
Drupal8/9でCSVファイルからデータを移行する-OSTraining
公開: 2022-06-29CSVファイルからDrupalデータベースにデータを移行するプロセスは、Drupalの統合されたMigrate APIと3つの追加のカスタムモジュール(Migrate Source CSV、Migrate Plus、およびMigrate Tools)を介して実行できます。
これはETL(Extract – Transform – Load)プロセスと呼ばれ、最初のステップで1つのソースからデータがフェッチされ、2番目のステップで変換され、最後に3番目のステップでDrupalデータベースの宛先にロードされます。
このチュートリアルでは、ライブラリデータベース用の12のブックノードの作成について説明します。 方法を学ぶために読み続けてください!
ステップ1–Drushと必要なモジュールをインストールする
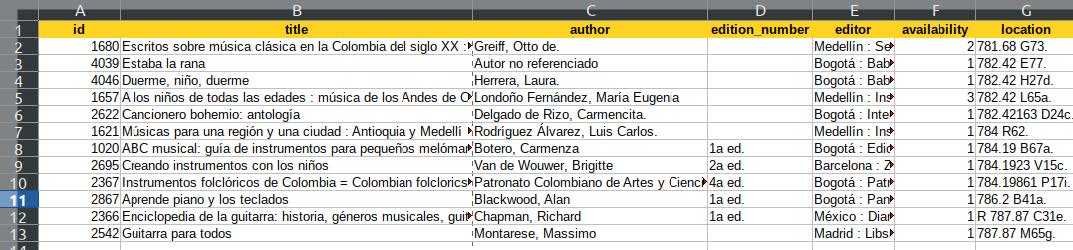
Drupalで移行を実行するには、Drushが必要です。 DrushはDrupalモジュールではなく、Drupalコマンドを実行するためのコマンドラインインターフェイスです。 Drushの最新バージョンをインストールするには、
- システムのターミナルアプリケーションを開きます
/webディレクトリの外にカーソルを置きます。- タイプ:
composer require drush/drush
これにより、Drupalインストールのvendor/bin/drushディレクトリ内にDrushがインストールされます。 ただし、drushコマンドを実行するたびに、 drushの代わりにvendor/bin/drushと入力するのは面倒です。
