
Cómo crear un marco de datos de Pandas [con ejemplos]
Publicado: 2022-12-08Aprenda los conceptos básicos para trabajar con pandas DataFrames: la estructura de datos básica en pandas, una poderosa biblioteca de manipulación de datos.
Si desea comenzar con el análisis de datos en Python, pandas es una de las primeras bibliotecas con las que debe aprender a trabajar. Desde importar datos de múltiples fuentes, como archivos CSV y bases de datos, hasta manejar datos faltantes y analizarlos para obtener información: pandas le permite hacer todo lo anterior.
Para comenzar a analizar datos con pandas, debe comprender la estructura de datos fundamental en pandas: marcos de datos .
En este tutorial, aprenderá los conceptos básicos de los marcos de datos de pandas y los métodos comunes para crear marcos de datos. Luego, aprenderá a seleccionar filas y columnas del marco de datos para recuperar subconjuntos de datos.
Por todo esto y más, empecemos.
Instalación e Importación de Pandas
Como pandas es una biblioteca de análisis de datos de terceros, primero debe instalarla. Se recomienda instalar paquetes externos en un entorno virtual para su proyecto.
Si usa la distribución Anaconda de Python, puede usar conda para la administración de paquetes.
conda install pandasTambién puedes instalar pandas usando pip:
pip install pandasLa biblioteca pandas requiere NumPy como dependencia. Entonces, si NumPy aún no está instalado, también se instalará durante el proceso de instalación.
Después de instalar pandas, puede importarlo a su entorno de trabajo. En general, pandas se importa con el alias pd :
import pandas as pd¿Qué es un marco de datos en Pandas?

La estructura de datos fundamental en pandas es el marco de datos . Un marco de datos es una matriz bidimensional de datos con un índice etiquetado y columnas con nombre . Cada columna en el marco de datos llamado serie pandas, comparte un índice común.
Este es un marco de datos de ejemplo que crearemos desde cero en los próximos minutos. Este marco de datos contiene información sobre cuánto gastan seis estudiantes en cuatro semanas.

Los nombres de los estudiantes son las etiquetas de las filas. Y las columnas se denominan 'Week1' a 'Week4'. Observe que todas las columnas comparten el mismo conjunto de etiquetas de fila, también llamado índice .
Cómo crear un marco de datos de pandas
Hay varias formas de crear un marco de datos de pandas. En este tutorial, discutiremos los siguientes métodos:
- Crear un marco de datos a partir de matrices NumPy
- Creación de un marco de datos a partir de un diccionario de Python
- Creación de un marco de datos mediante la lectura de archivos CSV
Desde arreglos NumPy
Vamos a crear un marco de datos a partir de una matriz NumPy.
Vamos a crear la matriz de datos de forma (6,4) asumiendo que en una semana determinada, cada estudiante gasta entre $0 y $100. La función randint() del módulo random de NumPy devuelve una matriz de enteros aleatorios en un intervalo determinado, [low,high) .
import numpy as np np.random.seed(42) data = np.random.randint(0,101,(6,4)) print(data) array([[51, 92, 14, 71], [60, 20, 82, 86], [74, 74, 87, 99], [23, 2, 21, 52], [ 1, 87, 29, 37], [ 1, 63, 59, 20]]) Para crear un marco de datos de pandas, puede usar el constructor DataFrame y pasar la matriz NumPy como argumento data , como se muestra:
students_df = pd.DataFrame(data=data) Ahora podemos llamar a la función incorporada type() para verificar el tipo de students_df . Vemos que es un objeto DataFrame .
type(students_df) # pandas.core.frame.DataFrame print(students_df) 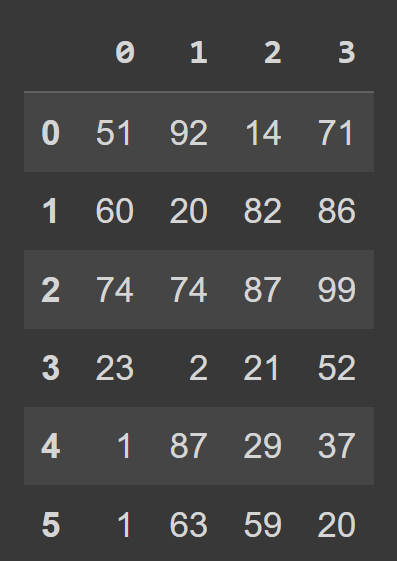
Vemos que, de forma predeterminada, tenemos una indexación de rango que va de 0 a numRows - 1, y las etiquetas de las columnas son 0, 1, 2, ..., numCols -1. Sin embargo, esto reduce la legibilidad. Ayudará a agregar nombres de columna descriptivos y etiquetas de fila al marco de datos.
