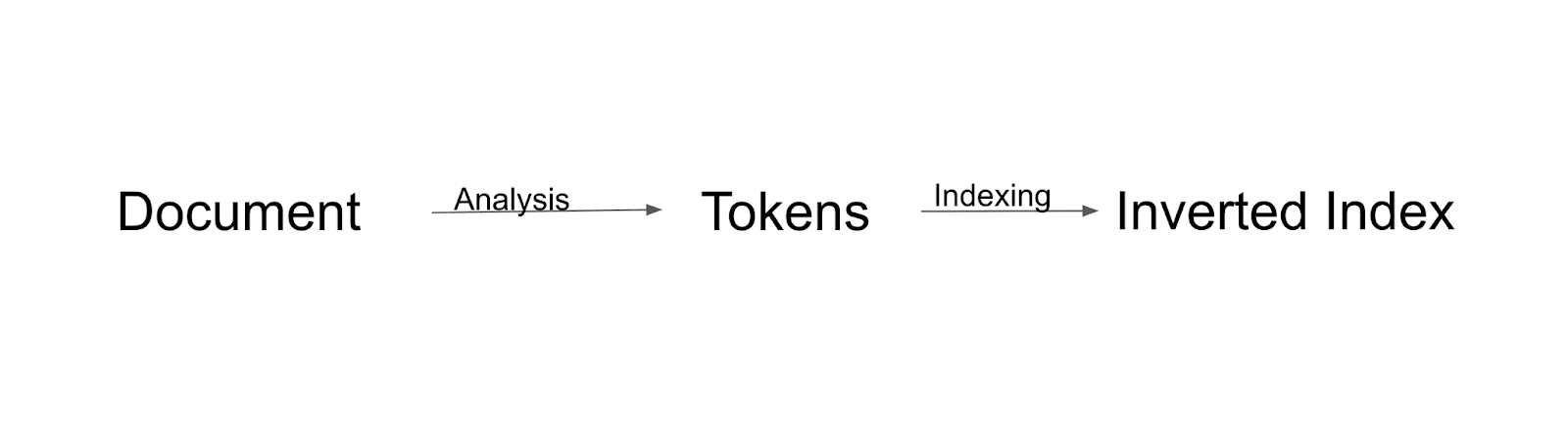
Tout d'abord, le document sera analysé et divisé en jetons. Tous ces jetons seront indexés à l'index inversé. L'index inversé est un moyen par lequel Solr construit l'index.
Comment fonctionne l'indexation inversée
Considérons que nous avons 3 documents :
- J'aime le chocolat (J 1)
- J'ai commandé un gâteau au chocolat (J 2)
- J'ai préparé un gros gâteau à la vanille (J 3)
La façon dont il est symbolisé est comme indiqué dans la 2e colonne du tableau ci-dessous.

« Chocolat » est disponible en D1 et D2
« Cake » est disponible en D2 et D3
"Big" est disponible en D3
"Commandé" est disponible en D2
"Préparé" est disponible en D3
"Vanille" est disponible en D3
Vous remarquerez que des mots comme "je", "amour" ne sont pas symbolisés. Ceux-ci sont appelés mots vides qui ne seront pas indexés ou consultables par Solr.
Ainsi, lorsque quelqu'un recherche le terme "Gâteau au chocolat", le moteur examine l'index. Au lieu de rechercher le document, il examine d'abord l'index pour voir à quels documents appartiennent les mots "Chocolate" et "Cake". Cela facilite et accélère la récupération du document particulier uniquement. C'est ce qu'on appelle l'indexation inversée.
Schéma de stockage
Apache Solr utilise un schéma de stockage basé sur des documents et stocke chaque élément de données dans un document distinct au sein d'une collection. Cela permet un stockage et une récupération efficaces et flexibles des données.
Dans Drupal, chaque nœud est considéré comme un document. Ainsi, lorsque vous indexez votre nœud sur Apache Solr, il est considéré comme un document. Chaque document peut contenir plusieurs champs. Lucene n'a pas de schéma global commun. Cela signifie que vous pouvez indexer n'importe quel type de champ dans chaque document dans Apache Solr.

Comment installer Apache Solr
- Tout d'abord, assurez-vous que Java est installé sur votre système.
- Ensuite, installons Solr à partir d'ici : https://solr.apache.org/downloads.html
- Téléchargez et extrayez Solr.
- Exécutez cette commande sur le dossier Solr.
◦ bin/solr -e techproducts
Cela créera un noyau factice pour la démonstration et démarrera également le serveur Solr.
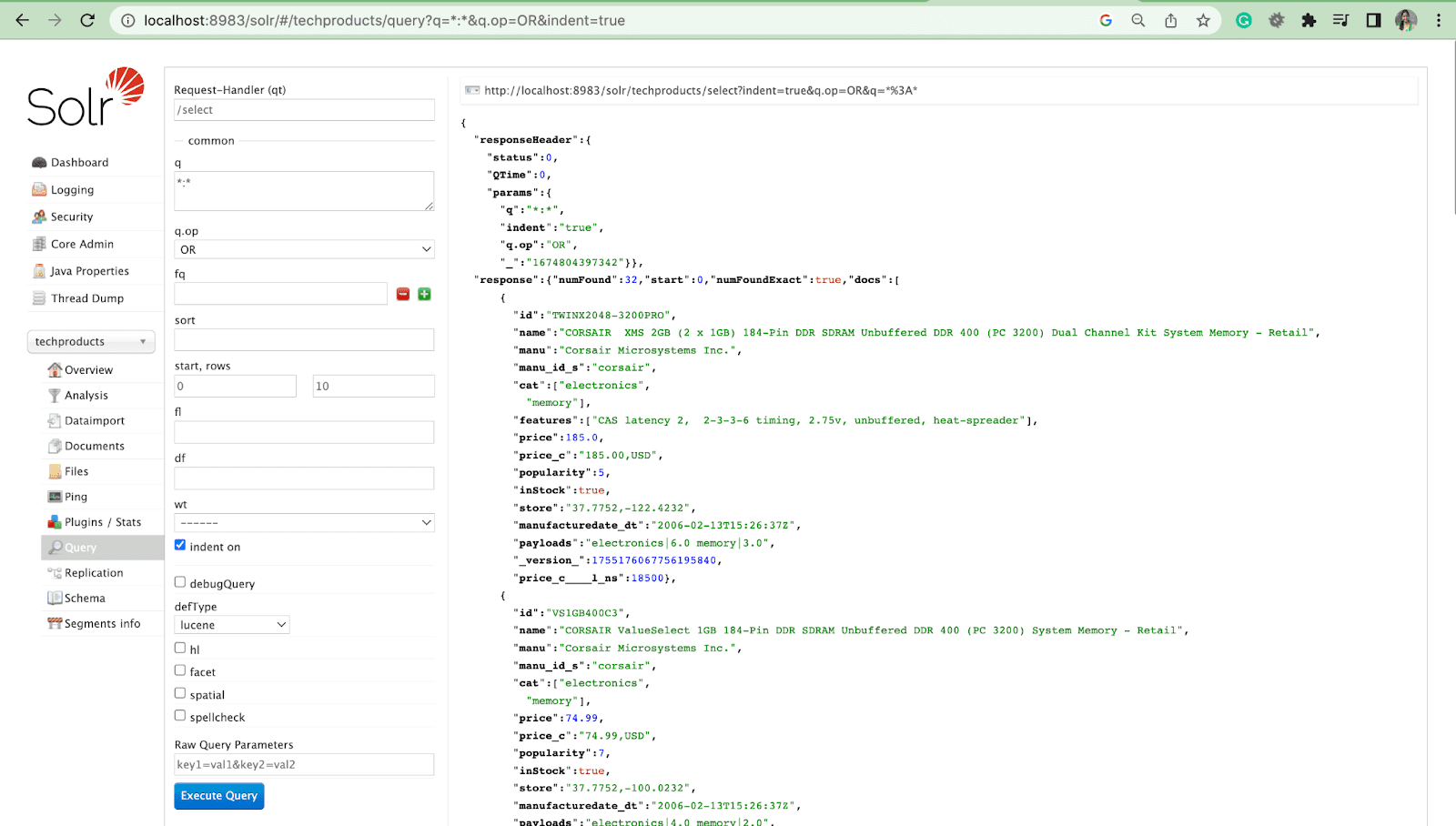
- Une fois le serveur démarré, allez dans votre navigateur et tapez « http://localhost:8983/ ».