Drushランチャーを使用すると、プロジェクトごとに各Drupalインストールの特定のDrushバージョンを実行できます。
なぜこれが理にかなっているのですか?
プロジェクトごとに異なる要件があり、特定のDrushバージョンは依存関係の問題を回避するのに役立ちます。 一部のcontribモジュールは、最新バージョンのDrushでは正しく機能しない場合があります。
OSXおよびWindowsシステムの具体的な手順については、https://github.com/drush-ops/drush-launcher#installation—pharを参照してください。
Linuxシステムの場合:
- 次のように入力して、GitHubからdrush.pharという名前のファイルをダウンロードします。
wget -O drush.phar https://github.com/drush-ops/drush-launcher/releases/latest/download/drush.phar これにより、 drush.pharという名前のファイルがGitHubからダウンロードされます。
- 次のように入力して、ファイルを実行可能にします
chmod +x drush.phar - タイプ:
sudo mv drush.phar /usr/local/bin/ drush
これにより、 .pharファイルが$ PATHに移動し、グローバルコマンドとしてDrushが実行されます。
次に、移行を実行するために必要な寄稿モジュールをインストールします。
- 次のように入力します。
composer require drupal/migrate_tools composer require drupal/migrate_source_csvComposerがモジュールのダウンロードを完了したら、