Vamos a crear dos listas: una para almacenar los nombres de los estudiantes y otra para almacenar las etiquetas de las columnas.
students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] cols = ['Week1','Week2','Week3','Week4'] Al llamar al constructor de DataFrame , puede establecer el index y las columns en las listas de etiquetas de fila y etiquetas de columna para usar, respectivamente.
students_df = pd.DataFrame(data = data,index = students,columns = cols) Ahora tenemos el students_df de datos Students_df con etiquetas descriptivas de filas y columnas.
print(students_df) 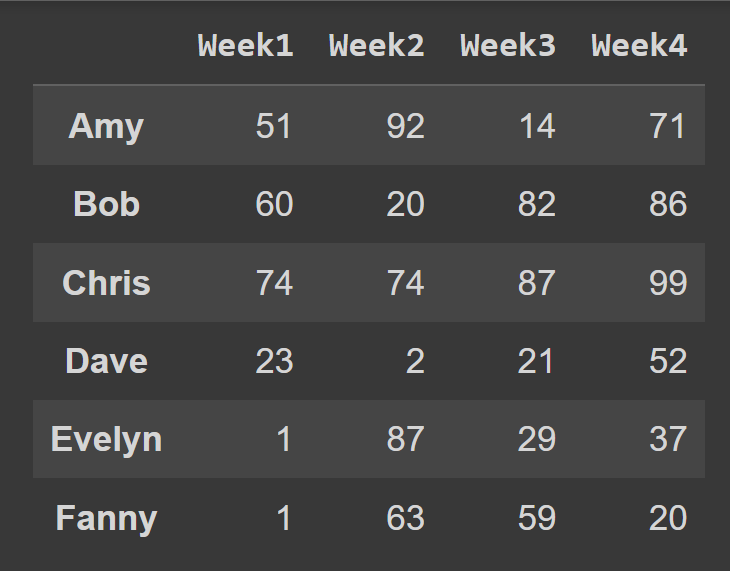
Para obtener información básica sobre el marco de datos, como los valores faltantes y los tipos de datos, puede llamar al método info() en el objeto del marco de datos.
students_df.info() 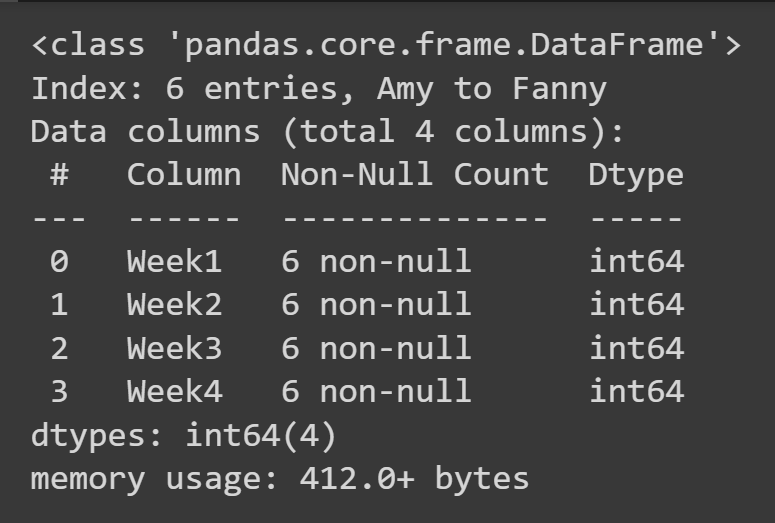
De un diccionario de Python
También puede crear un marco de datos de pandas a partir de un diccionario de Python.
Aquí, data_dict es el diccionario que contiene los datos de los estudiantes:
- Los nombres de los alumnos son las claves.
