
オンプレミスの Oracle データベースを AWS に同期する方法
公開: 2023-01-11企業のソフトウェア開発を最初から 20 年にわたって見てきましたが、ここ数年の否定できない傾向は明らかです。それは、データベースをクラウドに移行することです。
私はすでにいくつかの移行プロジェクトに携わっていました。その目標は、既存のオンプレミス データベースをアマゾン ウェブ サービス (AWS) クラウド データベースに移行することでした。 AWS のドキュメント資料から、これがいかに簡単であるかがわかりますが、そのような計画の実行は必ずしも簡単ではなく、失敗する場合があることをお伝えします。

この投稿では、次のケースの実際の経験について説明します。
- ソース: 理論的には、ソースが何であるかは実際には問題ではありませんが (最も人気のある DB の大部分に対して非常によく似たアプローチを使用できます)、Oracle は長年にわたって大企業で選択されたデータベース システムでした。それが私の焦点になるところです。
- ターゲット: こちら側を特定する理由はありません。 AWS では任意のターゲット データベースを選択でき、アプローチは引き続き適合します。
- モード: 完全リフレッシュまたは増分リフレッシュを行うことができます。 バッチ データ ロード (ソースとターゲットの状態が遅延) または (ほぼ) リアルタイムのデータ ロード。 ここでは両方について触れます。
- 頻度: 1 回限りの移行に続いてクラウドへの完全な切り替えが必要な場合や、ある程度の移行期間が必要で、両方のデータを同時に最新の状態にする必要がある場合があります。これは、オンプレミスと AWS 間の毎日の同期を開発することを意味します。 前者はより単純で理にかなっていますが、後者はより頻繁に要求され、はるかに多くのブレークポイントがあります。 ここでは両方をカバーします。
問題の説明
多くの場合、要件は単純です。
AWS 内でサービスの開発を開始したいので、すべてのデータを「ABC」データベースにコピーしてください。 すばやく簡単に。 今すぐ AWS 内のデータを使用する必要があります。 後で、私たちの活動に合わせて DB 設計のどの部分を変更する必要があるかを判断します。
先に進む前に、考慮すべきことがあります。
- 「持っているものをコピーして後で処理する」という考えにすぐに飛びつかないでください。 はい、これは最も簡単に実行できる方法であり、すぐに実行できますが、新しいクラウド プラットフォームの大部分を真剣にリファクタリングしなければ、後で修正することが不可能なような根本的なアーキテクチャ上の問題が発生する可能性があります。 . クラウド エコシステムがオンプレミスのエコシステムとはまったく異なることを想像してみてください。 今後、いくつかの新しいサービスが導入される予定です。 当然、人々は同じものを非常に異なる方法で使用し始めます。 オンプレミスの状態をクラウドに 1 対 1 で複製することは、ほとんど良い考えではありません。 特定のケースに当てはまるかもしれませんが、必ずこれを再確認してください。
- 次のようないくつかの意味のある疑問を持って要件に疑問を投げかけます。
- 新しいプラットフォームを利用する典型的なユーザーは誰ですか? オンプレミスの場合は、トランザクション ビジネス ユーザーになることができます。 クラウドでは、データ サイエンティストまたはデータ ウェアハウス アナリストである場合もあれば、データのメイン ユーザーがサービス (例: Databricks、Glue、機械学習モデルなど) である場合もあります。
- クラウドに移行した後も、通常の日常業務は維持されると予想されますか? そうでない場合、それらはどのように変化すると予想されますか?
