
Desacreditando 3 mitos comunes detrás del rastreo de sitios, la indexación y los mapas de sitios XML
Publicado: 2018-03-07Muchos de nosotros creemos erróneamente que el lanzamiento de un sitio web equipado con un mapa del sitio XML hará que todas sus páginas sean rastreadas e indexadas automáticamente.
En este sentido, se acumulan algunos mitos y conceptos erróneos. Los más comunes son:
- Google rastrea automáticamente todos los sitios y lo hace rápido.
- Al rastrear un sitio web, Google sigue todos los enlaces y visita todas sus páginas y las incluye todas en el índice de inmediato.
- Agregar un mapa del sitio XML es la mejor manera de rastrear e indexar todas las páginas del sitio.
Lamentablemente, hacer que su sitio web entre en el índice de Google es una tarea un poco más complicada. Siga leyendo para tener una mejor idea de cómo funciona el proceso de rastreo e indexación, y qué papel juega un mapa del sitio XML en él.
Antes de comenzar a desacreditar los mitos mencionados anteriormente, aprendamos algunas nociones esenciales de SEO:
El rastreo es una actividad implementada por los motores de búsqueda para rastrear y recopilar URL de toda la Web.
La indexación es el proceso que sigue al rastreo. Básicamente, se trata de analizar y almacenar datos web que luego se utilizan cuando se entregan resultados para consultas de motores de búsqueda. El índice del motor de búsqueda es el lugar donde se almacenan todos los datos web recopilados para su uso posterior.
Crawl Rank es el valor que Google asigna a su sitio y sus páginas. Todavía se desconoce cómo el motor de búsqueda calcula esta métrica. Google confirmó varias veces que la frecuencia de indexación no está relacionada con la clasificación, por lo que no existe una correlación directa entre la autoridad de clasificación de un sitio web y su clasificación de rastreo.
Los sitios web de noticias, los sitios con contenido valioso y los sitios que se actualizan regularmente tienen mayores posibilidades de ser rastreados regularmente.
Crawl Budget es una cantidad de recursos de rastreo que el motor de búsqueda asigna a un sitio web. Por lo general, Google calcula esta cantidad en función del Crawl Rank de su sitio.
La profundidad de rastreo es la medida en que Google profundiza en el nivel de un sitio web cuando lo explora.
Crawl Priority es un número ordinal asignado a una página del sitio que indica su importancia en relación con el rastreo.
Ahora, conociendo todos los conceptos básicos del proceso, ¡vamos a eliminar esos 3 mitos detrás de los mapas de sitio XML, el rastreo y la indexación!
Tabla de contenido
- Mito 1. Google rastrea automáticamente todos los sitios y lo hace rápido.
- comida para llevar
- Mito 2. Agregar un mapa del sitio XML es la mejor manera de rastrear e indexar todas las páginas del sitio.
- comida para llevar
- Mito 3. Un mapa del sitio XML puede resolver todos los problemas de rastreo e indexación.
- comida para llevar
Mito 1. Google rastrea automáticamente todos los sitios y lo hace rápido.
Google afirma que cuando se trata de recopilar datos web, está siendo ágil y flexible.
Pero la verdad sea dicha, porque en este momento hay billones de páginas en la Web, técnicamente, el motor de búsqueda no puede rastrearlas todas rápidamente.
Selección de sitios web para asignar presupuesto de rastreo
El algoritmo inteligente de Google (también conocido como Crawl Budget) distribuye los recursos del motor de búsqueda y decide qué sitios vale la pena rastrear y cuáles no.
Por lo general, Google prioriza los sitios web confiables que corresponden a los requisitos establecidos y sirven como base para definir cómo se comparan otros sitios.
Entonces, si tiene un sitio web recién salido del horno, o un sitio web con contenido raspado, duplicado o delgado, las posibilidades de que se rastree correctamente son bastante pequeñas.
Los factores importantes que también pueden influir en la asignación del presupuesto de rastreo son:
- tamaño del sitio web,
- su estado general (este conjunto de métricas está determinado por la cantidad de errores que pueda tener en cada página),
- y el número de enlaces entrantes e internos.
Para aumentar sus posibilidades de obtener un presupuesto de rastreo, asegúrese de que su sitio cumpla con todos los requisitos de Google mencionados anteriormente, además de optimizar su eficiencia de rastreo (consulte la siguiente sección del artículo).
