
Cómo sincronizar su base de datos Oracle local en AWS
Publicado: 2023-01-11Al observar el desarrollo del software corporativo desde la primera fila durante dos décadas, la tendencia innegable de los últimos años es clara: trasladar las bases de datos a la nube.
Ya participé en algunos proyectos de migración, donde el objetivo era llevar la base de datos local existente a la base de datos en la nube de Amazon Web Services (AWS). Si bien a partir de los materiales de documentación de AWS aprenderá lo fácil que puede ser, estoy aquí para decirle que la ejecución de un plan de este tipo no siempre es fácil y hay casos en los que puede fallar.

En esta publicación, cubriré la experiencia del mundo real para el siguiente caso:
- La fuente : si bien, en teoría, realmente no importa cuál sea su fuente (puede usar un enfoque muy similar para la mayoría de las bases de datos más populares), Oracle fue el sistema de base de datos elegido en las grandes empresas durante muchos años, y ahí es donde estará mi enfoque.
- El objetivo : No hay motivo para ser específico de este lado. Puede elegir cualquier base de datos de destino en AWS y el enfoque seguirá siendo adecuado.
- El modo : puede tener una actualización completa o una actualización incremental. Una carga de datos por lotes (los estados de origen y destino se retrasan) o una carga de datos (casi) en tiempo real. Ambos serán tratados aquí.
- La frecuencia : es posible que desee una migración única seguida de un cambio completo a la nube o requiera un período de transición y tener los datos actualizados en ambos lados simultáneamente, lo que implica desarrollar una sincronización diaria entre las instalaciones y AWS. El primero es más simple y tiene mucho más sentido, pero el segundo se solicita con más frecuencia y tiene muchos más puntos de quiebre. Cubriré ambos aquí.
Descripción del problema
El requisito es a menudo simple:
Queremos comenzar a desarrollar servicios dentro de AWS, así que copie todos nuestros datos en la base de datos "ABC". De forma rápida y sencilla. Necesitamos usar los datos dentro de AWS ahora. Más adelante, averiguaremos qué partes de los diseños de base de datos cambiar para que coincidan con nuestras actividades.
Antes de continuar, hay algo que considerar:
- No salte a la idea de “simplemente copiar lo que tenemos y tratarlo más tarde” demasiado rápido. Quiero decir, sí, esto es lo más fácil que puede hacer y se hará rápidamente, pero esto tiene el potencial de crear un problema arquitectónico tan fundamental que será imposible solucionarlo más tarde sin una refactorización seria de la mayoría de la nueva plataforma en la nube. . Imagínese que el ecosistema de la nube es completamente diferente del local. Con el tiempo se introducirán varios servicios nuevos. Naturalmente, las personas comenzarán a usar lo mismo de manera muy diferente. Casi nunca es una buena idea replicar el estado local en la nube de forma 1:1. Podría ser en su caso particular, pero asegúrese de verificar esto dos veces.
- Cuestione el requisito con algunas dudas significativas como:
- ¿Quién será el usuario típico que utilizará la nueva plataforma? Mientras está en las instalaciones, puede ser un usuario comercial transaccional; en la nube, puede ser un científico de datos o un analista de almacenamiento de datos, o el usuario principal de los datos puede ser un servicio (por ejemplo, Databricks, Glue, modelos de aprendizaje automático, etc.).
- ¿Se espera que los trabajos cotidianos regulares se mantengan incluso después de la transición a la nube? Si no, ¿cómo se espera que cambien?
- ¿Planea un crecimiento sustancial de los datos a lo largo del tiempo? Lo más probable es que la respuesta sea sí, ya que esa suele ser la razón más importante para migrar a la nube. Un nuevo modelo de datos estará listo para ello.
- Espere que el usuario final piense en algunas consultas anticipadas generales que la nueva base de datos recibirá de los usuarios. Esto definirá cuánto cambiará el modelo de datos existente para seguir siendo relevante para el rendimiento.
Configuración de la migración
Una vez que se elige la base de datos de destino y se analiza satisfactoriamente el modelo de datos, el siguiente paso es familiarizarse con la herramienta de conversión de esquemas de AWS. Hay varias áreas en las que esta herramienta puede servir:
- Analice y extraiga el modelo de datos de origen. SCT leerá lo que hay en la base de datos local actual y generará un modelo de datos de origen para comenzar.