- Cada valor es una lista de cuánto gasta cada estudiante desde la primera hasta la cuarta semana.
data_dict = {} students = ['Amy','Bob','Chris','Dave','Evelyn','Fanny'] for student,student_data in zip(students,data): data_dict[student] = student_data Para crear un marco de datos a partir de un diccionario de Python, use from_dict , como se muestra a continuación. El primer argumento corresponde al diccionario que contiene los datos ( data_dict ). De forma predeterminada, las claves se utilizan como nombres de columna del marco de datos. Como nos gustaría configurar las claves como etiquetas de fila , configure orient= 'index' .
students_df = pd.DataFrame.from_dict(data_dict,orient='index') print(students_df) 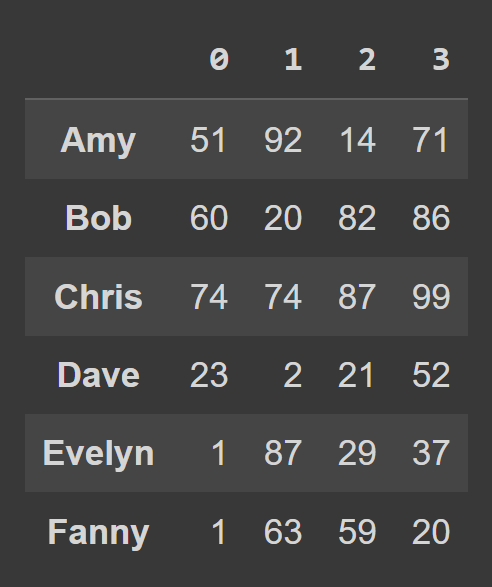
Para cambiar los nombres de las columnas al número de la semana, configuramos las columnas en la lista cols :

students_df = pd.DataFrame.from_dict(data_dict,orient='index',columns=cols) print(students_df) 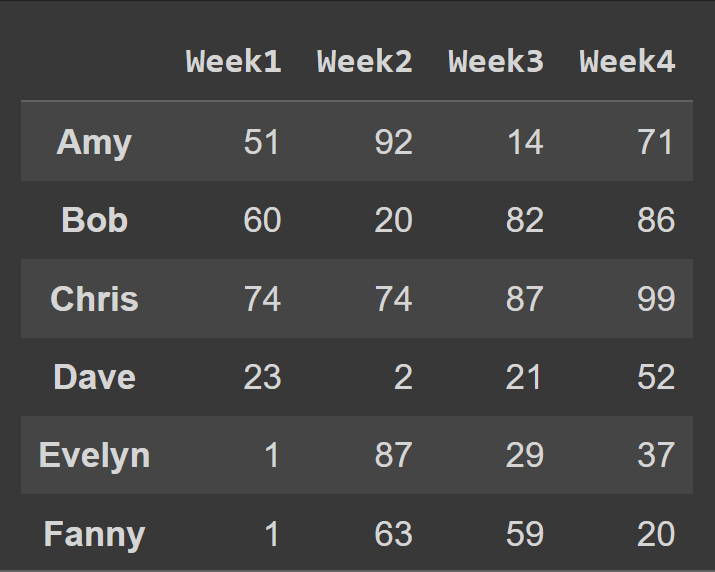
Leer en un archivo CSV en un marco de datos de Pandas
Supongamos que los datos de los estudiantes están disponibles en un archivo CSV. Puede usar la función read_csv() para leer los datos del archivo en un marco de datos de pandas. pd.read_csv('file-path') es la sintaxis general, donde file-path es la ruta al archivo CSV. Podemos establecer el parámetro de names en la lista de nombres de columna para usar.
students_df = pd.read_csv('/content/students.csv',names=cols)Ahora que sabemos cómo crear un marco de datos, aprendamos cómo seleccionar filas y columnas.
Seleccionar columnas de un marco de datos de Pandas
Hay varios métodos integrados que puede usar para seleccionar filas y columnas de un marco de datos. Este tutorial repasará las formas más comunes de seleccionar columnas, filas y filas y columnas de un marco de datos.
Selección de una sola columna
Para seleccionar una sola columna, puede usar df_name[col_name] donde col_name es la cadena que indica el nombre de la columna.
Aquí, seleccionamos solo la columna 'Semana1'.
week1_df = students_df['Week1'] print(week1_df) 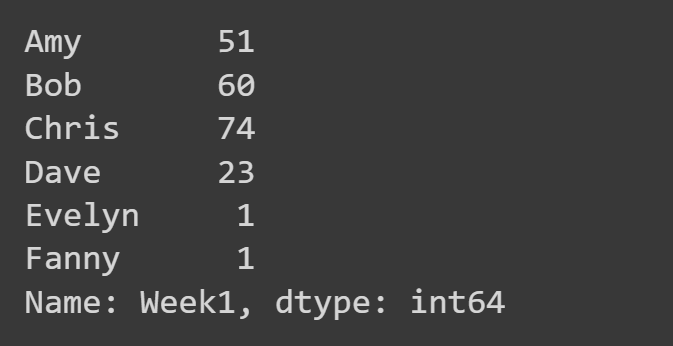
Selección de varias columnas
Para seleccionar varias columnas del marco de datos, pase la lista de todos los nombres de columna para seleccionar.
