
サイトのクロール、インデックス作成、XML サイトマップの背後にある 3 つのよくある誤解を暴く
公開: 2018-03-07私たちの多くは、XML サイトマップを備えた Web サイトを起動すると、すべてのページが自動的にクロールされ、インデックスに登録されると誤って信じています。
この点で、いくつかの神話や誤解が蓄積されています。 最も一般的なものは次のとおりです。
- Google はすべてのサイトを自動的にクロールし、高速に処理します。
- ウェブサイトをクロールするとき、Google はすべてのリンクをたどり、そのすべてのページにアクセスし、それらすべてをすぐにインデックスに含めます。
- XML サイトマップを追加することは、すべてのサイト ページをクロールしてインデックスに登録するための最良の方法です。
残念ながら、あなたのウェブサイトを Google のインデックスに登録するのは、もう少し複雑な作業です。 クロールとインデックス作成のプロセスがどのように機能するか、およびその中で XML サイトマップが果たす役割について理解を深めるために読み進めてください。
上記の神話を暴く前に、いくつかの重要な SEO の概念を学びましょう。
クロールは、Web 全体から URL を追跡して収集するために検索エンジンによって実装される活動です。
インデックス作成は、クロールに続くプロセスです。 基本的には、後で検索エンジン クエリの結果を提供するときに使用される Web データを解析して保存することです。 検索エンジン インデックスは、収集されたすべての Web データが今後の使用のために保存される場所です。
クロール ランクは、Google がサイトとそのページに割り当てる値です。 このメトリックが検索エンジンによってどのように計算されるかはまだ不明です。 Google は、インデックス作成の頻度がランキングに関係しないことを何度も確認しました。そのため、ウェブサイトのランキング機関とそのクロール ランクの間に直接的な相関関係はありません。
ニュース Web サイト、重要なコンテンツを含むサイト、および定期的に更新されるサイトは、定期的にクロールされる可能性が高くなります。
クロール バジェットは、検索エンジンが Web サイトに割り当てるクロール リソースの量です。 通常、Google はサイトのクロール ランクに基づいてこの金額を計算します。
クロール深度は、Google が Web サイトを探索する際に Web サイト レベルをドリルダウンする範囲です。
クロール優先度は、サイト ページに割り当てられた序数であり、クロールに関連する重要性を示します。
プロセスの基本をすべて理解したところで、XML サイトマップ、クロール、およびインデックス作成の背後にある 3 つの神話を理解しましょう。
目次
- 誤解 1. Google はすべてのサイトを自動的にクロールし、高速に処理します。
- お持ち帰り
- 誤解 2. すべてのサイト ページをクロールしてインデックスに登録するには、XML サイトマップを追加するのが最善の方法です。
- お持ち帰り
- 神話 3. XML サイトマップはクロールとインデックス作成の問題をすべて解決できる。
- お持ち帰り
誤解 1. Google はすべてのサイトを自動的にクロールし、高速に処理します。
Google は、Web データの収集に関しては、機敏で柔軟であると主張しています。