- Sugiera una estructura de modelo de datos de destino basada en la base de datos de destino.
- Genere scripts de implementación de la base de datos de destino para instalar el modelo de datos de destino (según lo que la herramienta descubrió en la base de datos de origen). Esto generará scripts de implementación y, después de su ejecución, la base de datos en la nube estará lista para las cargas de datos desde la base de datos local.
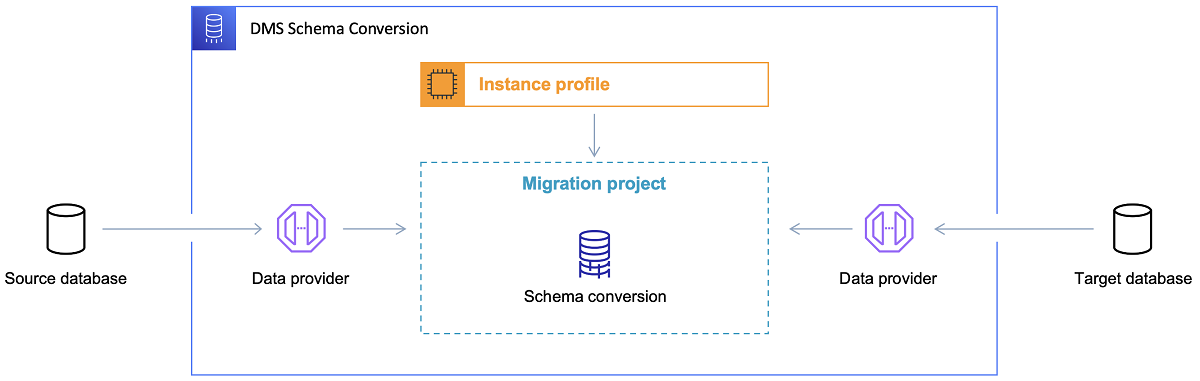
Ahora hay algunos consejos para usar la herramienta de conversión de esquemas.
En primer lugar, casi nunca debería ser el caso usar la salida directamente. Lo consideraría más como resultados de referencia, a partir de los cuales hará sus ajustes en función de su comprensión y el propósito de los datos y la forma en que se utilizarán los datos en la nube.
En segundo lugar, anteriormente, las tablas probablemente fueron seleccionadas por usuarios que esperaban resultados breves y rápidos sobre alguna entidad concreta del dominio de datos. Pero ahora, los datos podrían seleccionarse con fines analíticos. Por ejemplo, los índices de la base de datos que antes funcionaban en la base de datos local ahora serán inútiles y definitivamente no mejorarán el rendimiento del sistema de base de datos relacionado con este nuevo uso. De manera similar, es posible que desee particionar los datos de manera diferente en el sistema de destino, como lo fue antes en el sistema de origen.
Además, podría ser bueno considerar hacer algunas transformaciones de datos durante el proceso de migración, lo que básicamente significa cambiar el modelo de datos de destino para algunas tablas (para que ya no sean copias 1:1). Posteriormente, las reglas de transformación deberán implementarse en la herramienta de migración.
Configuración de la herramienta de migración
Si las bases de datos de origen y de destino son del mismo tipo (p. ej., Oracle local frente a Oracle en AWS, PostgreSQL frente a Aurora Postgresql, etc.), es mejor utilizar una herramienta de migración dedicada que la base de datos concreta admita de forma nativa ( ej., exportaciones e importaciones de bombas de datos, Oracle Goldengate, etc.).
Sin embargo, en la mayoría de los casos, la base de datos de origen y la de destino no serán compatibles, y entonces la herramienta de elección obvia será AWS Database Migration Service.
