
ナレッジグラフの質問応答
公開: 2023-01-25Google のナレッジグラフの質問回答機能とは何ですか?
ナレッジ グラフの質問応答 (KGQA) は、検索エンジンの結果ページ (SERP) で多くの領域を占めています。
Google のナレッジ グラフの質問応答機能は、クリックして Web サイトにアクセスすることなく、ユーザーのクエリに回答します。
すべての検索エンジンは、検索者の意図に基づいて最良の情報を返すことを望んでいます。 信頼できる回答者になるには、オンラインで知られる必要があります。 Google はクエリ ストリームを理解し、それらを使用してトピックを識別し、ウェブから信頼できるデータを抽出してオントロジーを更新します。 Google カード、ナレッジ グラフ (KG)、およびナレッジ コレクションは、ユーザーが Google と対話する方法です。 検索結果で「人々も質問する」のと同じように、ナレッジグラフの質問への回答は、人々を Google SERP に長く留まらせます。
目次
- Google のナレッジグラフの質問回答機能とは何ですか?
- ナレッジ パネルとナレッジ グラフの違いは何ですか?
- ナレッジパネルと Google ビジネス プロフィールの違いは何ですか?
- Google のナレッジ パネルと Knowledge Vault の違いは何ですか?
- 機械学習で複雑な質問に答える
- Google が役立つ質疑応答コンテンツを作成する方法
- ナレッジグラフはデータ関連の質問に答える
- KG 質問応答最適化の手順
- Google ナレッジ パネルの更新をリクエストする方法
- 質問応答 KG は、検証済みの知識の提供を目指しています
まず、基本的な語彙を確立しましょう。
ナレッジ パネルとナレッジ グラフの違いは何ですか?
ナレッジ グラフは、検索結果により豊富なナレッジ パネルを提供し、クエリに対する回答を返すために提供される場合があります。
ナレッジ パネルを Google ナレッジ グラフのフロントエンドとして表示すると役立ちます。 パネル グラフ データに表示されるよりも多くのデータが遅れています。 ナレッジ グラフ エンティティを確立すると、Google はそれを信頼し、正規の情報源と見なします。 テクノロジーの巨人は、デスクトップ ユーザー エクスペリエンスを補完するものとして KG を発明したのではありません。 これは、より優れたモバイル クエリの回答に対するニーズへの対応でした。 非常に多くのサイトが (そして今でも) モバイル デバイスではひどいものでした。 GKG は、ユーザーに正確な情報を提供することを意図しています。 その主な目的は、トラフィックをサイトに誘導することではありません。
以前は、Google は精度に基づいて Web ページをランク付けしていないようでした。 現在、その品質評価者は、経験、専門知識、権威性、および信頼性 (EEAT) を評価する方法について、より多くの指示を受けています。 回答の正確さは信頼の要素であり、そのガイドラインは、信頼が最も重要な要素であることを示しています。 対照的に、「正確さ」は、エンティティがナレッジ パネルに表示される要因です。
ナレッジ パネルは、Google の検索結果ページのリッチリザルト タイプの 1 つです。 それらは、特定のエンティティに関連する情報の精査された概要を検索者に提供します。
ナレッジパネルと Google ビジネス プロフィールの違いは何ですか?
Google ビジネス プロフィール (GBP) は、ナレッジ パネルとほとんど同じように見えます。 GBP は、特定の場所または指定されたサービス エリア内で顧客にサービスを提供する企業に固有のものです。 GBP アクセスにより、ビジネス オーナーは Google マップと検索でのデジタル プレゼンスを管理できます。 これは無料です。 対照的に、Google ナレッジ パネル (GKP) は、オンラインのエンティティに関する情報を使用して、Google によって自動的に生成されます。 その伝播と、その中で何を更新するかを完全に制御できます。
Google のナレッジ パネルと Knowledge Vault の違いは何ですか?