odd_weeks = students_df[['Week1','Week3']] print(odd_weeks) 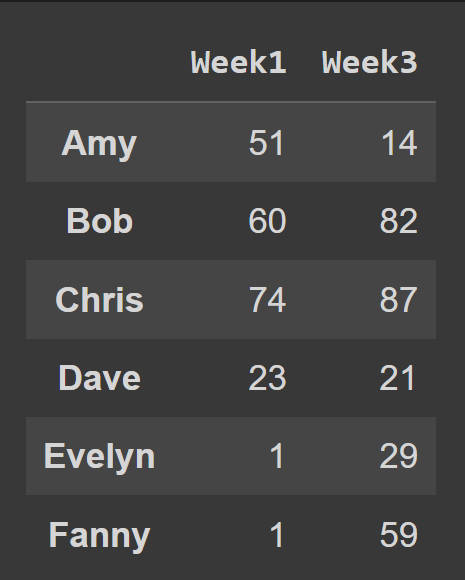
Además de este método, también puede usar los iloc() y loc() para seleccionar columnas. Codificaremos un ejemplo más adelante.
Seleccionar filas de un marco de datos de Pandas

Usando el método .iloc()
Para seleccionar filas usando el método iloc() , pase los índices correspondientes a todas las filas como una lista.
En este ejemplo, seleccionamos las filas en el índice impar.
odd_index_rows = students_df.iloc[[1,3,5]] print(odd_index_rows) 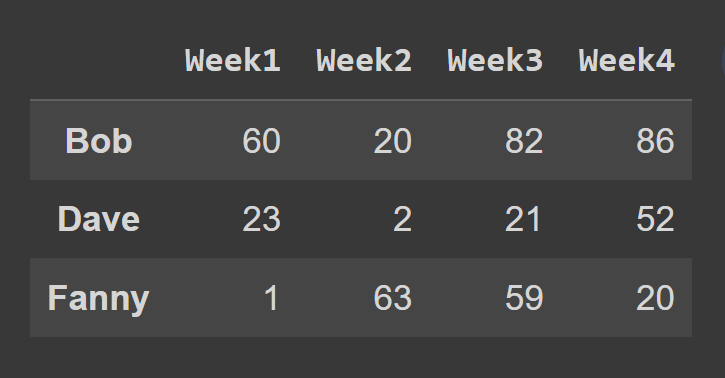
A continuación, seleccionamos un subconjunto del marco de datos que contiene las filas en el índice 0 a 2, el punto final 3 se excluye de forma predeterminada.
slice1 = students_df.iloc[0:3] print(slice1) 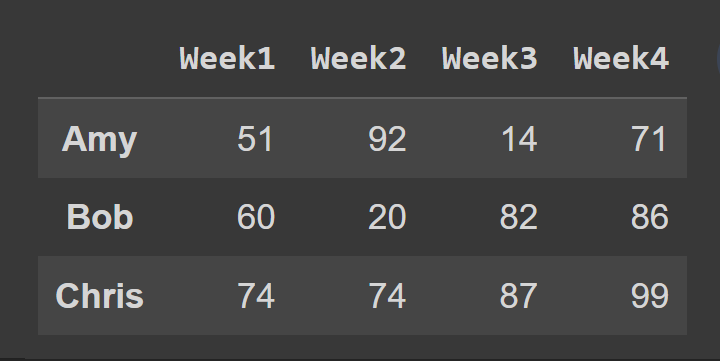
Usando el método .loc()
Para seleccionar las filas de un marco de datos usando el método loc() , debe especificar las etiquetas correspondientes a las filas que desea seleccionar.