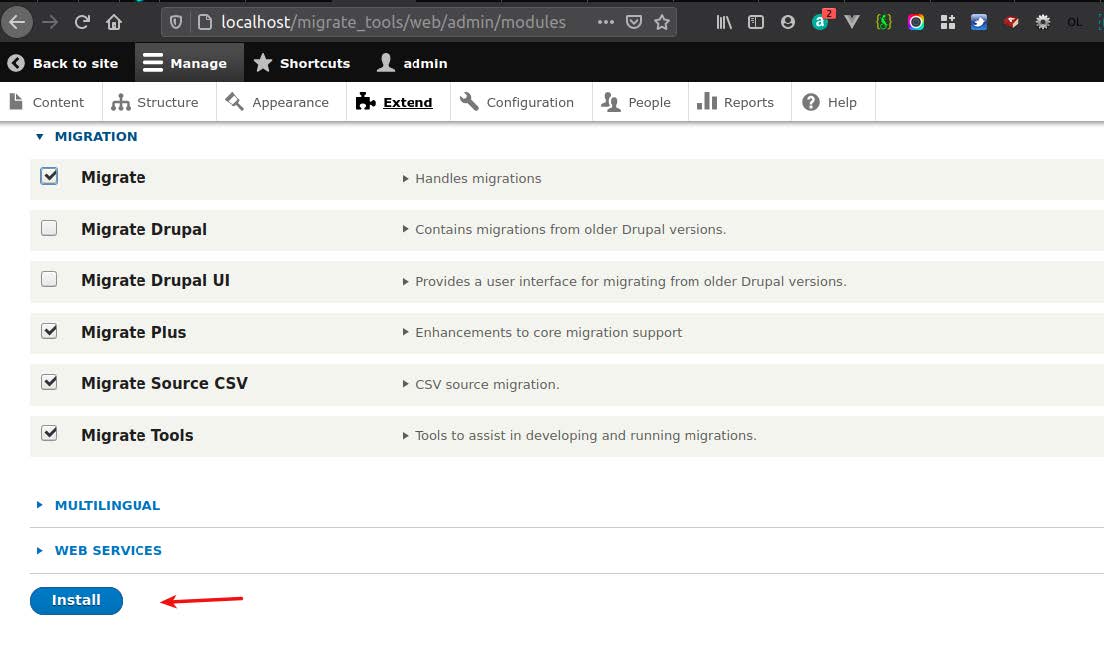
- ブラウザでDrupalバックエンドを開きます
- [拡張]をクリックします
- Migrate 、 Migrate Plus 、 Migrate Tools 、およびMigrateSourceCSVを有効にする
- [インストール]をクリックします
ステップ2–ETLプロセスの詳細
データの抽出、変換、およびロードのプロセスは、.ymlファイルで移行を定義し、それをDrushコマンドで実行することで実現できるため、Drupalデータベースに正しくデータを入力できます。
注意すべきいくつかの重要な事実があります:
- 各ステップは、Drupalプラグインを介して実行されます。
- プロセスの最初のステップ(ソース定義、つまり抽出)で1つのプラグインを使用し、最後のステップ(宛先定義、つまりロード)で1つのプラグインのみを使用できます。
- つまり、1つのソース(CSVファイル、JSONフィードなど)からのみデータをフェッチし、特定のエンティティバンドル(記事、ページ、カスタムコンテンツタイプ、ユーザー、または構成エンティティも同様です。
- Drupalで期待される形式に一致するように、データをモデル化するために必要な数のプラグインを使用できます。
- Drupalには、デフォルトで、定義ファイル内で使用できるソース/プロセス/宛先プラグインのリストがあります。
すべてのソースプラグインのリストを表示するには、
- ターミナルウィンドウを開きます
- タイプ:
drush ev "print_r(array_keys(\Drupal::service('plugin.manager.migrate.source')->getDefinitions()));" 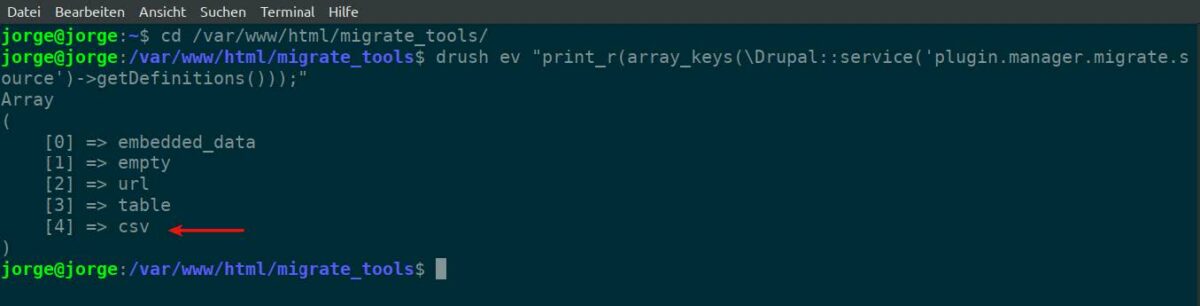