- 時間の経過とともにデータが大幅に増加する予定はありますか? 多くの場合、それがクラウドに移行する唯一の最も重要な理由であるため、答えはイエスです。 そのための新しいデータモデルを用意する必要があります。
- エンド ユーザーは、新しいデータベースがユーザーから受け取る一般的で予想されるクエリについて考える必要があります。 これにより、パフォーマンス関連性を維持するために既存のデータ モデルをどの程度変更する必要があるかが定義されます。
移行の設定
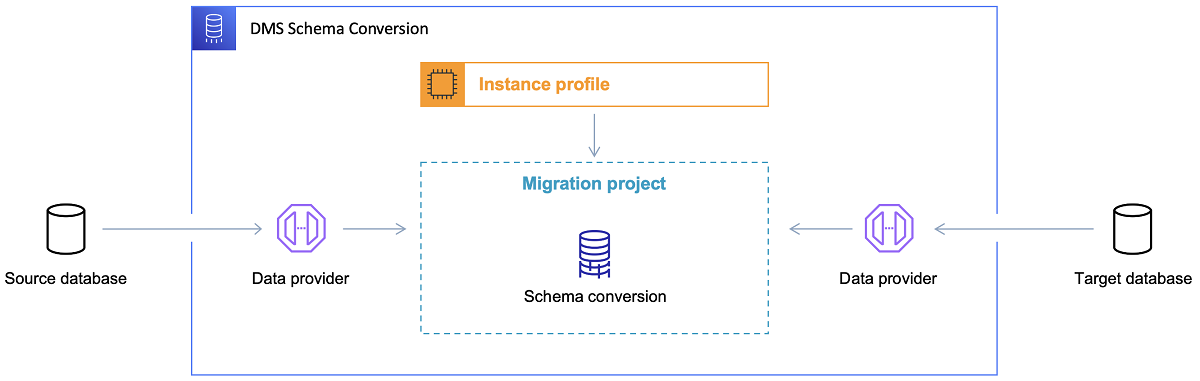
ターゲット データベースを選択し、データ モデルについて十分に検討したら、次のステップは AWS Schema Conversion Tool に慣れることです。 このツールが役立ついくつかの領域があります。
- ソース データ モデルを分析して抽出します。 SCT は現在のオンプレミス データベースの内容を読み取り、最初にソース データ モデルを生成します。
- ターゲット データベースに基づいて、ターゲット データ モデル構造を提案します。
- ターゲット データ モデルをインストールするためのターゲット データベース デプロイメント スクリプトを生成します (ツールがソース データベースから検出した内容に基づきます)。 これによりデプロイ スクリプトが生成され、その実行後、クラウド内のデータベースはオンプレミス データベースからデータをロードできるようになります。
ここで、スキーマ変換ツールを使用するためのヒントをいくつか紹介します。
まず、出力を直接使用することはほとんどありません。 データの理解と目的、クラウドでのデータの使用方法に基づいて、どこから調整を行うかという参照結果のようなものだと思います。
第 2 に、以前は、具体的なデータ ドメイン エンティティに関する簡単な結果を期待して、ユーザーがテーブルを選択した可能性があります。 しかし今では、データは分析目的で選択される可能性があります。 たとえば、以前はオンプレミス データベースで機能していたデータベース インデックスは、今や役に立たなくなり、この新しい使用法に関連する DB システムのパフォーマンスは確実に向上しません。 同様に、以前はソース システムであったように、ターゲット システムでも異なる方法でデータを分割することが必要な場合があります。
また、移行プロセス中にいくつかのデータ変換を行うことを検討することをお勧めします。これは基本的に、一部のテーブルのターゲット データ モデルを変更することを意味します (テーブルが 1 対 1 のコピーではなくなるようにするため)。 後で、変換ルールを移行ツールに実装する必要があります。
移行ツールの構成
ソース データベースとターゲット データベースが同じタイプの場合 (たとえば、オンプレミスの Oracle と AWS の Oracle、PostgreSQL と Aurora Postgresql など) は、具体的なデータベースがネイティブにサポートする専用の移行ツールを使用することをお勧めします (たとえば、データ ポンプのエクスポートとインポート、Oracle Goldengate など)。
ただし、ほとんどの場合、ソース データベースとターゲット データベースには互換性がないため、選択する明らかなツールは AWS Database Migration Service になります。
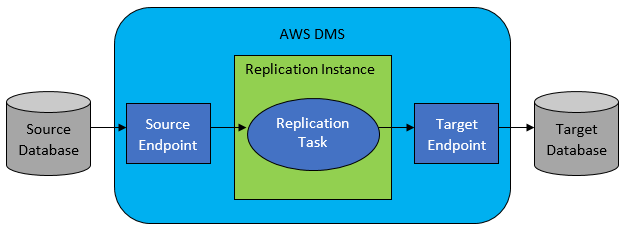
AWS DMS では基本的に、テーブル レベルでタスクのリストを設定できます。これにより、以下が定義されます。
- 接続する正確なソース DB とテーブルは何ですか?