Google Knowledge Vault (GKV) は、機械で読み取り可能な百科事典を生成するアルゴリズムによって生成されると考えてください。
Google は、ナレッジ パネルに表示される情報が正しく有用であることが確認された場合にのみ、GKV に情報を追加します。 GKV は、機械学習と機械ロジックのみに基づいています。 複数のドメインからの個別のエンティティは、Google のグローバル ナレッジ アルゴリズムが指定されたエンティティを理解するのに十分な信頼を得た後にのみ、Knowledge Vault に移動されます。
「…Knowledge Vault を導入しました。これは、Web コンテンツからの抽出 (テキスト、表形式のデータ、ページ構造、および人間による注釈の分析によって得られたもの) と、既存の知識リポジトリから派生した事前知識を組み合わせた、Web 規模の確率論的知識ベースです。 これらの異なる情報源を融合するために、教師あり機械学習手法を採用しています。 Knowledge Vault は、以前に公開された構造化されたナレッジ リポジトリよりも大幅に大きく、校正された事実の正確性の確率を計算する確率論的推論システムを備えています。」 – Knowledge Vault: 確率論的知識融合への Web スケールのアプローチ[1]
機械学習で複雑な質問に答える
Google は毎日のクエリの 93% を受け取ります。 それが伝統的に検索エンジンとしてどのように機能し、最終的にあなたの製品やサービスに至るか。 質問応答機能を改善するために、Google の特許には次のように記載されています。
「説明されている手法により、機械学習ベースの方法を使用して自然言語の質問に答え、Web 検索から証拠を収集して分析することができます。」 – [2]
ただし、エンティティをナレッジ ベースに追加する前に、Google はまず質問されている質問をアルゴリズムで理解する必要があります。 質問を引き起こしたクエリの意図を理解しようとします。 あいまいなクエリの場合、セマンティック解釈は複雑な質問への回答を支援し、人間の認識を再現しようとします。 Web 記事では、公開日や最終更新日が表示されないことがよくあります。 対照的に、Google のナレッジ グラフは継続的に更新されます。 たとえば、この執筆のために記事を引用しようとしていましたが、最初に調査したところ、「この記事は 3 年以上前のものです」と表示されました。
MarketWatch は、「セマンティック知識ベース業界は、2023 年までに 330 億ドルの価値があり、残りの 10 年間で前年比 10% の成長を遂げる」と予測しています。 2023 年 1 月 18 日のセマンティック ナレッジ グラフの市場規模は、時間とコストに関連しており、2029 年までの今後数年間で業界が成長すると予想されます。
科学的イノベーションの増加が、より優れた KG にどれだけ捧げられているかは、驚くべきことです。 同様に、デジタル マーケターと SEO は、迅速に適応することで恩恵を受けます。
KG は一般に、事実を (主語エンティティ、関係、オブジェクト エンティティ) または (主語エンティティ、属性、値) の形式でトリプルとして格納する大規模なセマンティック ネットワークと見なされます。 グラフの端は、これらのエンティティ間の関係を表しています。 ほとんどの KG は、データを接続するためにさまざまな既存のデータ ソースの上に構築されています。 GPT3 内で GPTChat が登場するまで、Google は DBpedia、Freebase、YAGO などの他の大規模な KG に脅かされていませんでした。