注意:ソースCSVモジュールの移行をすでに有効にしているため、csvプラグインがあります。
すべてのプロセスプラグインのリストを表示するには、
- 次のように入力します。
drush ev "print_r(array_keys(\Drupal::service('plugin.manager.migrate.source')->getDefinitions()));"そのリストは少し長くなっています。プロセスステップで必要な数のプラグインを使用できることを忘れないでください。
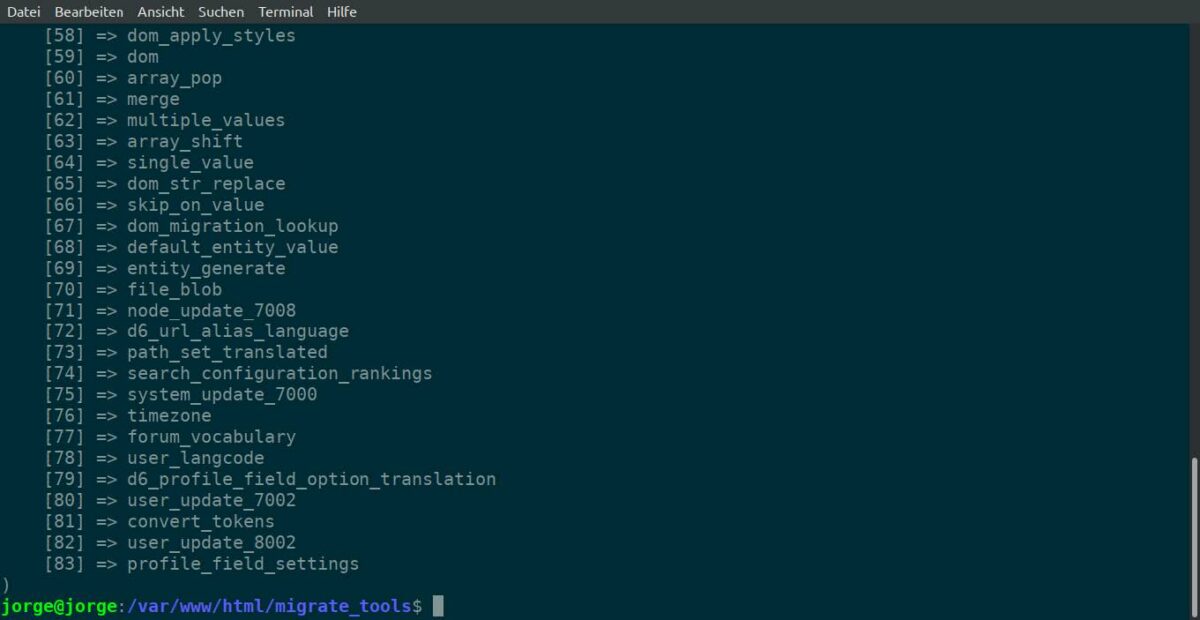
すべての宛先プラグインのリストを表示するには、
- 次のように入力します。
drush ev "print_r(array_keys(\Drupal::service('plugin.manager.migrate.destination')->getDefinitions()));" 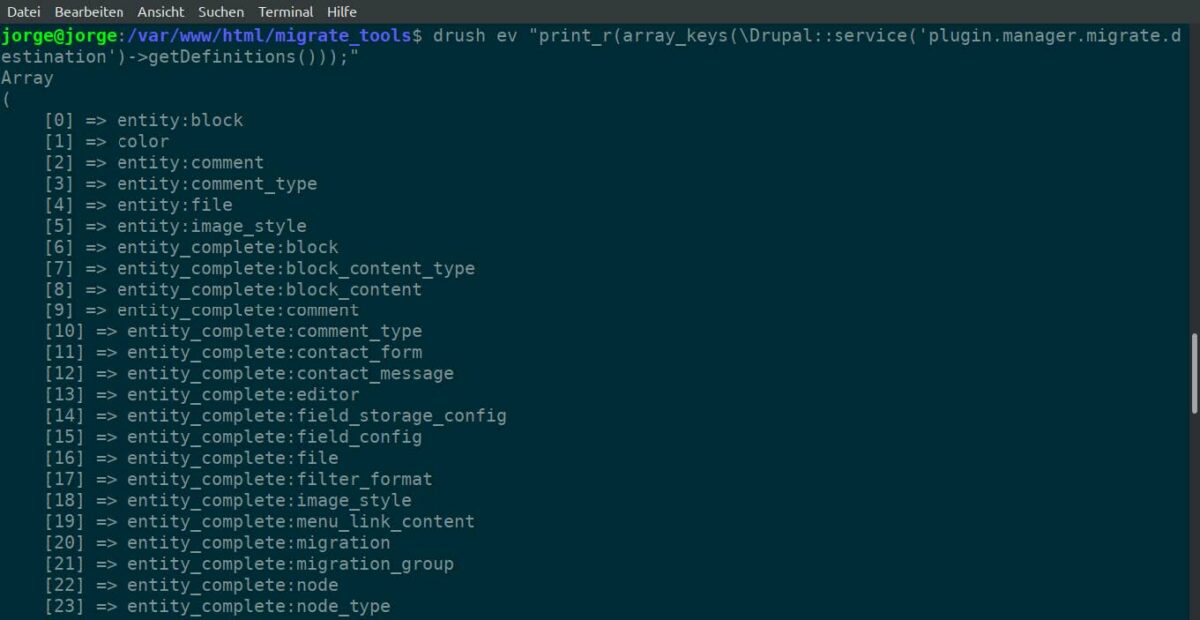
ステップ3–コンテンツタイプを作成する
- [構造]>[コンテンツタイプ]>[コンテンツタイプの追加]をクリックします
- 「本」コンテンツタイプを作成します
- [フィールドの保存と管理]をクリックします
- CSVファイルのタイトル行を使用してフィールドを作成します
edition_number列とeditor列の値を連結するので、この目的のためにデータベースに必要なフィールドは1つだけです。

注意:フィールド名(マシン名)は、CSVファイルの列名と正確に一致する必要はありませんが、少なくとも類似した単語と関連付けることは理にかなっています。これにより、プロセスステップでのフィールドマッピングが容易になります。