- Assurez-vous que Solr est installé avec succès avec un noyau factice.
Structure du répertoire
Une fois que vous avez installé Solr, vous verrez de nombreux dossiers comme :

Docs - contient de la documentation sur Solr
Dist - Fichier .jar principal de Solr
Contrib - contient des plugins complémentaires et des fonctionnalités spécialisées de Solr
Bin - scripts de Solr
Exemple - contient des fonctionnalités de démonstration de solr
Serveur - cœur de Solr. Contient l'application Web Solr, les journaux, le noyau Solr
Fichiers de configuration
Pour créer un noyau, nous avons besoin de deux fichiers obligatoires.
- Schéma.xml
- Solrconfig.xml
Schéma.xml
- Il contiendra les types de champs que vous prévoyez de prendre en charge et comment ces types doivent être analysés.
Solrconfig.xml
- Contient divers paramètres qui contrôlent le comportement d'un noyau Solr comme le gestionnaire de requêtes, le répartiteur de requêtes, les composants de requête, les gestionnaires de mise à jour, etc.
Interrogation dans Solr
Voyons maintenant comment interroger les résultats de Solr dans l'interface utilisateur d'administration de Solr.
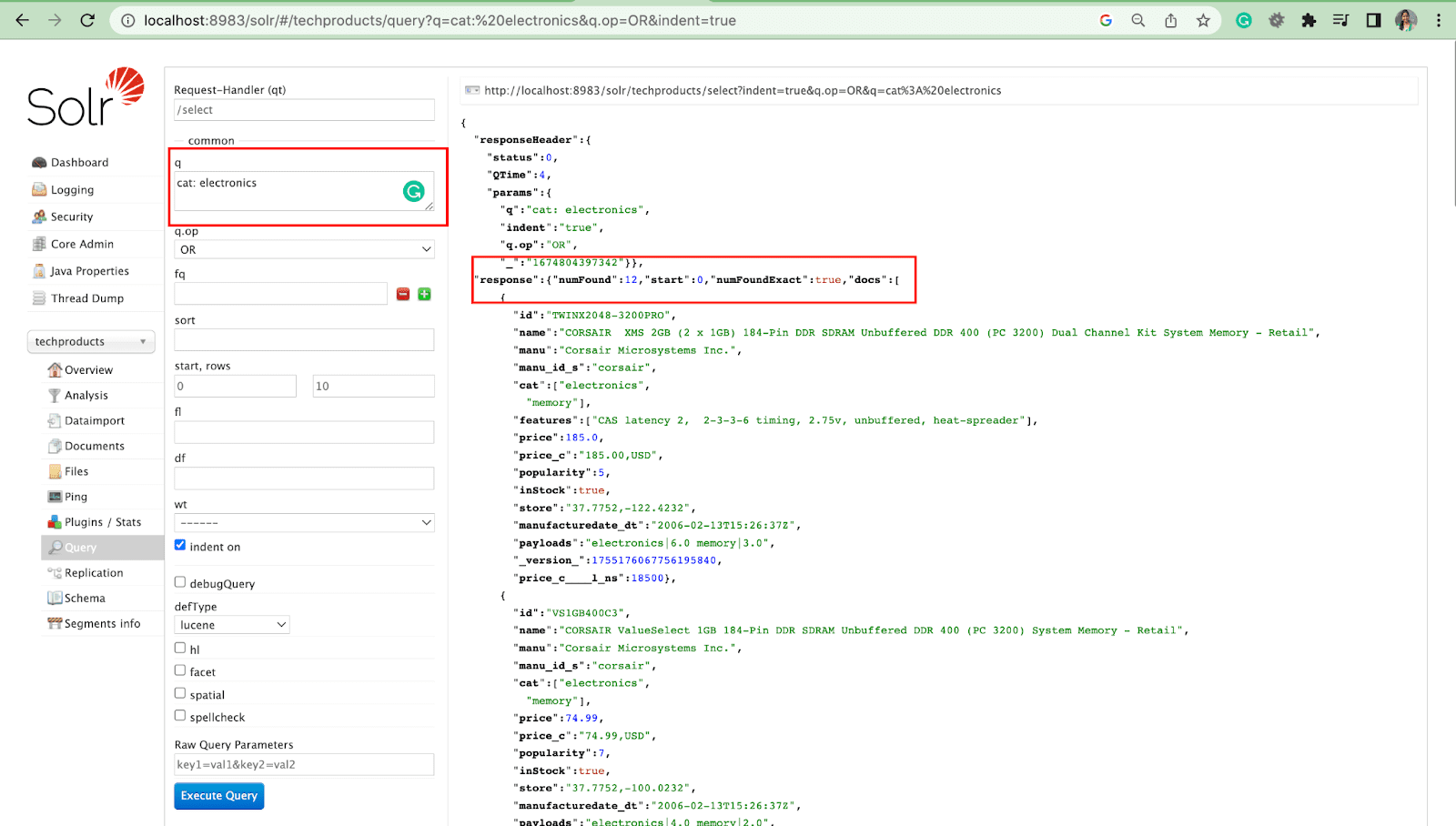
Paramètre de requête
- Les paramètres locaux sont des arguments dans une demande Solr qui sont spécifiques à un paramètre de requête.