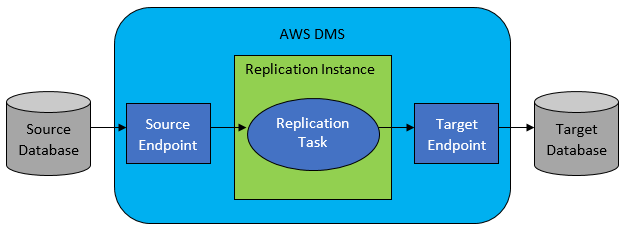
AWS DMS básicamente permite configurar una lista de tareas a nivel de tabla, que definirá:
- ¿Cuál es la base de datos y la tabla de origen exactas a las que conectarse?
- Especificaciones de sentencia que se utilizarán para obtener los datos para la tabla de destino.
- Herramientas de transformación (si las hay), que definen cómo se asignarán los datos de origen a los datos de la tabla de destino (si no es 1:1).
- ¿Cuál es la base de datos y la tabla de destino exactas para cargar los datos?
La configuración de las tareas de DMS se realiza en algún formato fácil de usar como JSON.
Ahora, en el escenario más simple, todo lo que necesita hacer es ejecutar los scripts de implementación en la base de datos de destino e iniciar la tarea de DMS. Pero hay mucho más que eso.

Migración completa de datos por única vez

El caso más fácil de ejecutar es cuando la solicitud es mover toda la base de datos una vez a la base de datos de la nube de destino. Entonces, básicamente, todo lo que hay que hacer se verá así:
- Defina la tarea DMS para cada tabla de origen.
- Asegúrese de especificar la configuración de los trabajos de DMS correctamente. Esto significa configurar un paralelismo razonable, variables de almacenamiento en caché, configuración del servidor DMS, dimensionamiento del clúster DMS, etc. Esta suele ser la fase que consume más tiempo, ya que requiere pruebas exhaustivas y ajustes del estado de configuración óptimo.
- Asegúrese de que cada tabla de destino se cree (vacía) en la base de datos de destino en la estructura de tabla esperada.
- Programe una ventana de tiempo dentro de la cual se realizará la migración de datos. Antes de eso, obviamente, asegúrese (realizando pruebas de rendimiento) de que la ventana de tiempo sea suficiente para que se complete la migración. Durante la migración en sí, la base de datos de origen puede estar restringida desde el punto de vista del rendimiento. Además, se espera que la base de datos de origen no cambie durante el tiempo de ejecución de la migración. De lo contrario, los datos migrados pueden ser diferentes de los almacenados en la base de datos de origen una vez que se realiza la migración.
Si la configuración de DMS se hace bien, no pasará nada malo en este escenario. Cada tabla de origen se recogerá y se copiará en la base de datos de destino de AWS. Las únicas preocupaciones serán el rendimiento de la actividad y asegurarse de que el tamaño sea el correcto en cada paso para que no falle por falta de espacio de almacenamiento.
Sincronización diaria incremental

Aquí es donde las cosas empiezan a complicarse. Quiero decir, si el mundo fuera ideal, entonces probablemente funcionaría bien todo el tiempo. Pero el mundo nunca es ideal.
DMS se puede configurar para operar en dos modos:
- Carga completa : modo predeterminado descrito y utilizado anteriormente. Las tareas de DMS se inician cuando usted las inicia o cuando están programadas para iniciarse. Una vez finalizadas, las tareas de DMS se realizan.
- Change Data Capture (CDC) : en este modo, la tarea DMS se ejecuta continuamente. DMS explora la base de datos de origen en busca de cambios en el nivel de la tabla. Si ocurre el cambio, inmediatamente intenta replicar el cambio en la base de datos de destino según la configuración dentro de la tarea DMS relacionada con la tabla modificada.
Al optar por CDC, debe tomar otra decisión, a saber, cómo CDC extraerá los cambios delta de la base de datos de origen.
#1. Lector de registros Oracle Redo
Una opción es elegir el lector de registros de rehacer de base de datos nativo de Oracle, que CDC puede utilizar para obtener los datos modificados y, en función de los cambios más recientes, replicar los mismos cambios en la base de datos de destino.
Si bien esto puede parecer una opción obvia si se trata de Oracle como fuente, hay una trampa: el lector de registros de rehacer de Oracle utiliza el clúster de Oracle de origen y, por lo tanto, afecta directamente a todas las demás actividades que se ejecutan en la base de datos (en realidad, crea directamente sesiones activas en la base de datos).