より人間らしい質問への回答の推進
この競争は、情報へのリンクだけでなく、質問に対するより人間らしい回答を提供するために、Goole、OpenAI、Bing などの間で比類のない規模で行われています。 Google は、さまざまな大規模な AI 言語モデルを継続的に使用およびテストして、検索エンジンとナレッジ パネルを改善しています。
「ナレッジ グラフ」という用語には、膨大なリレーショナル ファミリーがあります。 ナレッジ グラフ、グラフ データベース、ナレッジ ボールト、ナレッジ パネル、ニューラル ネットワーク、機械学習、NLP、人工知能、リンクされたデータ、ナレッジ グラフ埋め込み、ナレッジ トランスファー、トランスファー ラーニング、ナレッジ表現学習 (KRL) などの分野が含まれます。 ! 有料検索や些細なサイト パフォーマンスの改善にお金を使うことは、質問に対する回答のコンテンツのギャップを効果的に埋めることと比較すると見劣りします。 以下の提案は、私自身の経験から来ています。
同社のデータ駆動型システムは、科学的アプローチとその応用に対する信頼を確立するために評価されています。 そのナレッジ グラフ (KG) の質問応答 (QA) 機能は、自然言語インターフェイスを介してアクセスできる複雑なデータ構造に依存しています。
Google が役立つ質疑応答コンテンツを作成する方法
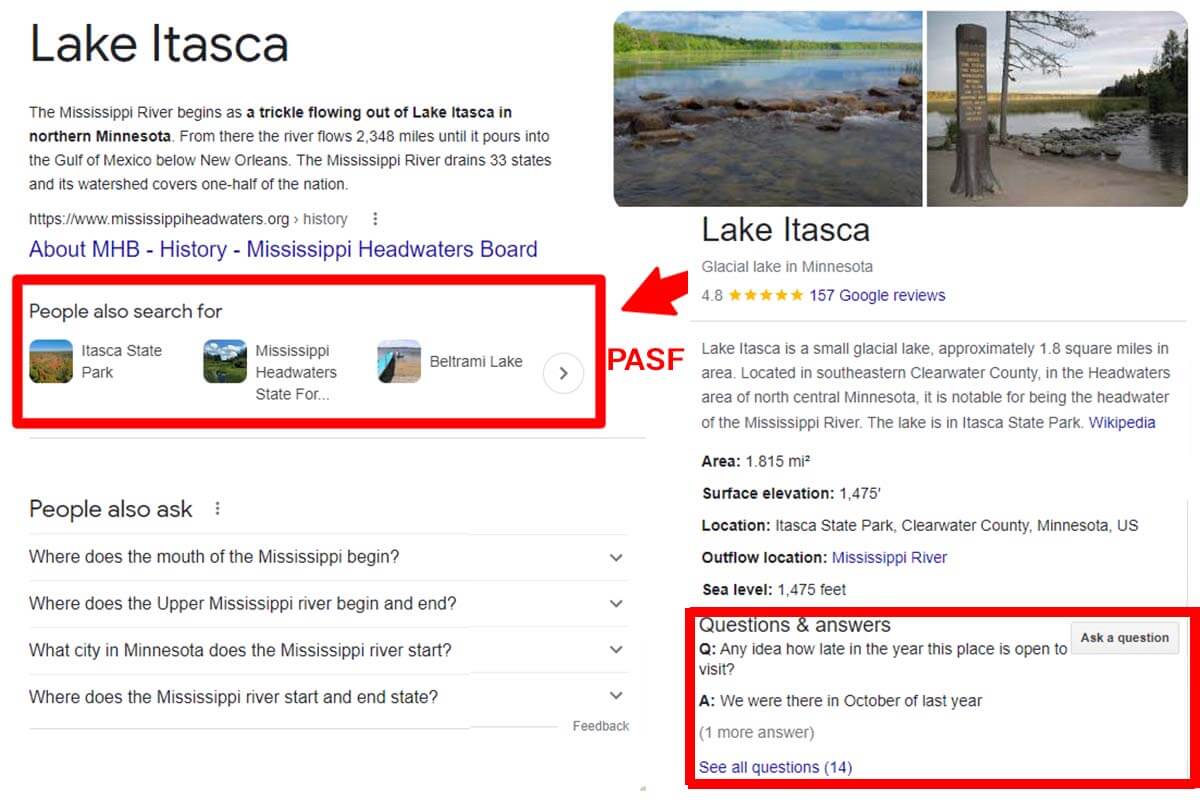
新しい SEOは、Google が一種の回答エンジンであることを理解し、それにフィードします。
検証データを公開すればするほど、テクノロジーの巨人はより多くのデータを接続できるようになります。 このようにして、エンティティに関する事実が何であるかを理解する際に、検索エンジンの作業を容易にします。 自分について話しているさまざまなサード パーティ全体で自分の構造化データを関連付けると、助けになります。 Google は、構造化データの実装がグラフまたはノード配列を介して接続されているかどうか、ページ上の独自のブロック内の個々の要素としてそれらを使用しているかどうかを優先しません。
- FAQ コンテンツ:会社は、Google が質問と回答の情報ページをクロールして取り込むのを支援するために、スキーマでマークアップされたデータベースを作成できます。 Google は、ウェブサイトのよくある質問のコンテンツを提供することを選択する場合があります。
- Web サイトのトピック クラスター:オントロジーが明確な情報を使用して、トピックの専門知識を示すことができます。 ナレッジ グラフは、Google が信頼するウェブ データを使用してエンティティを整理します。 さまざまなデータセットの主要な情報源になることができます。 このようにして、あなたはデータ パブリッシャーです。 ナレッジ パネルを要求している場合は、ナレッジ パネルの更新をトリガーするためのより確実で迅速な方法となる可能性があります。
- 正確な製品データベース:製品データベースを最新の状態に保つという非の打ちどころのない仕事をしている限り、Google は製品の事実に対して高い信頼と信頼を得ることができます。 オンラインのブランドや商品が明確で一貫していれば、Google はユーザーに正確で関連性の高い情報を表示する自信が持てます。 オンラインでのプレゼンスに関しては、すべてに一貫性を持たせてください。 綴り、タイトル、著者の略歴、勤務先などは同じにします。
- 画像データセットのアップロード:特定のデータベースからの画像を回答に関連付けて、ナレッジ グラフに入力できます。 製品 QA データセットの存在と正確性は、比較可能性を確保するのに役立ちます。