Par exemple : chat : électronique
Paramètre de requête avec opérations
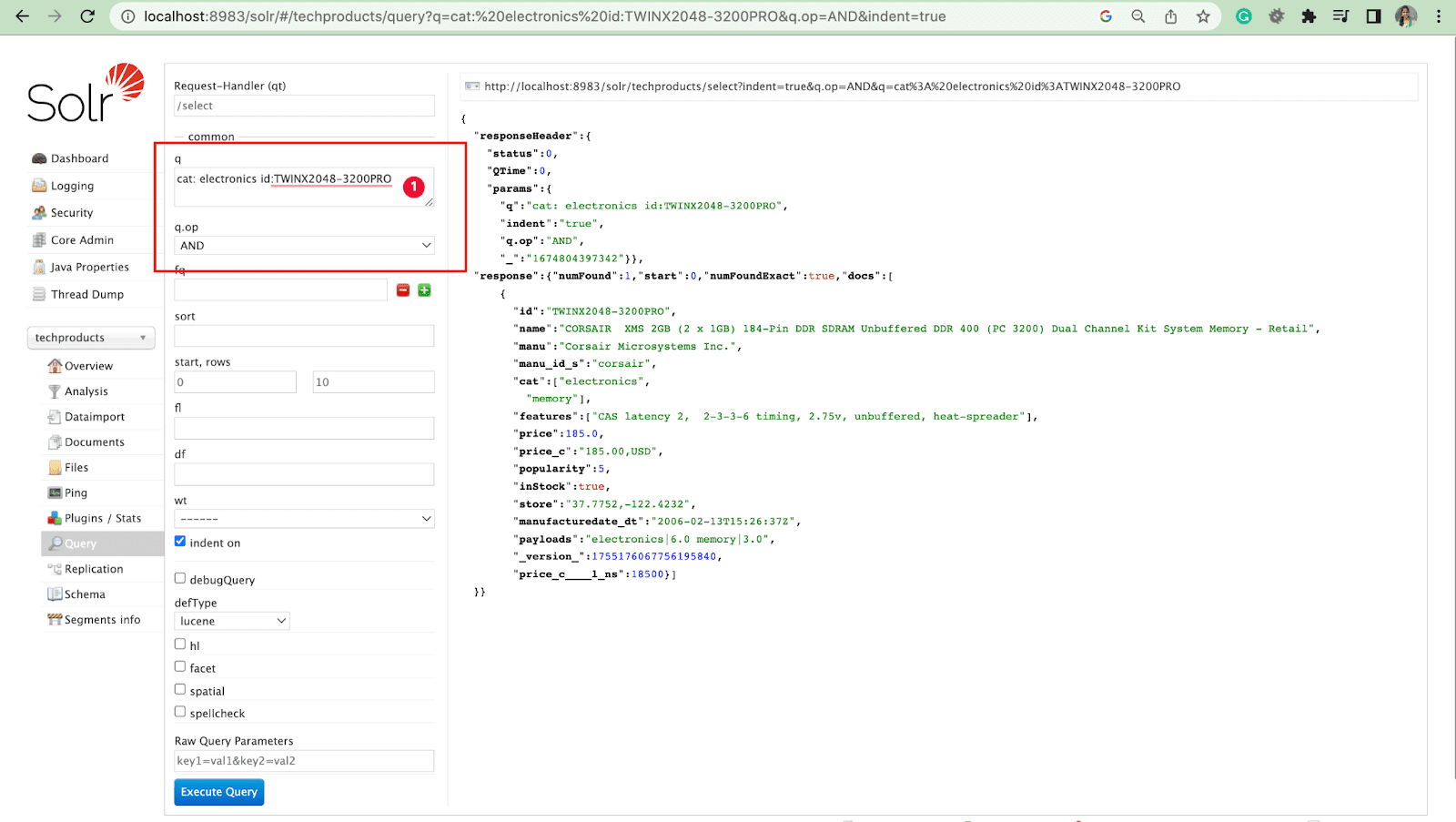
- Nous pouvons interroger plusieurs champs avec opération.
Par exemple : cat : identifiant électronique : TWINX2048-3200PRO avec q.op ET
[OU]
chat : électronique ET id : TWINX2048-3200PRO
[OU]
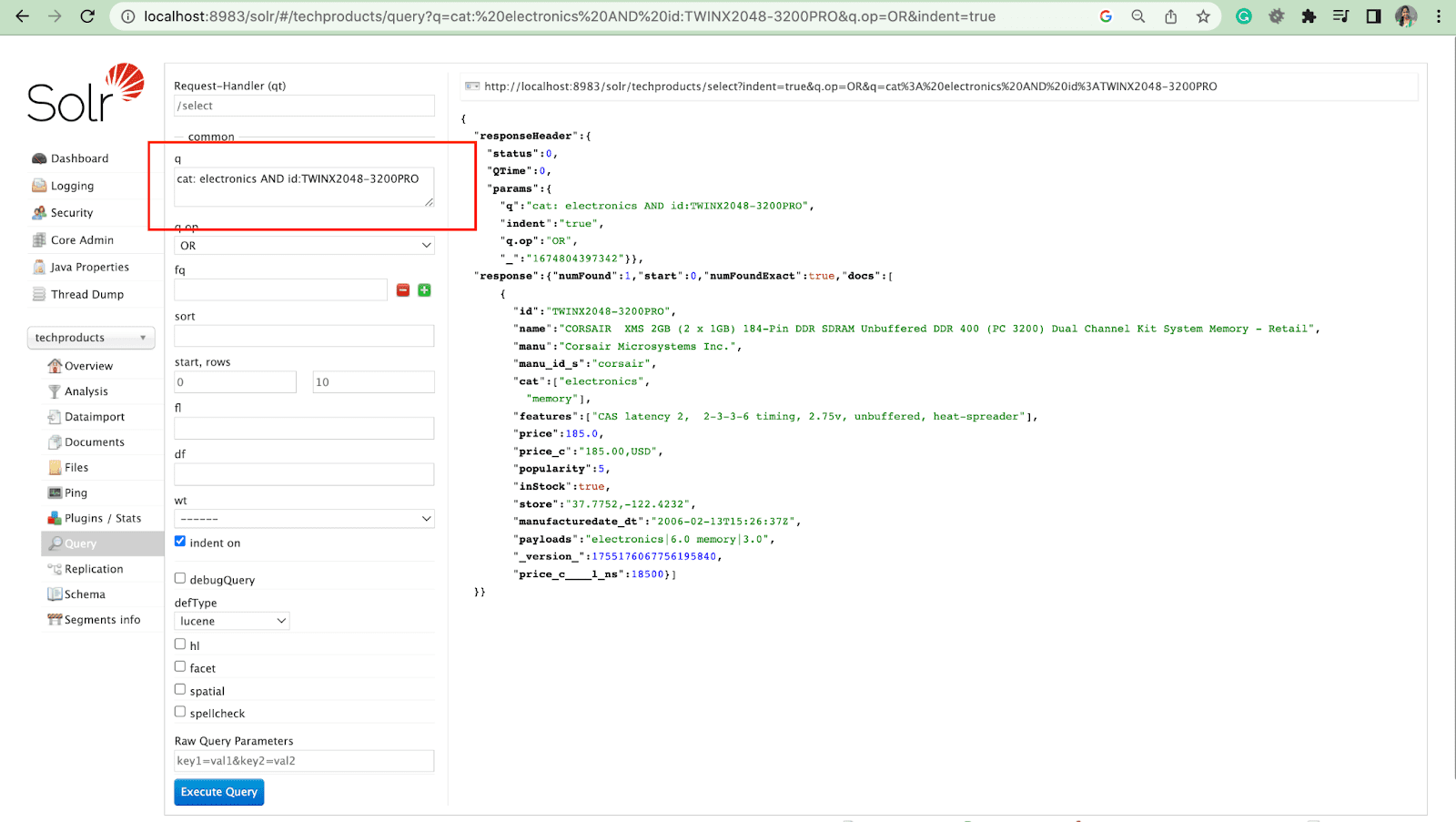
Filtrer la requête
Une requête de filtre permet d'affiner les résultats d'une recherche. Une requête peut être spécifiée par le paramètre fq pour restreindre les documents renvoyés dans le sur-ensemble, sans affecter le score.