しかし、正直なところ、現在 Web には何兆ものページがあり、技術的には、検索エンジンはそれらすべてをすばやくクロールすることはできません。
クロール バジェットを割り当てる Web サイトの選択
スマートな Google アルゴリズム (クロール バジェットとも呼ばれます) は、検索エンジンのリソースを分配し、クロールする価値のあるサイトとそうでないサイトを判断します。
通常、Google は、設定された要件に対応し、他のサイトがどのように評価されるかを定義するための基礎となる、信頼できる Web サイトを優先します。
そのため、オーブンから出たばかりの Web サイト、またはスクレイピングされた、重複した、または薄いコンテンツを含む Web サイトがある場合、適切にクロールされる可能性は非常に低くなります。
クロール バジェットの割り当てに影響を与える可能性のある重要な要素は次のとおりです。
- ウェブサイトのサイズ、
- その一般的な健全性 (この一連の指標は、各ページに発生する可能性のあるエラーの数によって決まります)、
- インバウンドリンクと内部リンクの数。
クロール バジェットを獲得する可能性を高めるには、サイトが上記のすべての Google 要件を満たしていることを確認し、クロール効率を最適化してください (記事の次のセクションを参照してください)。
クロール スケジュールの予測
Google は Web URL をクロールする計画を発表していません。 また、検索エンジンがサイトを訪問する周期を推測するのは困難です。
あるサイトでは少なくとも 1 日に 1 回はクロールを実行し、別のサイトでは 1 か月に 1 回またはそれ以下の頻度でクロールを実行する場合があります。
- クロールの周期は、次の条件によって異なります。
- サイトコンテンツの質、
- ウェブサイトが配信する情報の新しさと関連性
- また、検索エンジンがサイトの URL をどの程度重要または人気があると考えているかについても説明します。
これらの要因を考慮して、Google が Web サイトにアクセスする頻度を予測することができます。
外部/内部リンクと XML サイトマップの役割
Googlebot は経路として、サイト ページとウェブサイトを相互に接続するリンクを使用します。 したがって、検索エンジンは、Web 上に存在する相互接続された何兆ものページに到達します。
検索エンジンは、必ずしもホーム ページからではなく、任意のページから Web サイトのスキャンを開始できます。 クロール開始ポイントの選択は、インバウンドリンクのソースによって異なります。 たとえば、製品ページの一部に、さまざまな Web サイトからのリンクが多数含まれているとします。 Google は点と点を結び、最初のターンでそのような人気のあるページにアクセスします。
XML サイトマップは、よく考えられたサイト構造を構築するための優れたツールです。 さらに、サイトのクロールのプロセスをより的を絞ったインテリジェントなものにすることができます。
基本的に、サイトマップはすべてのサイト リンクを含むハブです。 それに含まれる各リンクには、最終更新日、更新頻度、サイト上の他の URL との関係など、いくつかの追加情報を含めることができます。
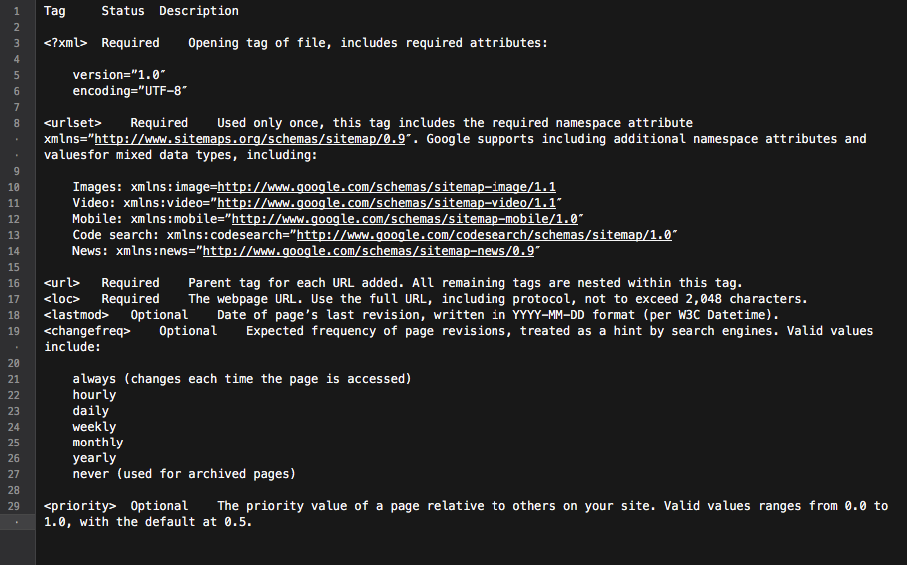 これらすべてが、Googlebot に詳細なウェブサイト クロール ロードマップを提供し、クロールをより多くの情報に基づいたものにします。 また、すべての主要な検索エンジンは、サイトマップに記載されている URL を優先します。