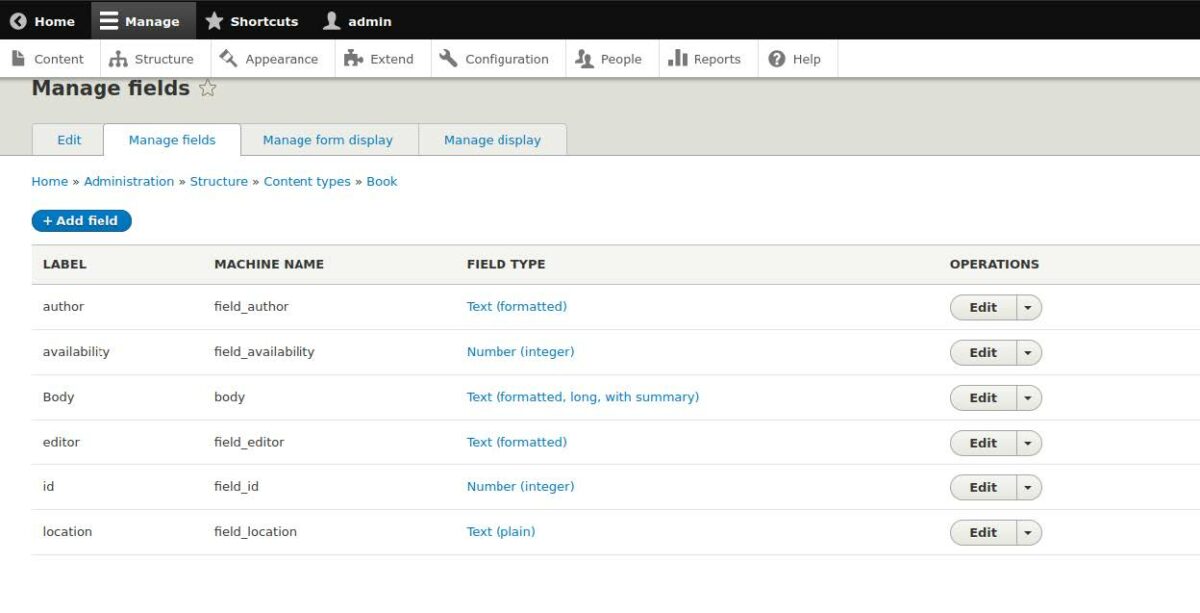
titleフィールドはすべてのDrupalノードに必須であるため、タイトルフィールドを作成する必要はありません。 本文フィールドはそのままにすることも、削除することもできます。これは、特定のコンテンツタイプで何をする予定かによって異なります。
ステップ4–移行定義ファイル
ソースステップ
- お好みのコードエディタを開きます
- 次のように入力します。
id: my_first_migration label: Migrate terms from a CSV source source: plugin: csv path: public://csv/library.csv header_row_count: 1 ids: [id] delimiter: ';' enclosure: "'"ファイルのIDはその名前と一致します。
ソースセクションでcontribモジュールMigrateSourceCSVのcsvプラグインを使用しています。
header_row_countオプションの数値1は、列タイトルの値を示します(これらはすべて最初の行に配置されます)。
ids定義は、CSVファイルの各レコード(この場合はinteger型のid列)の一意の識別子を提供します。 モジュールはここで配列を想定しているため、角かっこを忘れないでください。
delimiterとenclosureはCSVファイルの構造を参照します。私の特定のケースでは、「;」で区切られています。 文字列は「'」一重引用符で囲まれています。
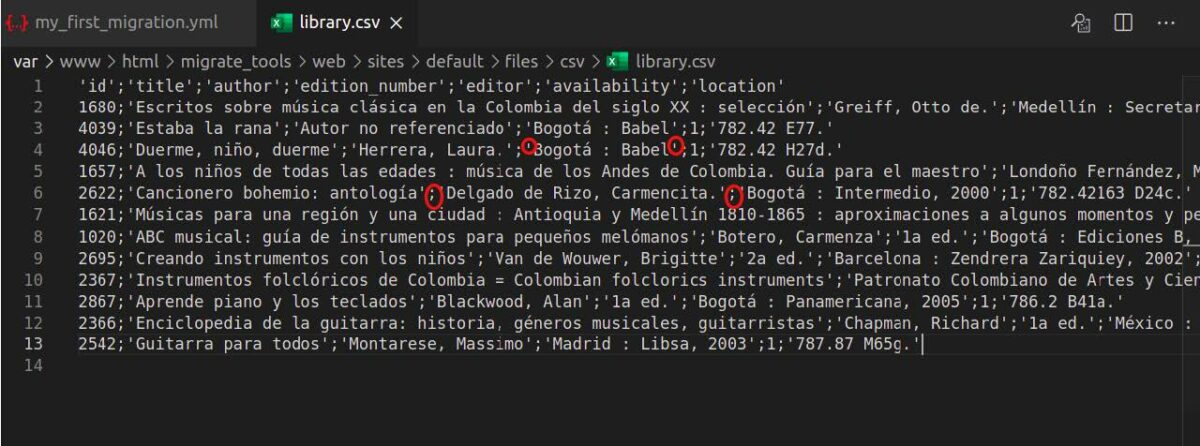