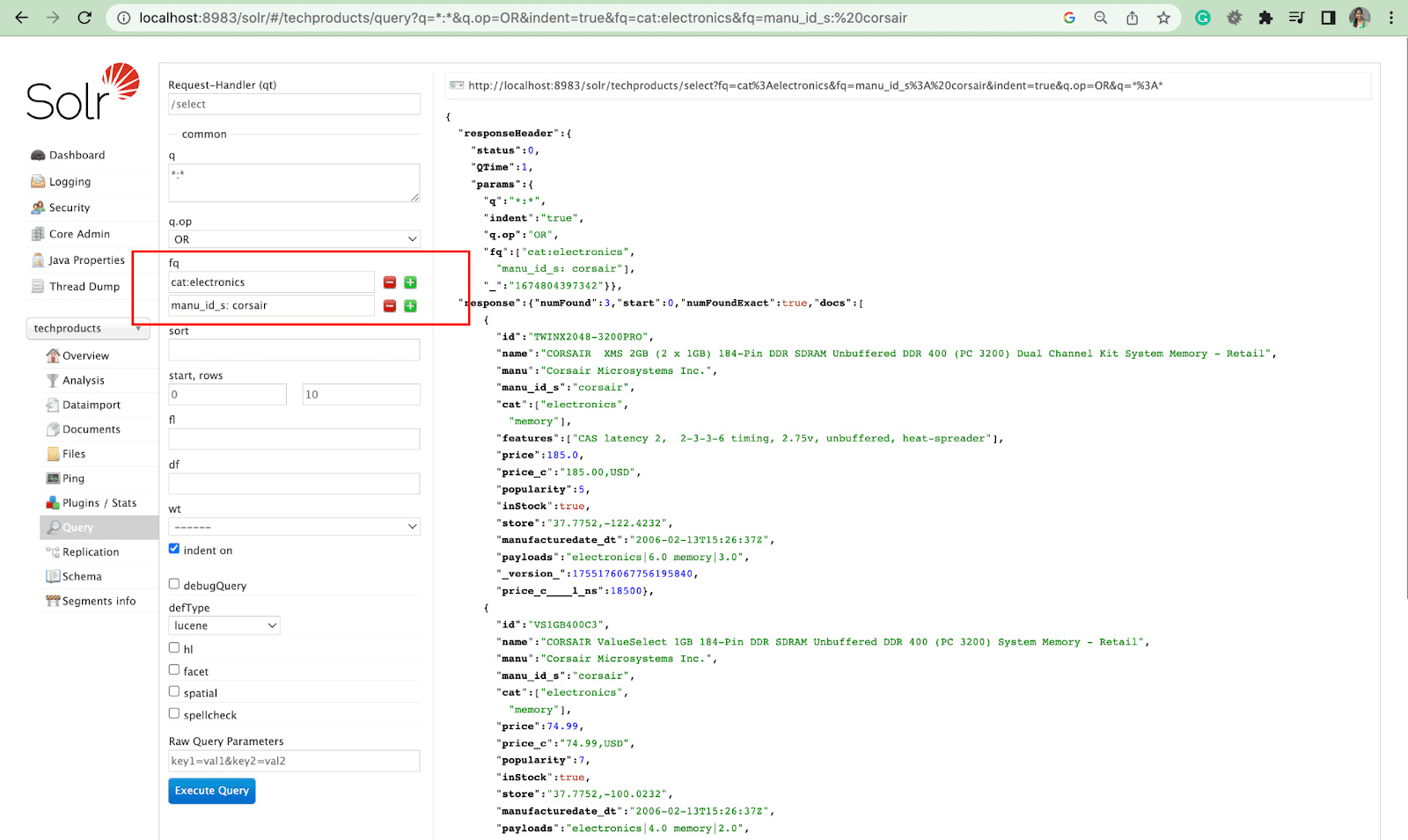
Paramètre de tri
Le paramètre de tri organise les résultats de la recherche dans l'ordre croissant (asc) ou décroissant (desc). Selon le contenu, le paramètre peut être utilisé numériquement ou alphabétiquement.
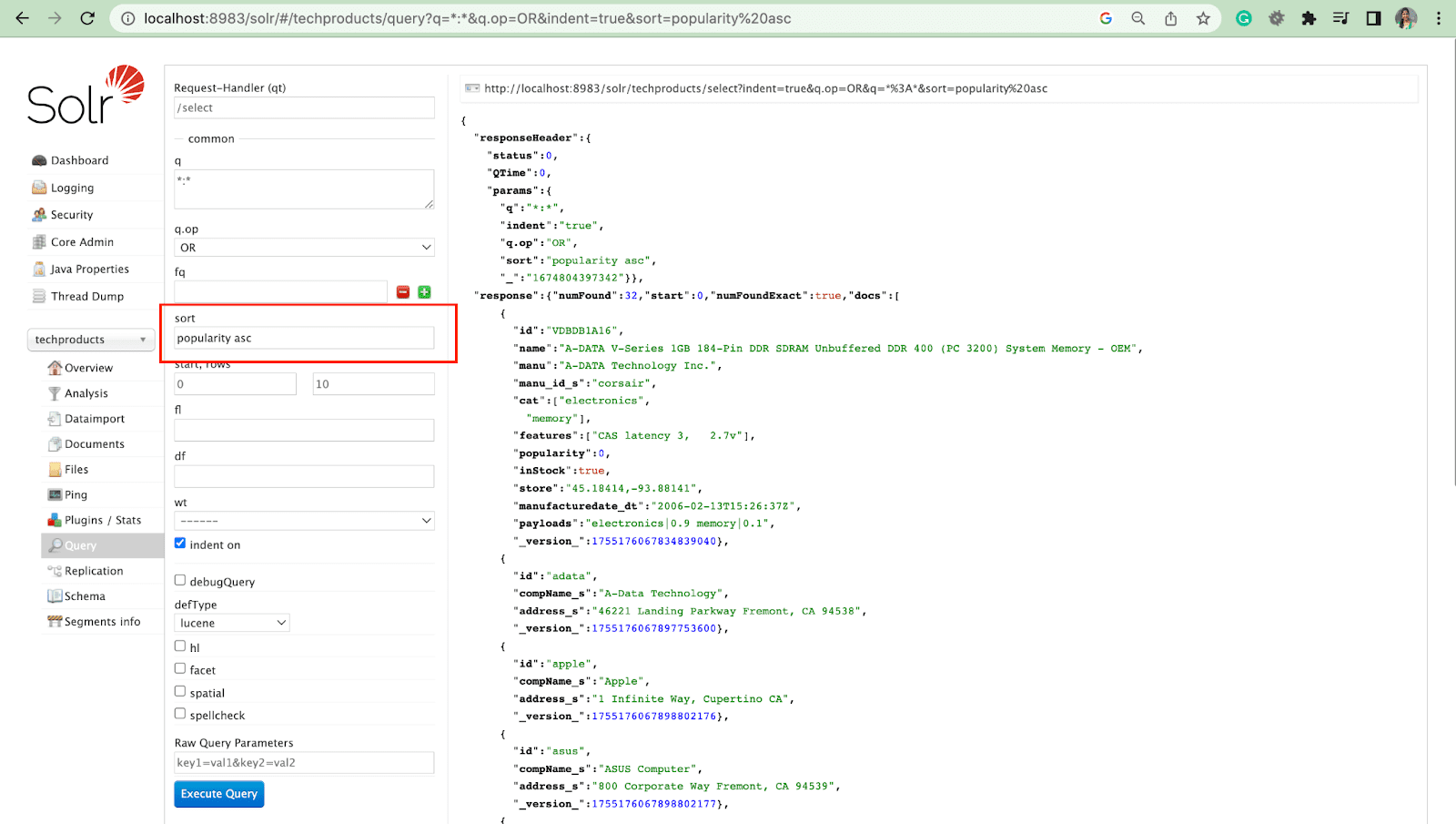