Predicción del cronograma de rastreo
Google no anuncia sus planes para rastrear URLs web. Además, es difícil adivinar la periodicidad con la que el motor de búsqueda visita algunos sitios.
Puede ser que un sitio realice rastreos al menos una vez al día, mientras que otro sea visitado una vez al mes o incluso con menos frecuencia.
- La periodicidad de los rastreos depende de:
- la calidad del contenido del sitio,
- la novedad y relevancia de la información que ofrece un sitio web,
- y qué tan importantes o populares cree el motor de búsqueda que son las URL de los sitios.
Teniendo en cuenta estos factores, puede intentar predecir la frecuencia con la que Google visitará su sitio web.
El papel de los enlaces externos/internos y los sitemaps XML
Como vías, los robots de Google utilizan enlaces que conectan las páginas del sitio y el sitio web entre sí. Así, el buscador llega a los trillones de páginas interconectadas que existen en la Web.
El motor de búsqueda puede empezar a escanear tu sitio web desde cualquier página, no necesariamente desde la de inicio. La selección del punto de entrada del rastreo depende de la fuente de un enlace entrante. Digamos que algunas de las páginas de sus productos tienen muchos enlaces que provienen de varios sitios web. Google conecta los puntos y visita páginas tan populares en el primer turno.
Un mapa del sitio XML es una gran herramienta para construir una estructura de sitio bien pensada. Además, puede hacer que el proceso de rastreo del sitio sea más específico e inteligente.
Básicamente, el mapa del sitio es un centro con todos los enlaces del sitio. Cada enlace incluido en él puede estar equipado con información adicional: la última fecha de actualización, la frecuencia de actualización, su relación con otras URL en el sitio, etc.
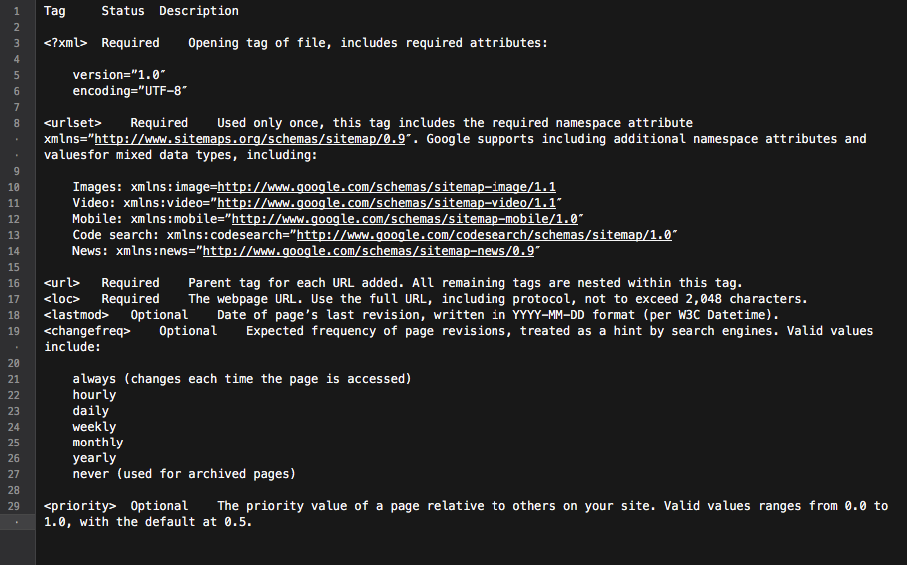 Todo eso proporciona a Googlebots una hoja de ruta detallada para el rastreo de sitios web y hace que el rastreo sea más informado. Además, todos los motores de búsqueda principales dan prioridad a las URL que se enumeran en un mapa del sitio.
Todo eso proporciona a Googlebots una hoja de ruta detallada para el rastreo de sitios web y hace que el rastreo sea más informado. Además, todos los motores de búsqueda principales dan prioridad a las URL que se enumeran en un mapa del sitio.
En resumen, para que las páginas de su sitio estén en el radar de Googlebot, debe crear un sitio web con excelente contenido y optimizar su estructura de enlaces internos.
comida para llevar
• Google no rastrea automáticamente todos sus sitios web.
• La periodicidad del rastreo del sitio depende de la importancia o la popularidad del sitio y sus páginas.
• La actualización de contenido hace que Google visite un sitio web con más frecuencia.
• Es poco probable que los sitios web que no se correspondan con los requisitos del motor de búsqueda se rastreen correctamente.