- FactClaim スキーマ マークアップを使用する: Google の検索結果は、多くの場合、人、場所、物に関する何十億もの事実のナレッジ グラフ リポジトリから取得されます。 あなたの意見を裏付ける事実に基づく統計コンテンツを含めることで、関連する事実に基づく情報源に対する認識と知識を示すことができます。
- 一貫した名前、住所、電話番号: 2023 年に向けて、Google ビジネス プロフィールを管理する方法が増えています。ただし、NAP は、Google がエンティティを識別する方法の基礎となります。 安定した住所を持ち、Google マップで割り当てられた住所を使用するのが最適です。 ナレッジ グラフは、Google マップと密接に関連しています。 これは、構造化されたデータ、つまり NAP の一貫性の形で構造化された情報 (名前、住所、電話番号) に基づいており、Google マップの更新を確実にする上でそれらがどのように違いを生むかを示しています。 同じタイプの一貫性が GKG を提供します。
- 自動化された Google ビジネス プロフィール FAQ テキスト レスポンス:自動化された FAQ レスポンスを Google ビジネス プロフィールに直接追加できます。 これは、質問応答付きの自動化された双方向の会話として機能します。
- 効果的な Google ポスト戦略を組み込む: Google Scholar の著者、著名なブランド、および米国で選出された役人は、ナレッジ パネルを主張する機会を活用していません。 これにより、Google 投稿へのアクセスが提供されます。これは、コンテンツのナレッジ グラフ戦略の一部である必要があります。
- オーディエンス データと市場調査を使用する:初期の市場調査では、革新的なコンテンツ キャンペーンと KG 戦略を強化できるオーディエンス データの洞察が得られます。 ナレッジ ベースは、最初に、質問が人々のクエリの意図にどの程度「重要」であるかに基づいて質問を分類します。
ウェブサイトで構造化データを使用する方法の詳細:
主に構造化データに取り組んでいる Google の Ryan Levering 氏は、Mastodon について次のように述べています。 それは一緒にどろどろになり、それがどこから来たのかはわかっていますが、通常は使用されません。 ただし、ここでの注意点は、複数のブロックで実行すると、競合/重複の問題が発生する場合があることです。 また、時間が経つにつれて、よりリッチで正確なセマンティクスにより、より多くの接続されたグラフが優先されます。 ページのさまざまなブロックからメイン エンティティと同じトップ レベルにあるもの (関連する製品など) に関する無関係なマークアップをスローするケースが今でも見られます。 そのため、ロジックを一元化することで、より一貫性/正確性が向上する場合があります。」
ナレッジグラフはデータ関連の質問に答える
グラフの目標は、用語、論理、正解のグラウンド トゥルースとして機能する能力です。
これは、ナレッジ グラフの仕組みに関する Google からの直接の引用です。
「Google の検索結果には、ナレッジ グラフ (人、場所、物に関する何十億もの事実のデータベース) からの情報が表示されることがあります。 ナレッジ グラフを使用すると、「エッフェル塔の高さは?」などの事実に基づく質問に答えることができます。 または「2016 年夏季オリンピックが開催された場所」 ナレッジ グラフに関する私たちの目標は、有用であると判断されたときに、公に知られている事実に基づく情報をシステムが発見して表示することです。」 – Google のナレッジ グラフのしくみ