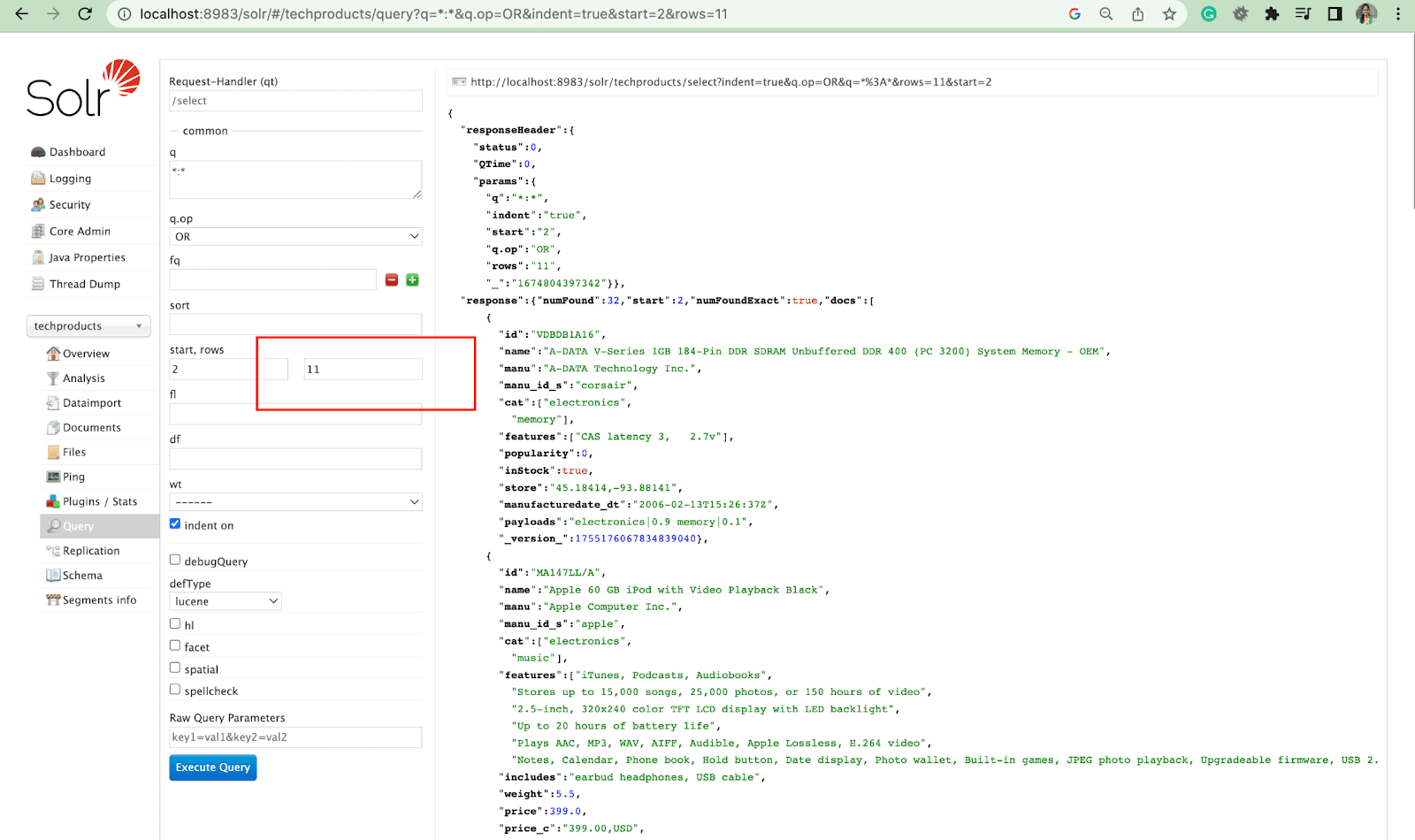
Paramètre de lignes
Le paramètre rows vous permet de paginer les résultats d'une requête.
Paramètre de liste de champs
Le paramètre fl limite les informations incluses dans une réponse à une requête à une liste de champs spécifiée.
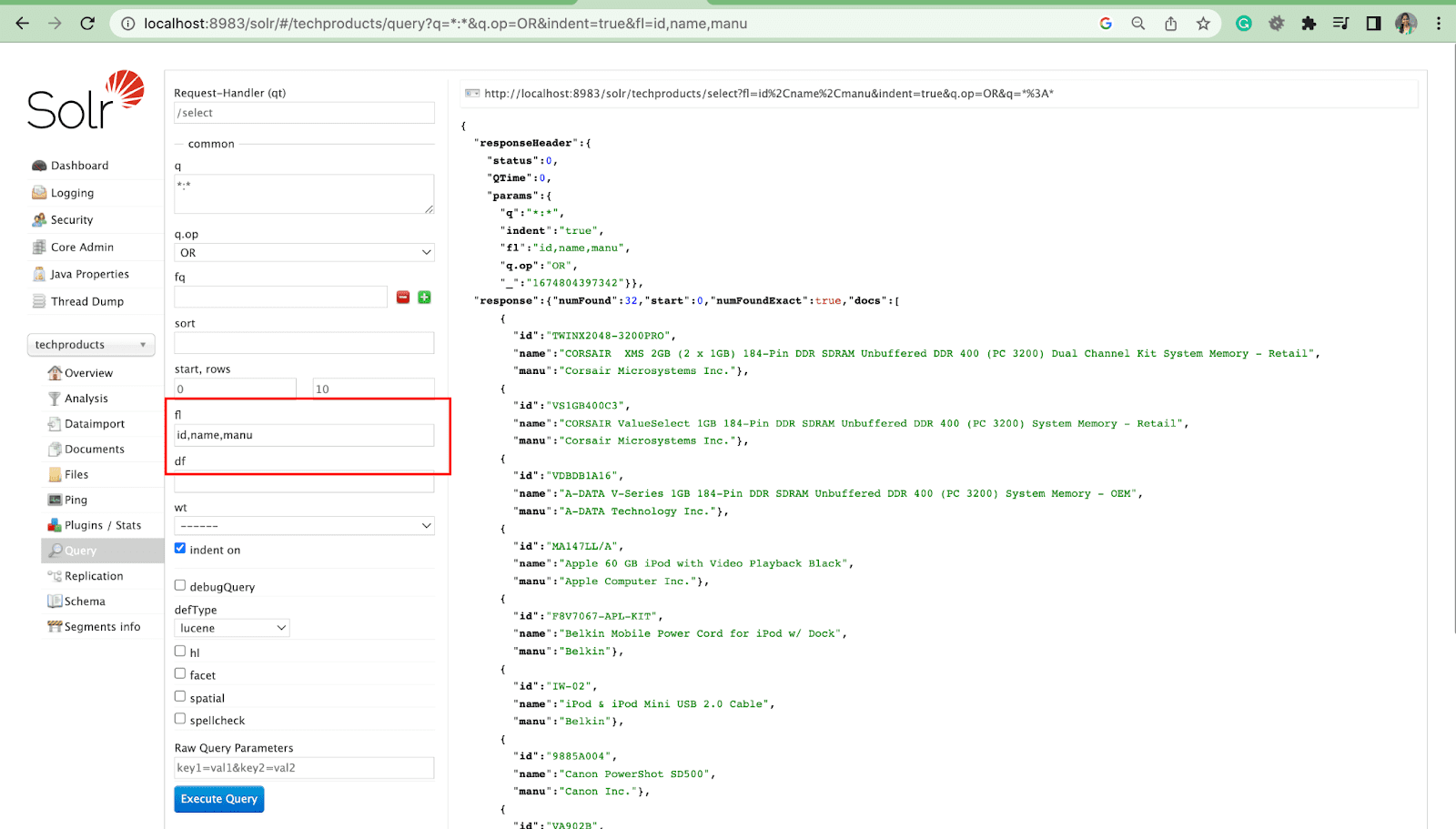