• Los bots de los motores de búsqueda generalmente ignoran los sitios web y las páginas del sitio que no tienen enlaces internos/externos.
• Agregar un mapa del sitio XML puede mejorar el proceso de rastreo del sitio web y hacerlo más inteligente.
Mito 2. Agregar un mapa del sitio XML es la mejor manera de rastrear e indexar todas las páginas del sitio.
Todos los propietarios de sitios web quieren que Googlebot visite todas las páginas importantes del sitio (excepto las que no se pueden indexar), así como explorar instantáneamente contenido nuevo y actualizado.
Sin embargo, el motor de búsqueda tiene su propia visión de las prioridades de rastreo del sitio.
Cuando se trata de verificar un sitio web y su contenido, Google utiliza un conjunto de algoritmos llamado presupuesto de rastreo. Básicamente, permite que el motor de búsqueda escanee las páginas del sitio, mientras usa inteligentemente sus propios recursos.
Comprobar el presupuesto de rastreo de un sitio web
Es bastante fácil averiguar cómo se rastrea su sitio y si tiene algún problema con el presupuesto de rastreo.
Solo necesitas:
- cuente el número de páginas en su sitio y en su mapa del sitio XML,
- visite Google Search Console, vaya a la sección Crawl -> Crawl Stats y verifique cuántas páginas se rastrean en su sitio diariamente,
- divida el número total de páginas de su sitio por el número de páginas que se rastrean por día.
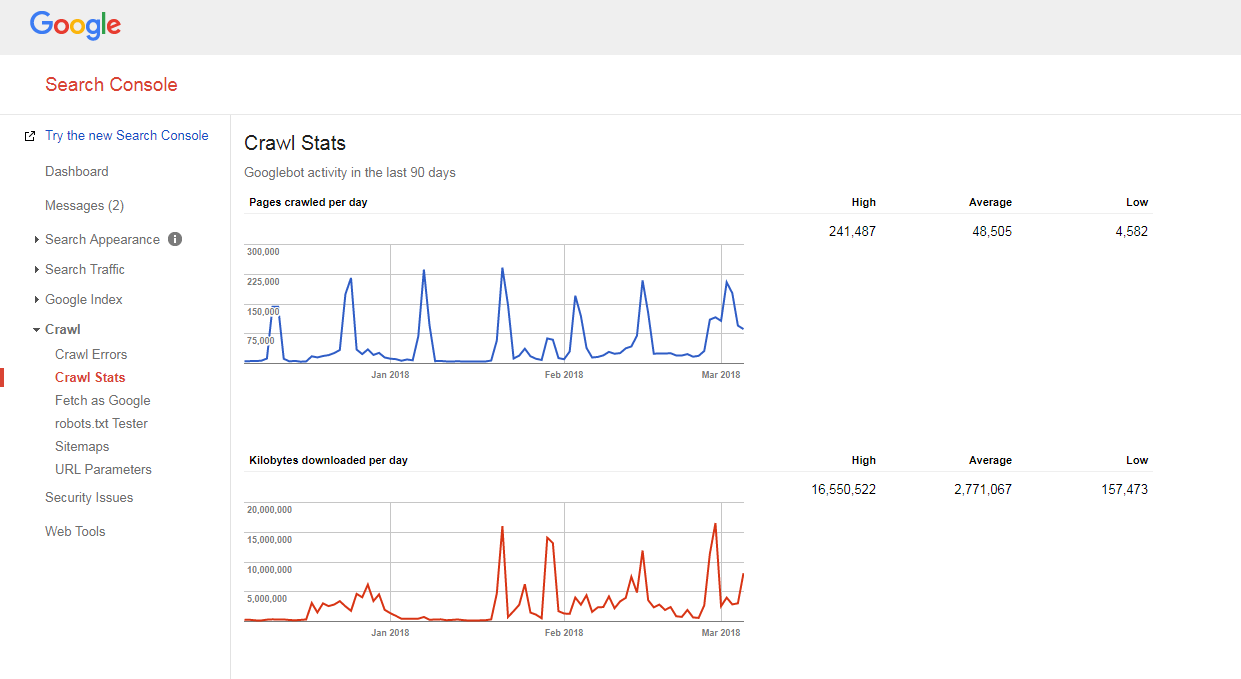 Si el número que tiene es mayor que 10 (hay 10 veces más páginas en su sitio que las que Google rastrea a diario), tenemos malas noticias para usted: su sitio web tiene problemas de rastreo.