- ターゲット表のデータを取得するために使用されるステートメント仕様。
- 変換ツール (存在する場合)。ソース データをターゲット テーブル データにマップする方法を定義します (1:1 でない場合)。
- データをロードする正確なターゲット データベースとテーブルは何ですか?
DMS タスクの構成は、JSON のような使いやすい形式で行われます。

最も単純なシナリオでは、ターゲット データベースで展開スクリプトを実行し、DMS タスクを開始するだけです。 しかし、それだけではありません。
1 回限りの完全なデータ移行

実行する最も簡単なケースは、リクエストがデータベース全体をターゲット クラウド データベースに 1 回移動することである場合です。 次に、基本的に、行う必要があるのは次のようになります。
- ソース テーブルごとに DMS タスクを定義します。
- DMS ジョブの構成を正しく指定してください。 これは、合理的な並列処理、キャッシュ変数、DMS サーバー構成、DMS クラスターのサイジングなどを設定することを意味します。これは、最適な構成状態の広範なテストと微調整を必要とするため、通常、最も時間のかかるフェーズです。
- 各ターゲット テーブルが、予期されるテーブル構造でターゲット データベースに作成 (空) されていることを確認します。
- データ移行が実行される時間枠をスケジュールします。 その前に、(パフォーマンス テストを実行して) 移行が完了するのに十分な時間枠があることを確認してください。 移行自体の間、ソース データベースはパフォーマンスの観点から制限される場合があります。 また、移行の実行中にソース データベースが変更されることはないと予想されます。 そうしないと、移行が完了すると、移行されたデータがソース データベースに格納されているデータと異なる可能性があります。
DMS の構成が適切に行われていれば、このシナリオで悪いことは何も起こりません。 すべてのソース テーブルが取得され、AWS ターゲット データベースにコピーされます。 唯一の懸念事項は、アクティビティのパフォーマンスと、すべてのステップでサイズが適切であることを確認して、不十分なストレージ容量が原因でアクティビティが失敗しないようにすることです。
増分日次同期

ここから事態は複雑になります。 つまり、世界が理想的であれば、おそらく常にうまく機能するでしょう. しかし、世界は決して理想的ではありません。
DMS は、次の 2 つのモードで動作するように構成できます。
- 全負荷- 上記で説明および使用されているデフォルトモード。 DMS タスクは、ユーザーが開始したとき、または開始がスケジュールされたときに開始されます。 完了すると、DMS タスクが完了します。
- 変更データ キャプチャ (CDC) – このモードでは、DMS タスクが継続的に実行されます。 DMS はソース データベースをスキャンして、テーブル レベルでの変更を探します。 変更が発生すると、変更されたテーブルに関連する DMS タスク内の構成に基づいて、ターゲット データベースに変更を直ちにレプリケートしようとします。
CDC を使用する場合は、さらに別の選択を行う必要があります。つまり、CDC がソース DB から差分変更を抽出する方法です。
#1。 Oracle REDO ログリーダー
1 つのオプションは、Oracle からネイティブ データベース REDO ログ リーダーを選択することです。CDC はこれを使用して変更されたデータを取得し、最新の変更に基づいてターゲット データベースに同じ変更をレプリケートします。
Oracle をソースとして扱う場合、これは当然の選択のように見えるかもしれませんが、落とし穴があります。Oracle の REDO ログ リーダーは、ソースの Oracle クラスタを利用するため、データベースで実行されている他のすべてのアクティビティに直接影響します (実際には、アクティブなセッションを直接作成します)。データベース)。