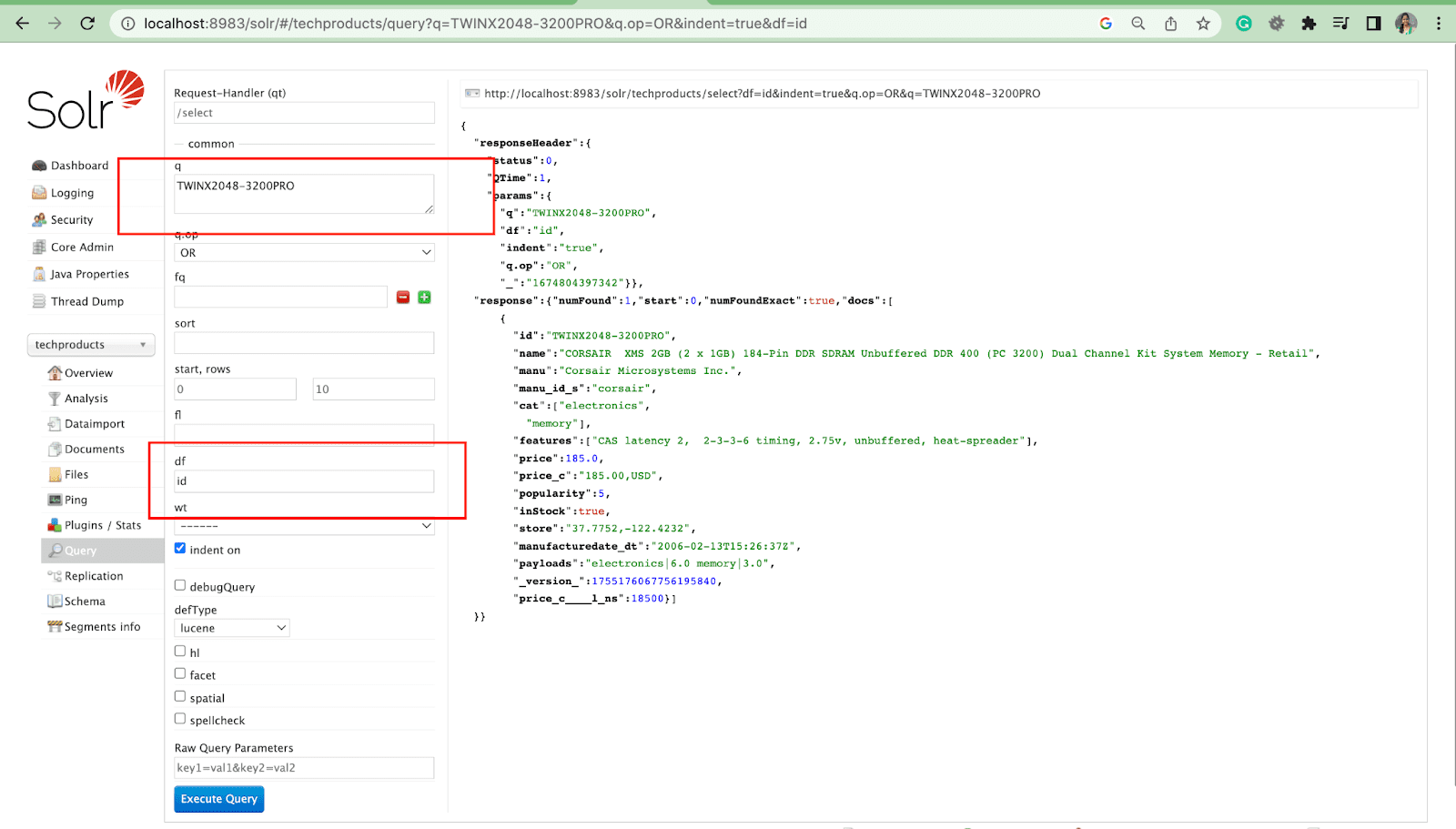
Champ par défaut Paramètre
Le paramètre de champ par défaut est le champ par défaut du paramètre de requête.
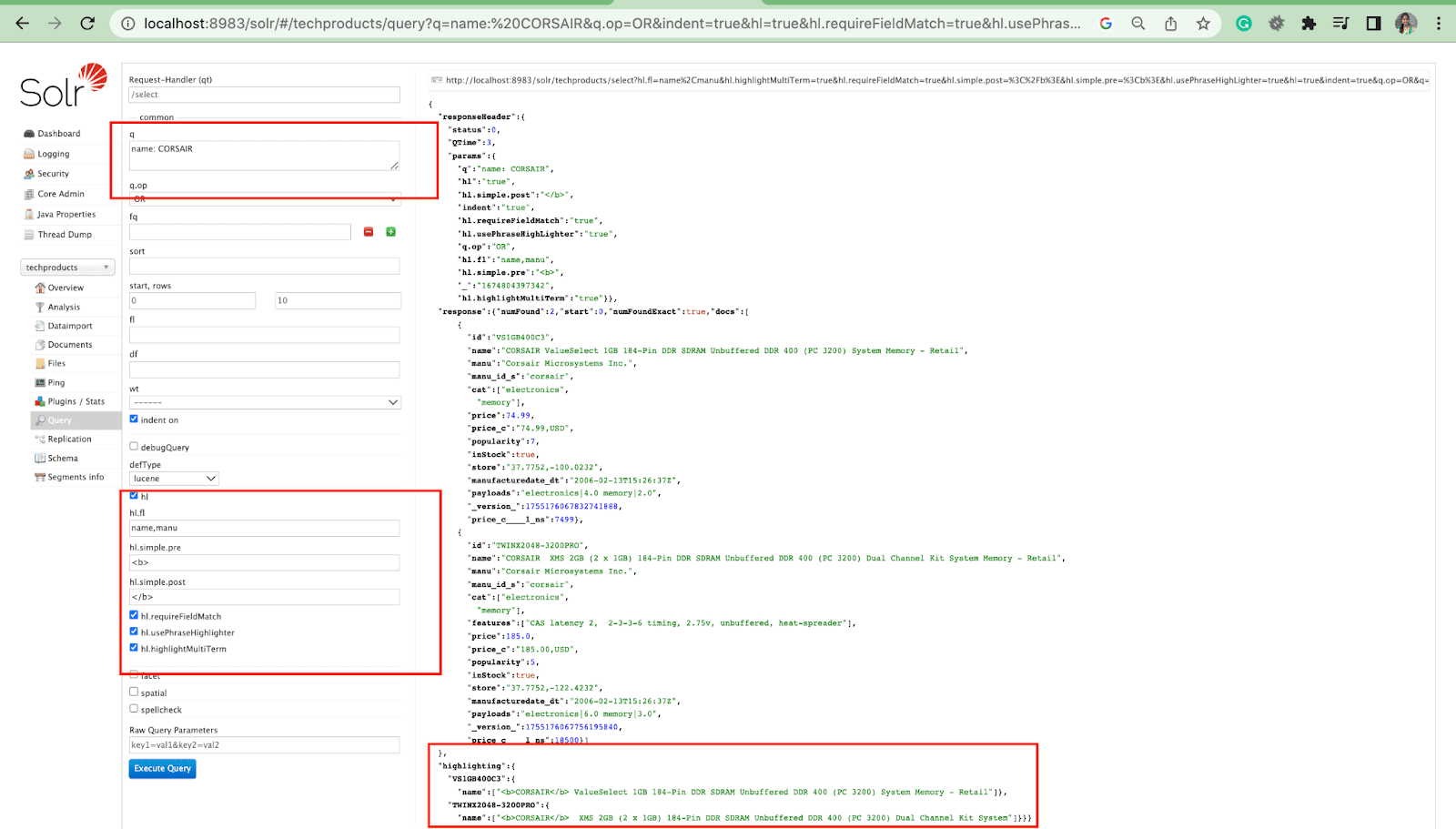
Paramètre de surbrillance
La fonction de surbrillance de Solr permet d'inclure des fragments de documents correspondant à une requête.