Si el número que tiene es mayor que 10 (hay 10 veces más páginas en su sitio que las que Google rastrea a diario), tenemos malas noticias para usted: su sitio web tiene problemas de rastreo.
Pero antes de aprender a solucionarlos, debe comprender otra noción, es decir...
profundidad de rastreo
La profundidad del rastreo es la medida en que Google sigue explorando un sitio web hasta cierto nivel.
Generalmente, la página de inicio se considera de nivel 1, una página que está a 1 clic de distancia es de nivel 2, etc.
Las páginas de nivel profundo tienen un Pagerank más bajo (o no lo tienen) y es menos probable que Googlebot las rastree. Por lo general, el motor de búsqueda no profundiza más allá del nivel 4.
En el escenario ideal, una página específica debe estar a 1-4 clics de distancia de la página de inicio o de las categorías principales del sitio. Cuanto más larga sea la ruta a esa página, más recursos deben asignar los motores de búsqueda para llegar a ella.
Si al estar en un sitio web, Google estima que la ruta es demasiado larga, deja de seguir rastreando.
Optimización de la profundidad de rastreo y el presupuesto
Para evitar que Googlebot se ralentice, optimice el presupuesto y la profundidad de rastreo de su sitio web, debe hacer lo siguiente:
- corregir todos los errores 404, JS y otros errores de página;
Una cantidad excesiva de errores de página puede ralentizar significativamente la velocidad del rastreador de Google. Para encontrar todos los errores principales del sitio, inicie sesión en su panel de Herramientas para webmasters de Google (Bing, Yandex) y siga todas las instrucciones que se dan aquí.

- optimizar la paginación;
En caso de que tenga listas de paginación demasiado largas, o su esquema de paginación no le permita hacer clic más allá de un par de páginas hacia abajo en la lista, es probable que el rastreador del motor de búsqueda deje de excavar en esa pila de páginas.
Además, si hay pocos elementos por página, se puede considerar como de contenido ligero y no se rastreará.
- comprobar los filtros de navegación;
Algunos esquemas de navegación pueden venir con múltiples filtros que generan nuevas páginas (por ejemplo, páginas filtradas por navegación en capas). Aunque dichas páginas pueden tener potencial de tráfico orgánico, también pueden crear una carga no deseada en los rastreadores de los motores de búsqueda.
La mejor manera de solucionar esto es limitar los enlaces sistemáticos a las listas filtradas. Idealmente, debe usar 1-2 filtros como máximo. Por ejemplo, si tiene una tienda con 3 filtros LN (color/tamaño/género), debe permitir la combinación sistemática de solo 2 filtros (por ejemplo, color-tamaño, género-tamaño). En caso de que necesite agregar combinaciones de más filtros, debe agregarles enlaces manualmente.
- Optimizar los parámetros de seguimiento en las URL;
Varios parámetros de seguimiento de URL (p. ej., '?source=thispage') pueden crear trampas para los rastreadores, ya que generan una gran cantidad de nuevas URL. Este problema es típico de las páginas con bloques de "productos similares" o "historias relacionadas", donde estos parámetros se utilizan para rastrear el comportamiento de los usuarios.
Para optimizar la eficiencia del rastreo en este caso, se recomienda transmitir la información de rastreo detrás de un '#' al final de la URL. De esta manera, dicha URL permanecerá sin cambios. Además, también es posible redirigir URL con parámetros de seguimiento a las mismas URL pero sin seguimiento.
- elimine los redireccionamientos 301 excesivos;
Digamos que tiene una gran cantidad de URL que están vinculadas sin una barra inclinada al final. Cuando el bot del motor de búsqueda visita dichas páginas, se le redirige a la versión con una barra oblicua.
Por lo tanto, el bot tiene que hacer el doble de lo que se supone que debe hacer y, finalmente, puede darse por vencido y dejar de rastrear. Para evitar esto, intente actualizar todos los enlaces dentro de su sitio cada vez que cambie las URL.
Prioridad de rastreo
Como se dijo anteriormente, Google prioriza los sitios web para rastrear. Así que no es de extrañar que haga lo mismo con las páginas dentro de un sitio web rastreado.
Para la mayoría de los sitios web, la página con la prioridad de rastreo más alta es la página de inicio.
Sin embargo, como se dijo antes, en algunos casos esa también puede ser la categoría más popular o la página de productos más visitada. Para encontrar las páginas que obtienen una mayor cantidad de rastreos por parte de Googlebot, solo mire los registros de su servidor.