これらすべてが、Googlebot に詳細なウェブサイト クロール ロードマップを提供し、クロールをより多くの情報に基づいたものにします。 また、すべての主要な検索エンジンは、サイトマップに記載されている URL を優先します。
要約すると、サイト ページを Googlebot のレーダーに乗せるには、優れたコンテンツを含む Web サイトを構築し、その内部リンク構造を最適化する必要があります。
お持ち帰り
• Google がすべてのウェブサイトを自動的にクロールするわけではありません。
• サイト クロールの周期は、サイトとそのページの重要性や人気の程度によって異なります。
• コンテンツを更新すると、Google がより頻繁に Web サイトにアクセスするようになります。
• 検索エンジンの要件に対応していない Web サイトは、適切にクロールされない可能性があります。
• 内部/外部リンクを持たない Web サイトおよびサイト ページは、通常、検索エンジン ボットによって無視されます。
• XML サイトマップを追加すると、Web サイトのクローリング プロセスが改善され、よりインテリジェントになります。
誤解 2. すべてのサイト ページをクロールしてインデックスに登録するには、XML サイトマップを追加するのが最善の方法です。
すべてのウェブサイトの所有者は、Googlebot がすべての重要なサイト ページ (インデックスから非表示になっているページを除く) にアクセスし、新しいコンテンツや更新されたコンテンツを即座に探索することを望んでいます。
ただし、検索エンジンには、サイト クロールの優先順位に関する独自のビジョンがあります。
ウェブサイトとそのコンテンツのチェックに関しては、Google はクロール バジェットと呼ばれる一連のアルゴリズムを使用します。 基本的に、検索エンジンは独自のリソースを巧みに使用しながら、サイトのページをスキャンできます。
Web サイトのクロール バジェットの確認
サイトがどのようにクロールされているか、クロール バジェットに問題があるかどうかを把握するのは非常に簡単です。
あなたはただする必要があります:
- サイトと XML サイトマップのページ数を数えます。
- Google Search Console にアクセスし、[Crawl] -> [Crawl Stats] セクションに移動して、サイトで毎日クロールされるページの数を確認します。
- サイトの総ページ数を 1 日にクロールされるページ数で割ります。
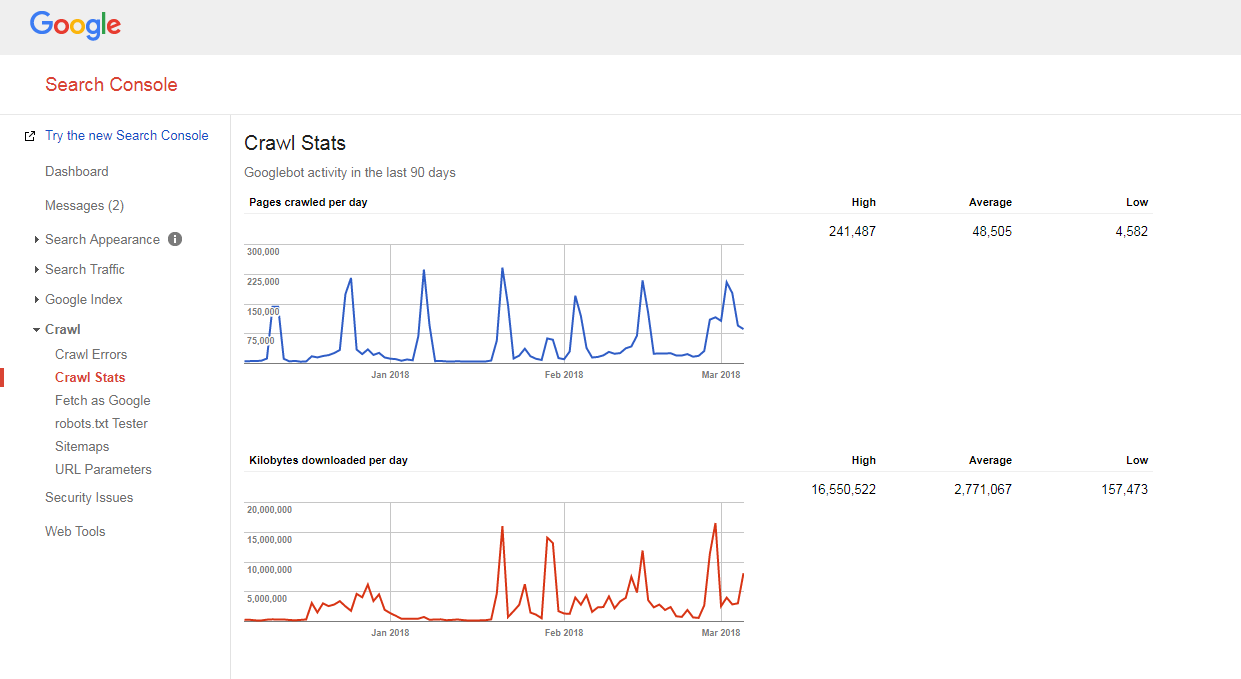 取得した数が 10 を超える場合 (サイトには、Google が毎日クロールするページ数の 10 倍のページがあります)、悪いニュースがあります。ウェブサイトにクロールの問題があります。
取得した数が 10 を超える場合 (サイトには、Google が毎日クロールするページ数の 10 倍のページがあります)、悪いニュースがあります。ウェブサイトにクロールの問題があります。
しかし、それらを修正する方法を学ぶ前に、別の概念を理解する必要があります.
クロール深度
クロールの深さは、Google が Web サイトを特定のレベルまで探索し続ける範囲です。
一般的に、ホームページはレベル 1、クリック 1 回のページはレベル 2 などと見なされます。