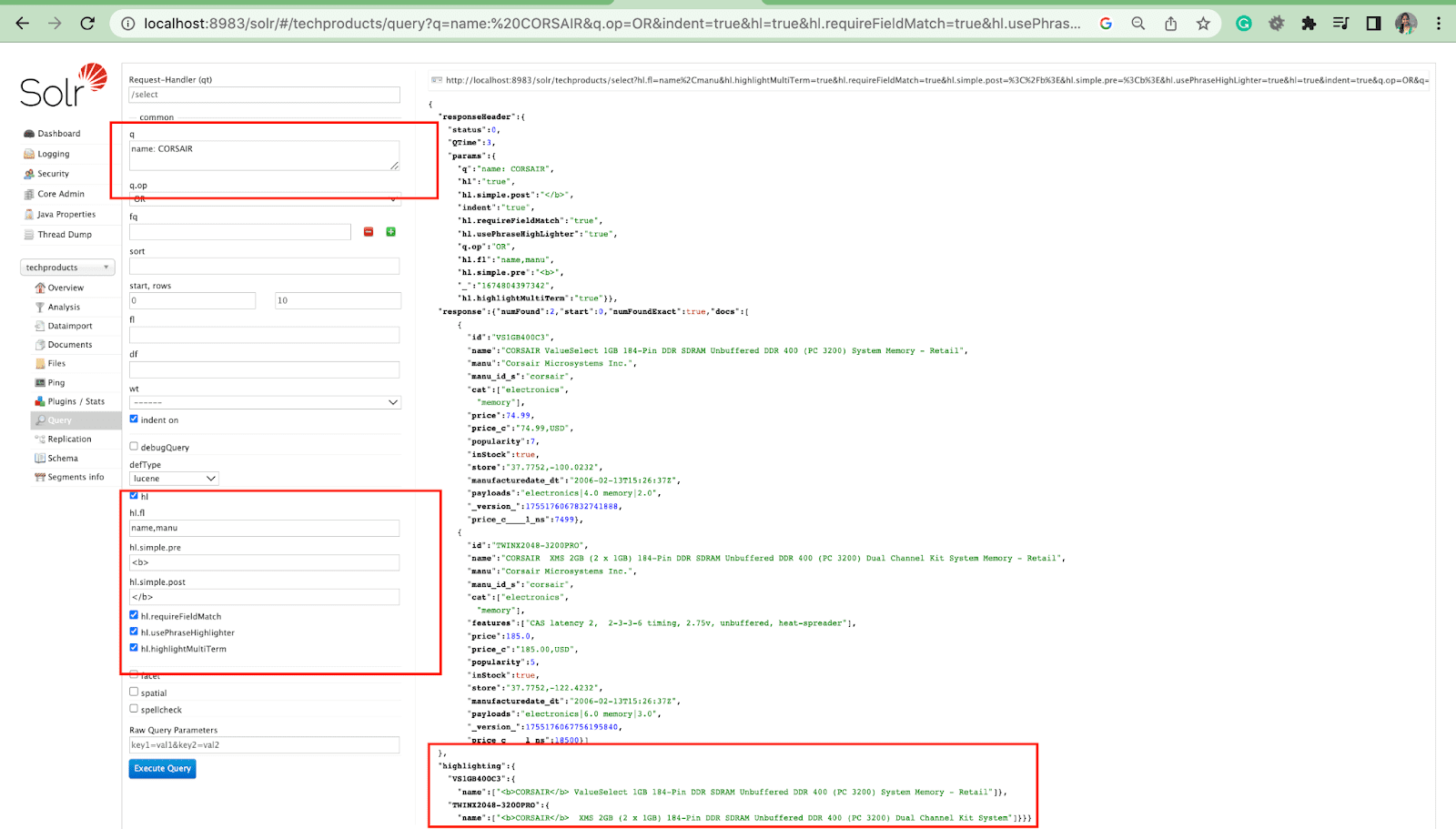
Certains des paramètres de surbrillance les plus courants sont :
- Hl.fl - Met en surbrillance une liste de champs.
- Hl.simple.pre - Spécifie quelle "balise" doit être utilisée avant un mot en surbrillance.
- Hl.simple.post - Spécifie quelle "balise" doit être utilisée après un terme en surbrillance.
- hl.highlightMultiTerm - S'il est défini sur true , Solr mettra en surbrillance les requêtes génériques. Si false , ils ne seront pas du tout mis en surbrillance.