Aunque Google no anuncia oficialmente que los factores que supuestamente pueden influir en la prioridad de rastreo de una página del sitio son:
- inclusión en un mapa del sitio XML (y agregue las etiquetas de prioridad * para las páginas más importantes),
- el número de enlaces entrantes,
- el número de enlaces internos,
- popularidad de la página (# de visitas),
- Rango de página.
Pero incluso después de haber despejado el camino para que los robots de los motores de búsqueda rastreen su sitio web, aún pueden ignorarlo. Siga leyendo para saber por qué.
Para comprender mejor cómo funciona la prioridad de rastreo, vea esta presentación virtual de Gary Illyes.
Hablando de las etiquetas de prioridad en un mapa del sitio XML, se pueden agregar manualmente o con la ayuda de la funcionalidad integrada de la plataforma en la que se basa su sitio. Además, algunas plataformas admiten extensiones/aplicaciones de mapas de sitios XML de terceros que simplifican el proceso.
Con la etiqueta Prioridad del mapa del sitio XML, puede asignar los siguientes valores a diferentes categorías de páginas del sitio:
- 0.0-0.3 a páginas de utilidad, contenido desactualizado y cualquier página de menor importancia,
- 0.4-0.7 a los artículos de su blog, preguntas frecuentes y páginas de conocimiento, páginas de categoría y subcategoría de importancia secundaria, y
- 0.8-1.0 a las categorías principales de su sitio, páginas de destino clave y la página de inicio.
comida para llevar
• Google tiene su propia visión sobre las prioridades del proceso de rastreo.
• Una página que se supone debe entrar en el índice del motor de búsqueda debe estar a 1-4 clics de distancia de la página de inicio, las categorías principales del sitio o las páginas del sitio más populares.
• Para evitar que Googlebot disminuya la velocidad y optimizar el presupuesto de rastreo y la profundidad de rastreo de su sitio web, debe encontrar y corregir 404, JS y otros errores de página, optimizar la paginación del sitio y los filtros de navegación, eliminar los redireccionamientos 301 excesivos y optimizar los parámetros de seguimiento en las URL.
• Para mejorar la prioridad de rastreo de una página importante del sitio, asegúrese de que estén incluidos en un mapa del sitio XML (con etiquetas de prioridad) y bien vinculados con otras páginas del sitio, que tengan enlaces provenientes de otros sitios web relevantes y autorizados.
Mito 3. Un mapa del sitio XML puede resolver todos los problemas de rastreo e indexación.
Si bien es una buena herramienta de comunicación que alerta a Google sobre las URL de su sitio y las formas de llegar a ellas, un mapa del sitio XML NO garantiza que los robots de los motores de búsqueda visiten su sitio (por no hablar de incluir todas las páginas del sitio en el Índice) .
Además, debe comprender que los mapas de sitio no lo ayudarán a mejorar la clasificación de su sitio. Incluso si una página es rastreada e incluida en el índice del motor de búsqueda, su desempeño en la clasificación depende de muchos otros factores (enlaces internos y externos, contenido, calidad del sitio, etc.).
Sin embargo, cuando se usa correctamente, un mapa del sitio XML puede mejorar significativamente la eficiencia del rastreo de su sitio. A continuación se presentan algunos consejos sobre cómo maximizar el potencial SEO de esta herramienta.
Se consistente
Al crear un mapa del sitio, recuerde que se utilizará como hoja de ruta para los rastreadores de Google. Por lo tanto, es importante no engañar al motor de búsqueda proporcionando direcciones incorrectas.
Por ejemplo, puede incluir ocasionalmente en su mapa del sitio XML algunas páginas de utilidad ( Contáctenos o páginas de TOS, páginas para iniciar sesión, restaurar la página de contraseña perdida, páginas para compartir contenido , etc.).
Estas páginas generalmente están ocultas de la indexación con metaetiquetas de robots noindex o no están permitidas en el archivo robots.txt.
Por lo tanto, incluirlos en un mapa del sitio XML solo confundirá a los robots de Google, lo que puede influir negativamente en el proceso de recopilación de información sobre su sitio web.
Actualizar regularmente
La mayoría de los sitios web en la Web cambian casi todos los días. Especialmente el sitio web de comercio electrónico con productos y categorías que se mezclan regularmente dentro y fuera del sitio.
Para mantener a Google bien informado, debe mantener actualizado su mapa del sitio XML.