相互に関連する関係と概念を示す情報をナレッジ グラフに入力できます。 チャットボット人工知能への巨額の投資が進行中ですが、現在、質問を理解して回答するためにはドメイン モデルが必要であることがわかっています。 機械学習は文章とユースケースの膨大な知識ベースを生成できますが、静的なチャットボットには限界があります。
Google は、データ ナレッジ グラフ エントリが更新される前に、まず信頼を確立するために、特定のトピックまたは主題に関する情報を収集します。 グラフは、Google が情報を簡単に保存および取得できるように、データ関連の質問に答えるのに役立ちます。 基本的には、質問を理解し、質問をナレッジ グラフに接続し、回答を推測することになります。
KG の質問の回答を最適化するための推奨手順:
- 何を、誰が、どこで、なぜ、どのように管理している出版物を探します。
- 外部から調達できる内部 QA データを特定します。
- それを見つける場所を学びましょう。
- すでにどのように使用されているか、誰によって、どのように使用される可能性があり、その理由を学びます。
- グラフを使用して、クラスター、コホート、およびグループを分析することにより、より多くの価値を提供する方法を特定します。
- アラートを設定して、エンティティ リレーションシップ内およびエンティティ リレーションシップとのコンテキスト、グループ シグナル、ダイナミクスに関する QA データ シグナルを監視します。
- グラフの QA コンテンツを管理およびフィードするためのメンテナンス時間をスケジュールします。
自然言語処理とグラフ アラインメント管理により、競合するエンティティまたは関係定義のケースを簡単に見つけることができます。 Google のパネル、グラフ、ボールトは、エンティティの解決に関するものです。
自分が管理しているプラットフォームで質問に答える前に、まず質問を知的に理解してください。 検索者の意図と、質問に必要な重要な情報を知っておく必要があります。 検索エンジンは、ナレッジ グラフの組み込みに役立つ名前付きエンティティを検索することで、重要な情報を抽出します。 自分自身を信頼してもらうために、彼らは KG で答えを推測する前に選択的です。
Google ナレッジ パネルの更新をリクエストする方法
Google は、主張されているナレッジ グラフの所有者に、更新を要求し、問題を報告する方法を提供します。 直接フィードバックを提供できるようになると、より簡単になります。 その即時の回答は、Web のクロールとユーザーのフィードバックから定期的に更新されます。
「また、情報がナレッジパネルに含まれているエンティティ (著名な個人やテレビ番組の作成者など) が自己権威であることもわかっており、これらのエンティティが直接フィードバックを提供する方法を提供しています。 したがって、表示される情報の一部は、独自のナレッジ パネルでファクトの編集を提案した検証済みのエンティティからのものである場合もあります。 – ナレッジパネルについて
「また、コンテンツ所有者から、主張したナレッジ パネルの変更を提案する人を含め、さまざまな方法で事実に関する情報を直接受け取ります。」 – Google のナレッジ グラフのしくみ
多くの人が、セマンティック ナレッジ グラフを取得する主なメリットは、ブランドの明確さ、データの回復、およびセールス エクスペリエンスを提供することだと考えています。 しかし、非常に多くの人が質問をするため、データを統合し、回答を提供するために使用する能力も考慮することが重要です。 このように価値があることを証明する小売業者ではないでしょうか?