ディープ レベルのページはページランクが低く (またはまったくない)、Googlebot によってクロールされる可能性が低くなります。 通常、検索エンジンはレベル 4 より深く掘り下げません。
理想的なシナリオでは、特定のページは、ホームページまたはメインのサイト カテゴリから 1 ~ 4 クリック離れている必要があります。 そのページへのパスが長いほど、検索エンジンがそのページに到達するために割り当てるリソースが多くなります。
Web サイト上にいる場合、Google はパスが長すぎると推定し、それ以上のクロールを停止します。
クロールの深さと予算の最適化
Googlebot の速度低下を防ぎ、ウェブサイトのクロール バジェットと深さを最適化するには、次のことを行う必要があります。

- すべての 404、JS、およびその他のページ エラーを修正します。
ページ エラーが多すぎると、Google のクローラーの速度が大幅に低下する可能性があります。 すべてのメイン サイト エラーを見つけるには、Google (Bing、Yandex) ウェブマスター ツール パネルにログインし、ここに記載されているすべての手順に従ってください。
- ページネーションを最適化します。
ページネーション リストが長すぎる場合、またはページネーション スキームがリストの 2 ページ以上クリックできない場合、検索エンジンのクローラーはそのようなページの山を掘り下げるのを停止する可能性があります。
また、そのようなページあたりのアイテム数が少ない場合は、内容の薄いページと見なされ、クロールされません。
- ナビゲーション フィルターを確認します。
一部のナビゲーション スキームには、新しいページを生成する複数のフィルターが付属している場合があります (たとえば、階層化されたナビゲーションによってフィルター処理されたページ)。 このようなページにはオーガニック トラフィックが発生する可能性がありますが、検索エンジンのクローラーに不要な負荷がかかる可能性もあります。
これを解決する最善の方法は、フィルタリングされたリストへの体系的なリンクを制限することです。 理想的には、最大 1 ~ 2 個のフィルターを使用する必要があります。 たとえば、3 つの LN フィルター (色/サイズ/性別) を持つ店舗がある場合、2 つのフィルター (色-サイズ、性別-サイズなど) の体系的な組み合わせのみを許可する必要があります。 さらにフィルターの組み合わせを追加する必要がある場合は、それらへのリンクを手動で追加する必要があります。
- URL の追跡パラメーターを最適化します。
クローラーは大量の新しい URL を生成するため、さまざまな URL 追跡パラメーター (「?source=thispage」など) がクローラーのトラップを作成する可能性があります。 この問題は、これらのパラメータがユーザーの行動を追跡するために使用される「類似製品」ブロックまたは「関連記事」ブロックを含むページに典型的な場合です。
この場合のクロール効率を最適化するには、URL の末尾にある「#」の後ろに追跡情報を送信することをお勧めします。 このようにして、そのような URL は変更されません。 さらに、トラッキング パラメータを含む URL を、トラッキングなしで同じ URL にリダイレクトすることもできます。
- 過剰な 301 リダイレクトを削除します。