Algunas plataformas (Magento, Shopify) tienen una funcionalidad integrada que le permite actualizar periódicamente sus mapas de sitio XML o admiten algunas soluciones de terceros que son capaces de realizar esta tarea.
Por ejemplo, en Magento 2, puede determinar la periodicidad de los ciclos de actualización del mapa del sitio. Cuando lo define en los ajustes de configuración de la plataforma, le indica al rastreador que las páginas de su sitio se actualizan en un cierto intervalo de tiempo (cada hora, semanal, mensual) y su sitio necesita otro rastreo.
Haga clic aquí para obtener más información al respecto.
Pero recuerda que, si bien es útil establecer la prioridad y la frecuencia de las actualizaciones del mapa del sitio, es posible que no se pongan al día con los cambios reales y, a veces, no brinden una imagen real.
Por eso, asegúrese de que su mapa del sitio refleje todos los cambios realizados recientemente.
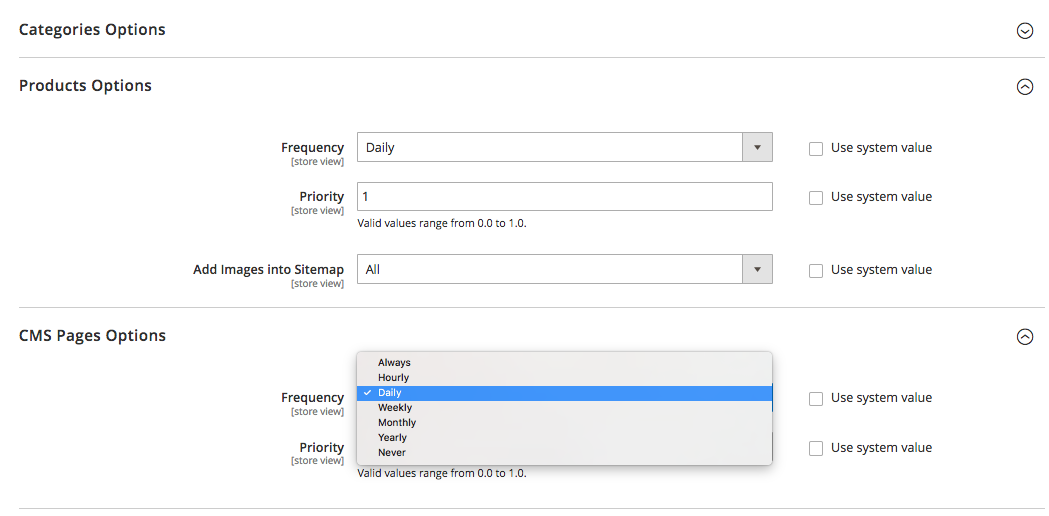 Segmente el contenido del sitio y establezca las prioridades de rastreo correctas
Segmente el contenido del sitio y establezca las prioridades de rastreo correctas
Google está trabajando arduamente para medir la calidad general del sitio y mostrar solo los mejores y más relevantes.
Pero como sucede a menudo, no todos los sitios se crean de la misma manera y no son capaces de ofrecer un valor real.
Digamos que un sitio web puede constar de 1000 páginas, y solo 50 de ellas son de grado «A». Los otros son puramente funcionales, tienen contenido desactualizado o no tienen contenido.
Si Google comienza a explorar un sitio web de este tipo, probablemente decidirá que es bastante basura debido al alto porcentaje de páginas de bajo valor, spam u obsoletas.
Por eso, al crear un mapa del sitio XML, se recomienda segmentar el contenido del sitio web y guiar a los robots de los motores de búsqueda solo a las áreas del sitio que merecen la pena.
Y como recordará, las etiquetas de prioridad, asignadas a las páginas del sitio más importantes en su mapa del sitio XML, también pueden ser de gran ayuda.
comida para llevar
• Al crear un mapa del sitio, asegúrese de no incluir páginas ocultas de la indexación con metaetiquetas de robots noindex o no permitidas en el archivo robots.txt.
• Actualizar mapas de sitio XML (manual o automáticamente) inmediatamente después de realizar cambios en la estructura y el contenido del sitio web.
• Segmente el contenido de su sitio para incluir solo páginas de grado "A" en el mapa del sitio.
• Establecer prioridad de rastreo para diferentes tipos de página.
Eso es básicamente todo.
¿Tienes algo que decir sobre el tema? No dude en compartir su opinión sobre el rastreo, la indexación o los mapas de sitios en la sección de comentarios a continuación.