質問応答情報の取得はどのように機能しますか?
Google は、信頼できる情報源から質問クラスタのコンテンツを集めます。
2023 年は、検索エンジンの結果ページ (SERP) で直接行われるリード コンバージョンがますます増えているため、ナレッジ グラフ戦略を改善する時代です。 Google は、エンティティについて信頼できるものを評価し、ナレッジ グラフ、ナレッジ パネル、およびナレッジ ボールトに含めるものを選択します。 ターゲットオーディエンスと顧客について知っています。 最良の回答を提供するために、ウェブ全体であなたの強みと知識を調整することを目指しています。 オーディエンス調査とSERP分析は、マーケティングへのアプローチを知らせることができます。
Google が Web ページから QA エンティティ情報を抽出すると、それらのエンティティを含む関連付けスコアと、他のエンティティとの関係が決定されます。 それらのエンティティのプロパティを説明する事実に基づく回答を重視します。 最善のマーケティング戦略を決定したら、SERP の結果を改善するために特定のマーケティング アクションを実行したマーケティング戦術に移行します。 現在も将来も、QA 情報検索と KG への通知方法を理解することは、効果的な SEO の重要な要素です。
Google の特許から、自然言語処理モデルが自然言語テキストの質問にどのように答えることができるかを学びます。
「コンピューティング システムには、機械学習された自然言語処理モデルが含まれています。このモデルには、自然言語テキストの本文を受信してナレッジ グラフを出力するようにトレーニングされたエンコーダー モデルと、自然言語の質問を受信してプログラムを出力するようにトレーニングされたプログラマー モデルが含まれています。 コンピューティングシステムは、実行時にプロセッサに動作を実行させる命令を格納するコンピュータ可読媒体を含む。 操作には、自然言語テキスト本文の取得、自然言語テキスト本文のエンコーダ モデルへの入力、エンコーダ モデルの出力としてナレッジ グラフの受信、自然言語質問の取得、自然言語質問のプログラマ モデルへの入力が含まれます。 、プログラマーモデルの出力としてプログラムを受け取り、ナレッジグラフでプログラムを実行して、自然言語の質問に対する答えを生成します。」 – N-Gram マシンによる自然言語処理、特許番号: WO2019083519A1、公開日: 2019 年 5 月 2 日[3]
ナレッジグラフの関連性スコアリング
機械語学習とデータ グラフを組み合わせて、聴衆の質問のコンテキストを回答に結び付けます。 Google KG の関連性スコアリングは、事前トレーニング済みの LM を使用して、質問応答のために条件付けられた KG のノードをスコアリングします。 Google には、KG 内で情報を重み付けするための一般的なフレームワークがあります。 その機械学習は、テキストと KG に対する共同推論を使用します。 このように、LM とグラフ ニューラル ネットワークを使用して、質問のコンテキストと回答内容を結び付けます。
全体として、Google KG は Web ページよりも効率的で信頼性があります。 それで、これはどこに行くのですか?