構成した DMS タスクが多いほど (または並列の DMS クラスターが多いほど)、Oracle クラスターのアップサイズが必要になる可能性が高くなります。基本的には、プライマリ Oracle データベース クラスターの垂直方向のスケーリングを調整します。 これは、ソリューションの総コストに確実に影響を与えます。毎日の同期がプロジェクトで長期間維持される場合はなおさらです。
#2。 AWS DMS ログマイナー
上記のオプションとは異なり、これは同じ問題に対するネイティブの AWS ソリューションです。 この場合、DMS はソース Oracle DB に影響を与えません。 代わりに、Oracle REDO ログを DMS クラスターにコピーし、そこですべての処理を行います。 これは Oracle リソースを節約しますが、より多くの操作が必要になるため、処理が遅くなります。 また、容易に推測できるように、Oracle REDO ログのカスタム リーダーは、おそらく Oracle のネイティブ リーダーよりも低速です。
ソース データベースのサイズとそこにある毎日の変更の数に応じて、最良のシナリオでは、オンプレミスの Oracle データベースから AWS クラウド データベースへのデータのほぼリアルタイムの増分同期が行われる可能性があります。
他のシナリオでは、まだほぼリアルタイムの同期にはなりませんが、ソース クラスターとターゲット クラスターのパフォーマンス構成と並列処理を調整するか、または実験することで、(ソースとターゲットの間の) 許容される遅延にできるだけ近づけることができます。 DMS タスクの量と CDC インスタンス間の分散。
また、可能なすべての変更がサポートされているわけではないため、CDC でサポートされているソース テーブルの変更 (たとえば、列の追加など) を知りたい場合があります。 場合によっては、ターゲット テーブルを手動で変更し、CDC タスクを最初からやり直すことが唯一の方法です (途中でターゲット データベース内の既存のデータがすべて失われます)。
物事がうまくいかないとき、何があっても

私はこれを難しい方法で学びましたが、DMS に関連して、毎日のレプリケーションの約束を達成するのが難しい特定のシナリオが 1 つあります。
DMS は、定義された速度でのみ REDO ログを処理できます。 タスクを実行する DMS のインスタンスが他にあるかどうかは問題ではありません。 それでも、各 DMS インスタンスは単一の定義された速度でのみ REDO ログを読み取り、それぞれが全体を読み取る必要があります。 Oracle REDO ログを使用するか、AWS ログ マイナーを使用するかは問題ではありません。 どちらもこの制限があります。
ソース データベースに 1 日のうちに多数の変更が含まれており、Oracle の REDO ログが毎日非常に大きくなる (500 GB 以上など) 場合、CDC は機能しません。 レプリケーションは、その日の終わりまでには完了しません。 未処理の作業が翌日に持ち越され、複製される新しい一連の変更がすでに待機しています。 未処理のデータの量は、日々増加するだけです。
この特定のケースでは、CDC はオプションではありませんでした (実行した多くのパフォーマンス テストと試行の後)。 少なくとも当日からのすべてのデルタ変更が同じ日にレプリケートされるようにする唯一の方法は、次のようにアプローチすることでした。
- あまり頻繁に使用されない非常に大きなテーブルを分離し、週に 1 回 (週末など) だけレプリケートします。
- それほど大きくはないが、まだ大きいテーブルのレプリケーションを複数の DMS タスクに分割するように構成します。 1 つのテーブルは、最終的に 10 個以上の分離された DMS タスクによって並行して移行され、DMS タスク間のデータ分割が明確になり (ここではカスタム コーディングが必要)、毎日実行されます。
- DMS のインスタンスをさらに (この場合は最大 4 つ) 追加し、それらの間で DMS タスクを均等に分割します。つまり、テーブルの数だけでなく、サイズによっても分割します。
基本的に、DMS のフル ロード モードを使用して毎日のデータを複製しました。
完璧な解決策ではありませんが、今でも存在し、何年も経った今でも同じように機能しています。 結局のところ、それほど悪い解決策ではないかもしれません。