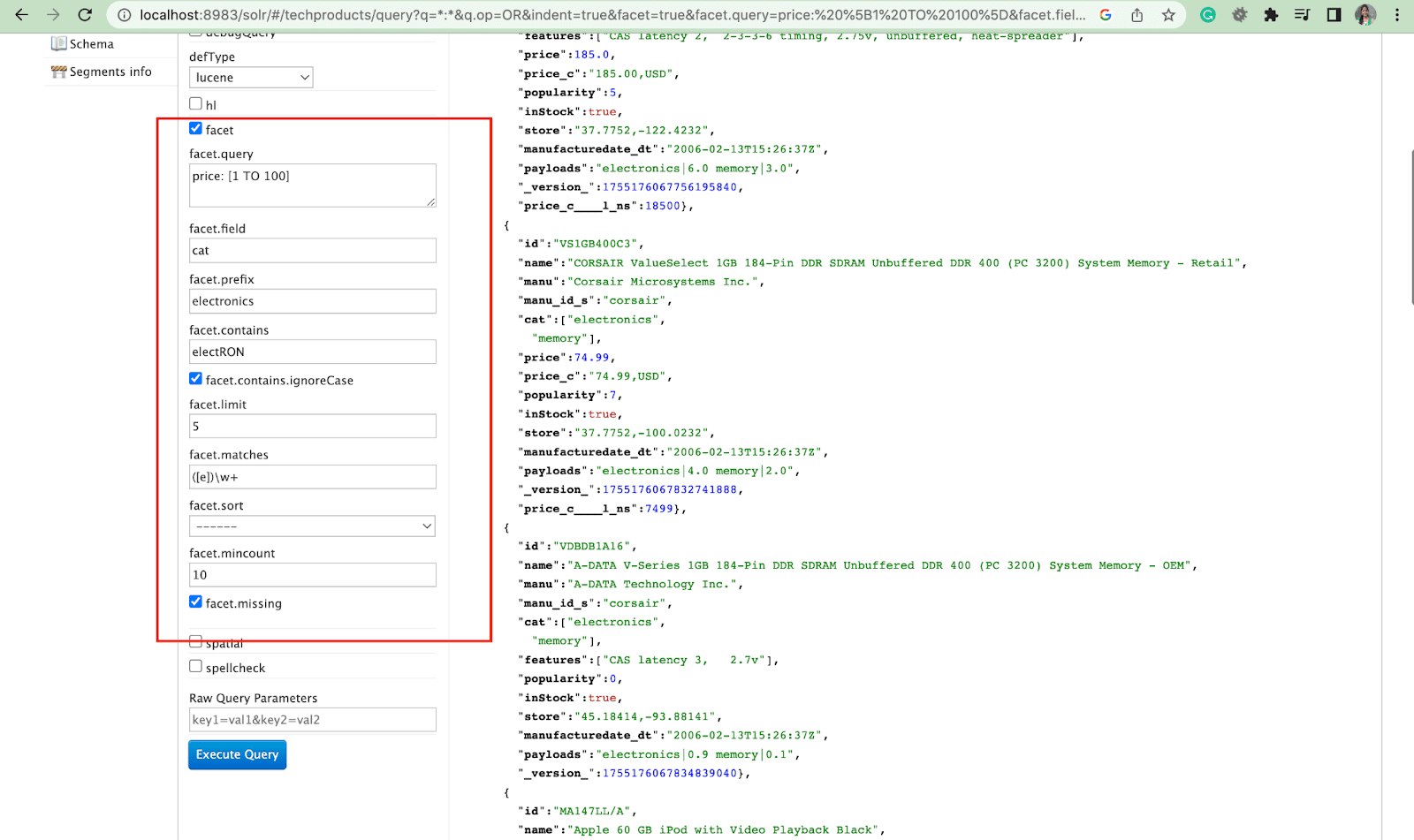
Facette:
Les facettes permettent aux utilisateurs d'explorer et d'affiner de grands ensembles de résultats de recherche. Ils sont affichés dans une interface utilisateur sous forme de cases à cocher, de listes déroulantes ou d'autres contrôles. Les deux paramètres généraux pour contrôler les facettes sont :
- Paramètre de facette
À l'aide du paramètre facet, les utilisateurs peuvent générer des facettes basées sur les valeurs d'un ou plusieurs champs de leur index de recherche. Dans les résultats de la recherche, le paramètre de facette peut être configuré pour contrôler la façon dont les facettes sont générées et affichées.
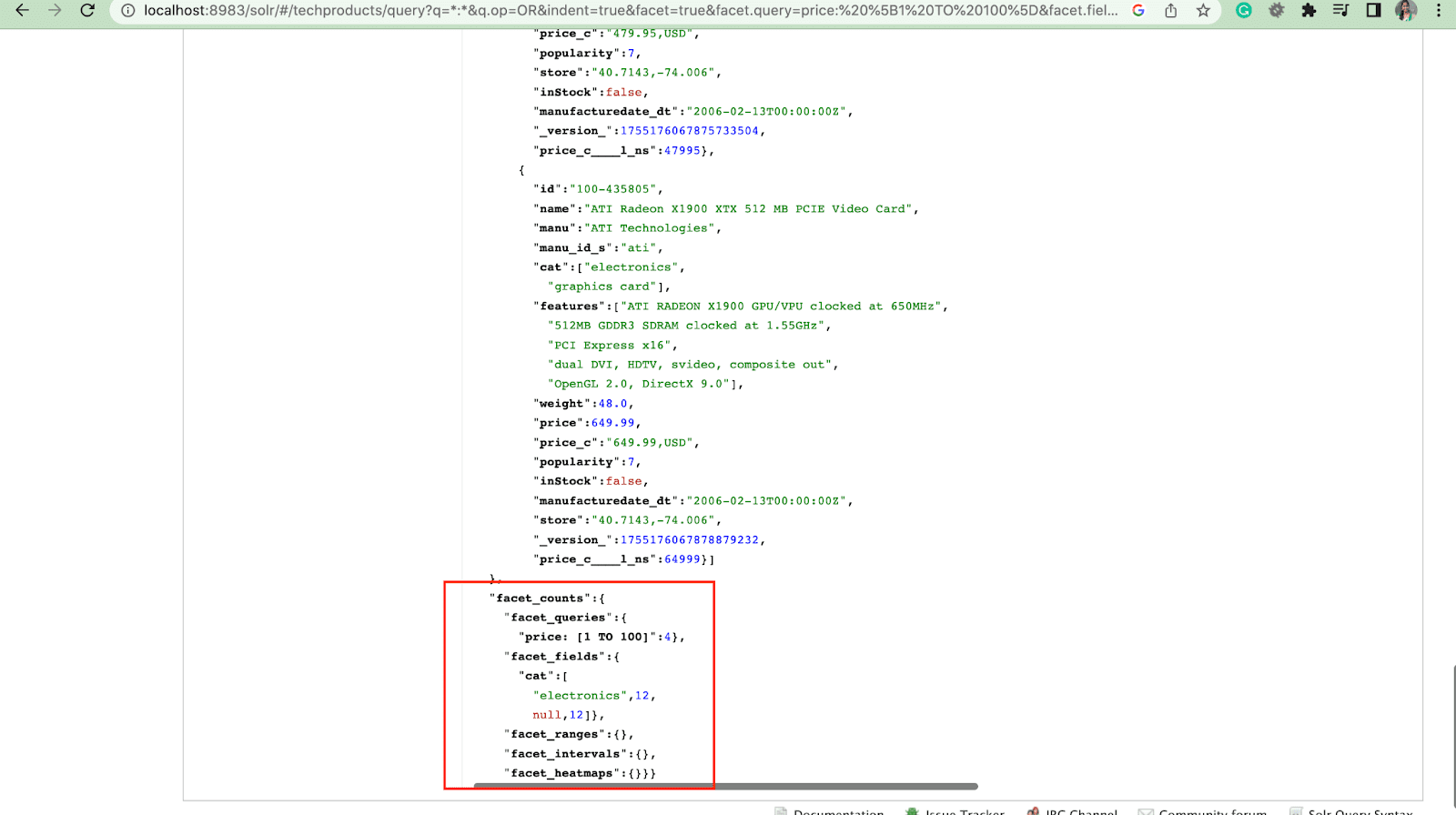
2. Paramètre Facet.query
Lorsqu'un utilisateur inclut un paramètre facet.query dans sa requête Solr, Solr génère une liste de nombres de facettes qui correspondent au nombre de documents dans l'index qui correspondent à chaque requête. Facet.query est utile lorsque vous souhaitez générer des facettes basées sur des critères de recherche complexes qui ne peuvent pas être facilement représentés à l'aide d'une simple valeur de champ.
Il existe plusieurs autres paramètres de facette comme facet.field (pour spécifier les champs qui doivent être utilisés pour générer des facettes) , facet.limit (nombre max de facettes à afficher pour chaque champ) , facet.mincount (nombre min de document nécessaire pour la facette à inclure dans la réponse) , facet.sort (spécifie l'ordre dans lequel les valeurs de la facette doivent s'afficher) .
Dernières pensées
Apache Solr est un moteur de recherche très polyvalent doté de nombreuses fonctionnalités intéressantes qui peuvent être personnalisées selon vos besoins. Drupal fonctionne extrêmement bien avec Apache Solr. Si vous recherchez des experts Drupal pour configurer un puissant moteur de recherche pour votre nouveau projet, nous serions ravis d'aller plus loin !