質問応答 KG は、検証済みの知識の提供を目指しています
Google ナレッジ グラフは、クエリに対する直接的な回答を提供します
クエリに応答して Google ナレッジ グラフが提供する事実は、最初は他の情報源から得られたものです。 (最近まで、これは主にウィキペディアとウィキデータからのものでした)。 Google は、KG に入力されているありとあらゆる情報を信頼するよう努めています。 クエリを正確に満たすのは難しいに違いありません。 たとえば、「Google の創設者は誰ですか?」と答えるには、ナレッジ グラフは、「[人物] によって設立された [組織]」という行に沿って、ここでトリプル (主語-述語-目的語) を抽出する必要があります。
ウィキペディアとウィキデータは、そのような正確な情報を提供します。
Electronic Arts のナレッジ グラフ ストラテジストである Aaron Bradly は、数年前に Twitter で興味深い質問を投げかけました。 「要するに、より大きな根底にある問題は、Google ナレッジ グラフによって提供される「事実」を事実として正しいと見なすべきかどうか (そして、Google 自身がグラフによって提供される「事実」を事実として正しいと見なすかどうかということです)。
ナレッジ グラフによって提供される「答え」と「事実」がユーザーによって信頼される必要がある理由はすぐにわかります。
Bradley 氏は続けて次のように述べています。 そのため、Google は情報源の信頼性を判断する方法を改善する方法を検討しています。 最終的に提供されるアサーションは「どこかから」です。 これは、応答のペイロード (特に音声) に来歴情報が含まれていない場合に問題になります。 ナレッジ アグリゲーター (ここでは Google) とナレッジ ユーザー (ここでは検索者) の両方が、これらの質問と回答の処理方法を改善するために取り組む必要があります。」 [4]
Google の創設者である Larry Page と Sergey Brin は、2019 年の退職後、Google の人工知能製品戦略をレビューするために再浮上しました。 彼らは、新しいチャットボット機能を Google の検索エンジンに追加する計画を承認し、アイデアを売り込みました。 Google の 2023 年 1 月の大規模なスタッフのレイオフは、AI を計画の中心に据えるという新たなコミットメントに続くものです。 [5]
Google ナレッジ グラフ検索 API を使用して、Google ナレッジ グラフ内のエンティティを検索または検索できます。 Google Cloud では、次のスキーマ マークアップ コードの例を提供しています: [6]
{
"@環境": {
"@vocab": "http://schema.org/"
}、
"@type": "アイテムリスト",
"itemListElement": [
{
"結果": {
"@id": "c-07xuup16g",
「名前」:「スタンフォード大学」、
"description": "カリフォルニア州スタンフォードの私立大学",
"詳細な説明": {
"articleBody": "スタンフォード大学、正式にはリーランド スタンフォード ジュニア ユニバーシティは、カリフォルニア州スタンフォードにある私立の研究大学です。キャンパスは 8,180 エーカーを占め、米国最大級であり、17,000 人以上の学生が在籍しています。 ",
"url": "https://en.wikipedia.org/wiki/Stanford_University",
"ライセンス": "https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License"
}、
"url": "http://www.stanford.edu/",
"画像": {
"contentUrl": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcTfPPf-ker0y_892m1wu8-U89furQgQ67foDFncY3r9sREpeWxV",
"url": "https://es.wikipedia.org/wiki/Archivo:Logo_of_Stanford_University.png"
}、
"識別子": [
{
"@type": "PropertyValue",
"propertyID": "googleKgMID",
"値": "/m/06pwq"
}、
{
"@type": "PropertyValue",
"propertyID": "googlePlaceID",
"値": "ChIJneqLZyq7j4ARf2j8RBrwzSk"
}、
{
"@type": "PropertyValue",
"propertyID": "wikidataQID",
「値」:「Q41506」
}
]、
"@タイプ": [
"場所"、
"組織"、
"映画館"、
"株式会社"、
"教育機関",
"もの"、
"大学"
]
}
}
]
}
スキーマ マークアップの実装が非常に役立つことがわかりました。 二重になっている場合は、構造化データ マークアップを追加することの長所と短所に関する記事をお読みください。
セマンティック検索と GKG を前進させる
この記事を読んでセマンティック検索とグラフ テクノロジの認識が高まり、そのような機会に積極的に対応したいとお考えの場合は、Jeannie Hill (651-206-2410) までお電話ください。
クエリエンティティ監査を取得して、個人またはビジネスのナレッジグラフを強化します
参考文献:
[1] https://research.google/pubs/pub45634/
[2] https://patents.google.com/patent/WO2014008272A1/en
[3] https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2019083519
[4] https://mobile.twitter.com/aaranged/status/1108444732282163200
[5] https://searchengineland.com/google-search-chatbot-features-this-year-391977
[6] https://cloud.google.com/enterprise-knowledge-graph/docs/search-api