パスの定義にも注意してください。 ここにCSVファイルを配置する必要があるため、Drupalはそこからデータを読み取ることができます。
- ターミナルアプリケーションを開きます。
- タイプ:
mkdir web/sites/default/files/csv cp /home/ path/to /library.csv web/sites/default/files/csv/ chmod -R 777 web/sites/default/files/csv/この意志:
- Drupalインストールのパブリックフォルダー内に
csvというディレクトリを作成します。 - そのディレクトリ内にCSVファイルのコピーを配置します。
- システム内のすべての人がファイルにアクセスできるようにします(ソースプラグインを含む)。
プロセスステップ
ここで、CSVファイルの各列をコンテンツタイプのフィールドにマップします。
process: title: title field_id: id field_author: author field_location: location field_availability: availability field_editor: plugin: concat source: - editor - edition_number delimiter: ' ' type: plugin: default_value default_value: bookdrupal_machine_name:csv_column_nameの形式の最初の5つのキーと値のペアは、変更を実行せずにCSVレコードをデータベースフィールドにマップします。
field_editorフィールドは、2つの文字列( editorおよびedition_number列内の値)の連結を実行した結果になります。
区切り文字オプションを使用すると、両方の文字列(この場合は空白スペース)の間に区切り文字を設定できます。
default_valueプラグインは、この情報がソースデータで利用できないため、エンティティタイプを定義するのに役立ちます。
宛先ステップ
このプロセスの最後の部分は、宛先ステップです。
destination: plugin: entity:nodeコンテンツを移行しており、各レコードがノードになります。
ステップ5–移行を実行する
- [構成]>[構成の同期]>[インポート]>[単一アイテム]をクリックします
- ドロップダウンから[移行]を選択します
- .ymlファイルのコードをtextareaに貼り付けます
- [インポート]をクリックします
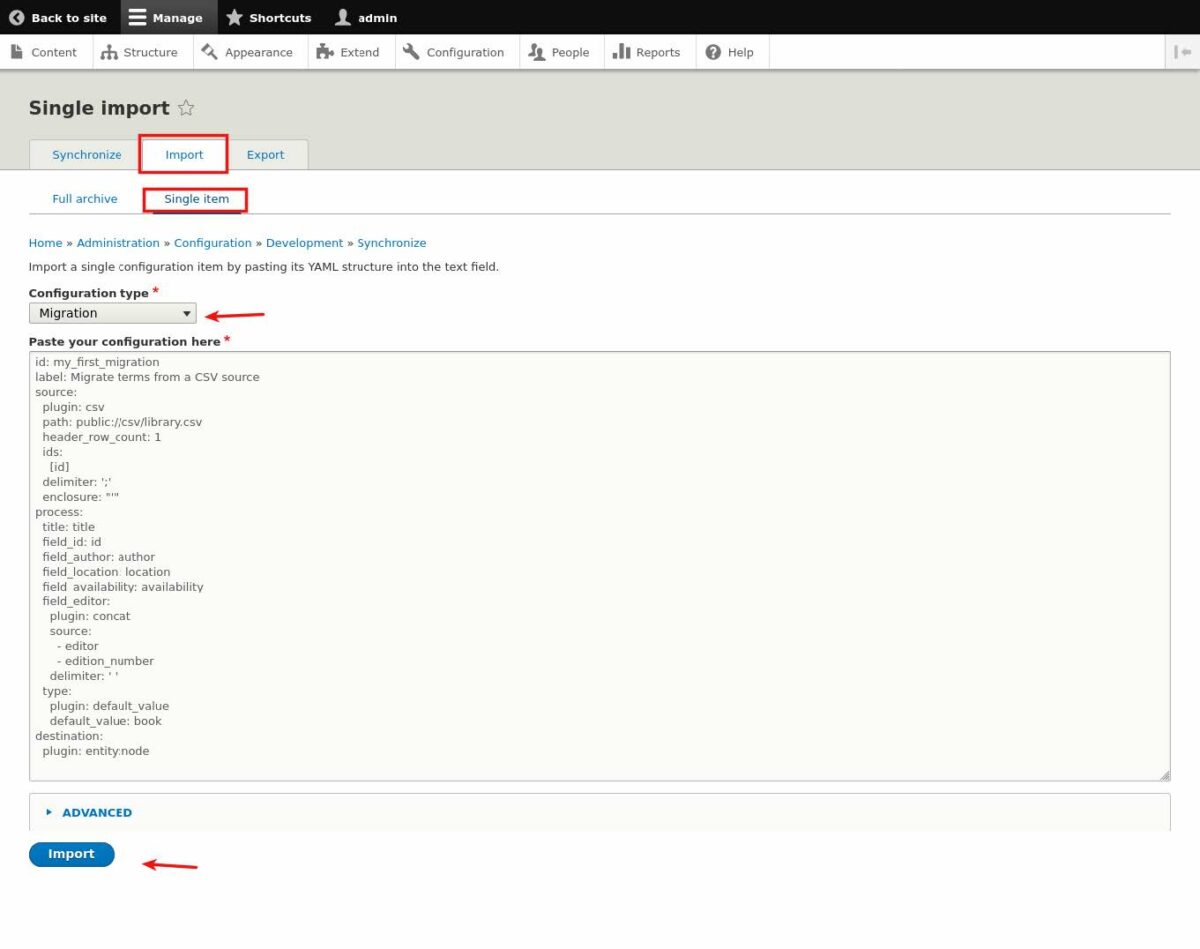
- [確認]をクリックして、構成を同期します。 「構成が正常にインポートされました」というメッセージが表示されます
- ターミナルアプリケーションに変更します。
- 次のように入力します。
drush migrate:import my_first_migration 
これで、サイトのコンテンツを確認できます。
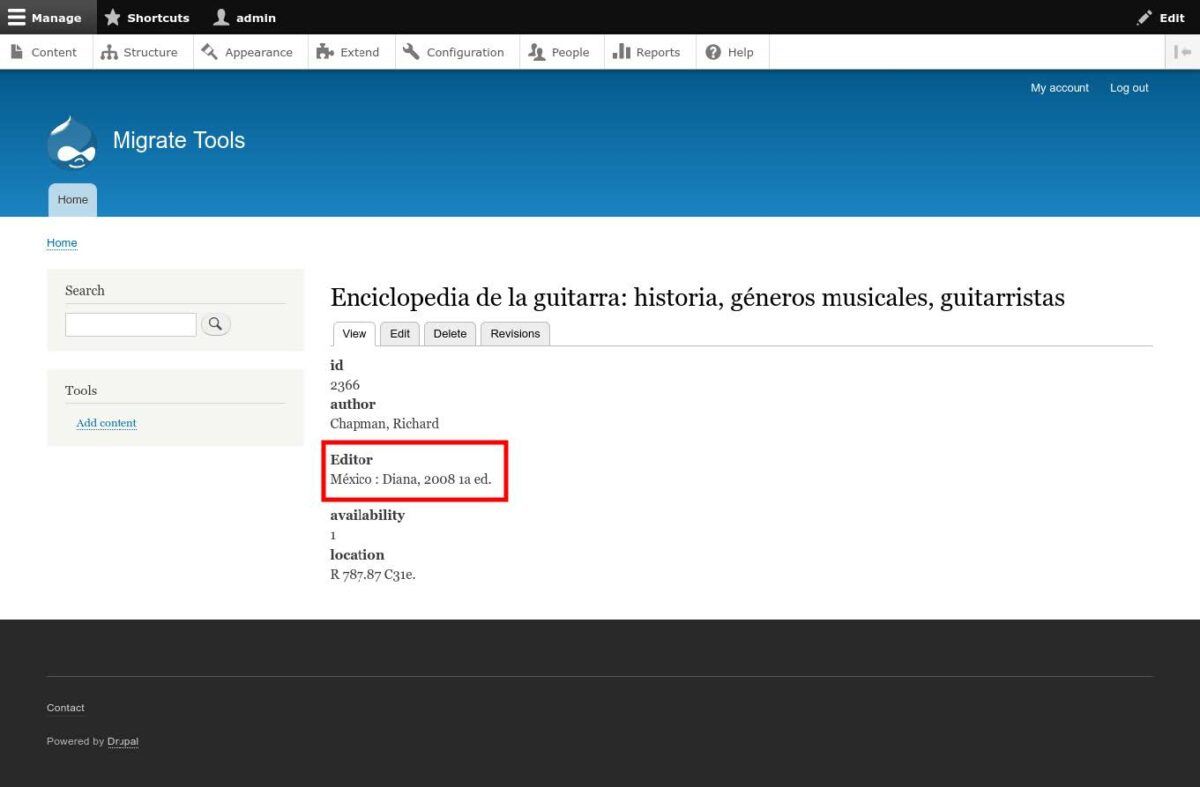
CSVファイルからDrupal8/9にデータを移行する基本原則を学びました。
すでに見てきたように、移行プロセスでは詳細に注意を払う必要があります。1つの小さなミスでサイト全体が破損する可能性があるため、最初にステージングサーバーで作業するようにしてください。 このチュートリアルが気に入っていただけたでしょうか。
読んでくれてありがとう!