some_rows = students_df.loc[['Bob','Dave','Fanny']] print(some_rows) 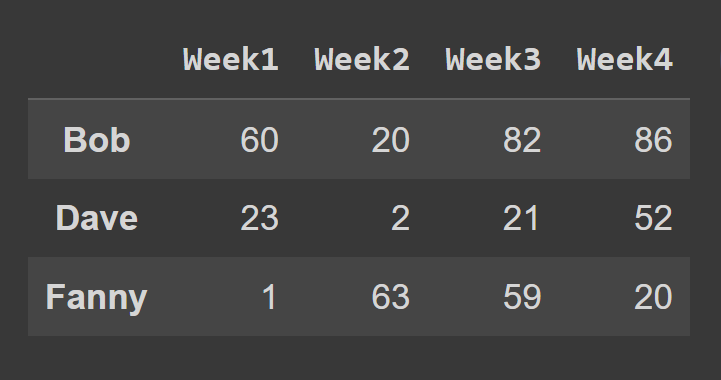
Si las filas del marco de datos se indexan usando el rango predeterminado 0, 1, 2, hasta
numRows-1, entonces usariloc()yloc()son ambos equivalentes.
Seleccionar filas y columnas de un marco de datos de Pandas
Hasta ahora, ha aprendido a seleccionar filas o columnas de un marco de datos de pandas. Sin embargo, es posible que a veces necesite seleccionar un subconjunto de filas y columnas. Entonces, ¿cómo lo haces? Puede usar los iloc() y loc() que hemos discutido.
Por ejemplo, en el fragmento de código a continuación, seleccionamos todas las filas y columnas en el índice 2 y 3.
subset_df1 = students_df.iloc[:,[2,3]] print(subset_df1) 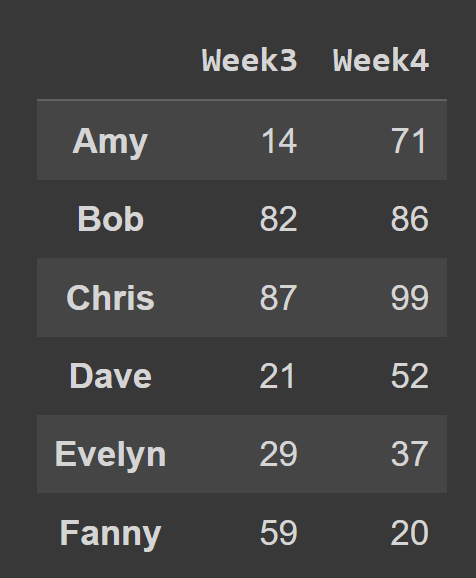
El uso de start:stop crea un segmento desde el start hasta el stop , pero sin incluirlo. Entonces, cuando ignora los valores de start y finalización, cuando stop los valores de inicio y finalización, el segmento comienza al principio y se extiende hasta el final del marco de datos, seleccionando todas las filas.
Al usar el método loc() , debe pasar las etiquetas de las filas y las columnas que desea seleccionar, como se muestra:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']] print(subset_df2) 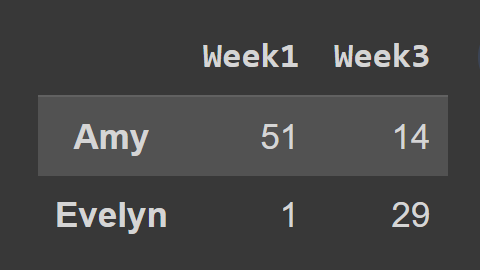
Aquí, el marco de datos subset_df2 contiene el registro de Amy y Evelyn para la semana 1 y la semana 3.
Conclusión
Aquí hay una revisión rápida de lo que ha aprendido en este tutorial:
- Después de instalar pandas, puede importarlo con el alias
pd. Para crear un objeto de marco de datos de pandas, puede usar elpd.DataFrame(data), dondedatase refieren a la matriz N-dimensional o un iterable que contiene los datos. Puede especificar las etiquetas de fila, índice y columna configurando los parámetros opcionales de índice y columna, respectivamente. - El uso
pd.read_csv(path-to-the-file)lee el contenido del archivo en un marco de datos. - Puede llamar al método
info()en el objeto del marco de datos para obtener información sobre las columnas, la cantidad de valores faltantes, los tipos de datos y el tamaño del marco de datos. - Para seleccionar una sola columna, use
df_name[col_name], y para seleccionar varias columnas, columna particular,df_name[[col1,col2,...,coln]]. - También puede seleccionar columnas y filas utilizando los métodos
loc()eiloc(). - Mientras que el método
iloc()toma el índice (o segmento de índice) de las filas y columnas para seleccionar, el métodoloc()toma las etiquetas de fila y columna.
Puede encontrar los ejemplos utilizados en este tutorial en este cuaderno de Colab.
A continuación, consulte esta lista de cuadernos colaborativos de ciencia de datos.