Cuantas más tareas de DMS haya configurado (o más clústeres de DMS en paralelo), más probablemente necesitará aumentar el tamaño del clúster de Oracle; básicamente, ajustar la escala vertical de su clúster principal de base de datos de Oracle. Esto seguramente influirá en los costos totales de la solución, más aún si la sincronización diaria está por quedarse con el proyecto por un largo período de tiempo.
#2. Minero de registros de AWS DMS
A diferencia de la opción anterior, esta es una solución nativa de AWS para el mismo problema. En este caso, DMS no afecta la base de datos Oracle de origen. En su lugar, copia los registros de rehacer de Oracle en el clúster de DMS y realiza todo el procesamiento allí. Si bien ahorra recursos de Oracle, es la solución más lenta, ya que involucra más operaciones. Y también, como se puede suponer fácilmente, el lector personalizado para los registros de rehacer de Oracle es probablemente más lento en su trabajo que el lector nativo de Oracle.
Según el tamaño de la base de datos de origen y la cantidad de cambios diarios allí, en el mejor de los casos, podría terminar con una sincronización incremental casi en tiempo real de los datos de la base de datos Oracle local en la base de datos en la nube de AWS.
En cualquier otro escenario, aún no estará cerca de la sincronización en tiempo real, pero puede intentar acercarse lo más posible al retraso aceptado (entre el origen y el destino) ajustando la configuración de rendimiento y el paralelismo de los clústeres de origen y destino o experimentando con la cantidad de tareas de DMS y su distribución entre las instancias de CDC.
Y es posible que desee saber qué cambios en la tabla de origen son compatibles con CDC (como la adición de una columna, por ejemplo) porque no todos los cambios posibles son compatibles. En algunos casos, la única forma es hacer que la tabla de destino cambie manualmente y reiniciar la tarea CDC desde cero (perdiendo todos los datos existentes en la base de datos de destino en el camino).
Cuando las cosas van mal, pase lo que pase

Aprendí esto de la manera más difícil, pero hay un escenario específico relacionado con DMS donde la promesa de replicación diaria es difícil de lograr.
El DMS puede procesar los registros de rehacer solo con una velocidad definida. No importa si hay más instancias de DMS ejecutando sus tareas. Aún así, cada instancia de DMS lee los registros de rehacer solo con una única velocidad definida, y cada uno de ellos debe leerlos completos. Incluso no importa si usa los registros de rehacer de Oracle o el minero de registros de AWS. Ambos tienen este límite.
Si la base de datos de origen incluye una gran cantidad de cambios en un día que los registros de rehacer de Oracle se vuelven realmente locos (como 500 GB o más) todos los días, CDC simplemente no funcionará. La replicación no se completará antes del final del día. Traerá algunos trabajos sin procesar al día siguiente, donde ya está esperando un nuevo conjunto de cambios para replicar. La cantidad de datos sin procesar solo crecerá día a día.
En este caso particular, CDC no era una opción (después de muchas pruebas de rendimiento e intentos que ejecutamos). La única forma de garantizar que al menos todos los cambios delta del día actual se repliquen el mismo día era abordarlo de esta manera:
- Separe las tablas realmente grandes que no se usan con tanta frecuencia y reprodúzcalas solo una vez por semana (por ejemplo, durante los fines de semana).
- Configure la replicación de tablas no tan grandes pero aún así grandes para que se dividan entre varias tareas de DMS; una tabla finalmente fue migrada por 10 o más tareas de DMS separadas en paralelo, asegurando que la división de datos entre las tareas de DMS sea distinta (la codificación personalizada involucrada aquí) y las ejecute diariamente.
- Agregue más (hasta 4 en este caso) instancias de DMS y divida las tareas de DMS entre ellas de manera uniforme, lo que significa no solo por el número de tablas sino también por el tamaño.
Básicamente, usamos el modo de carga completa de DMS para replicar datos diarios porque esa era la única manera de lograr al menos completar la replicación de datos el mismo día.
No es una solución perfecta, pero sigue ahí, e incluso después de muchos años, sigue funcionando de la misma manera. Entonces, tal vez no sea una solución tan mala después de todo.