末尾のスラッシュなしでリンクされている URL が大量にあるとします。 検索エンジン ボットがそのようなページにアクセスすると、スラッシュ付きのバージョンにリダイレクトされます。
したがって、ボットは想定の 2 倍の作業を行う必要があり、最終的にはあきらめてクロールを停止する可能性があります。 これを避けるには、URL を変更するたびに、サイト内のすべてのリンクを更新するようにしてください。
クロールの優先度
前述のように、Google はクロールする Web サイトを優先します。 したがって、クロールされた Web サイト内のページで同じことを行うのも不思議ではありません。
ほとんどの Web サイトで、クロールの優先度が最も高いページはホームページです。
ただし、前述のように、場合によっては、最も人気のあるカテゴリまたは最も訪問された製品ページになることもあります. Googlebot によるクロール回数が多いページを見つけるには、サーバー ログを調べてください。
Google は、サイト ページのクロールの優先度に影響を与える可能性のある要因を公式に発表していませんが、次のようなものがあります。
- XML サイトマップへの組み込み (および最も重要なページの優先タグ* の追加)、
- インバウンドリンクの数、
- 内部リンクの数、
- ページの人気度 (訪問数)、
- ページランク。
しかし、検索エンジン ボットが Web サイトをクロールする方法を排除した後でも、ボットはそれを無視する可能性があります。 続きを読んで理由を学びましょう。
クロールの優先順位について理解を深めるには、Gary Illyes によるこの仮想基調講演をご覧ください。
XML サイトマップの優先度タグについて言えば、それらは手動で追加するか、サイトのベースとなっているプラットフォームの組み込み機能を利用して追加できます。 また、一部のプラットフォームでは、プロセスを簡素化するサードパーティの XML サイトマップ拡張機能 / アプリがサポートされています。
XML サイトマップの優先度タグを使用すると、サイト ページのさまざまなカテゴリに次の値を割り当てることができます。
- 0.0-0.3 ユーティリティ ページ、古いコンテンツ、重要度の低いページ、
- 0.4-0.7 をブログ記事、よくある質問と知識のあるページ、二次的に重要なカテゴリとサブカテゴリのページ、および
- メインのサイト カテゴリ、主要なランディング ページ、ホームページに 0.8 ~ 1.0。
お持ち帰り
• Google は、クロール プロセスの優先順位について独自のビジョンを持っています。
• 検索エンジンのインデックスに登録されるはずのページは、ホームページ、メインのサイト カテゴリ、または最も人気のあるサイト ページから 1 ~ 4 クリック離れている必要があります。
• Googlebot の速度低下を防ぎ、ウェブサイトのクロール バジェットとクロール深度を最適化するには、404、JS、その他のページ エラーを見つけて修正し、サイトのページネーションとナビゲーション フィルタを最適化し、過剰な 301 リダイレクトを削除し、URL の追跡パラメータを最適化する必要があります。
• 重要なサイト ページのクロール優先度を高めるには、それらが XML サイトマップ (優先度タグ付き) に含まれていること、他のサイト ページと適切にリンクされていること、他の関連する信頼できる Web サイトからのリンクがあることを確認してください。
神話 3. XML サイトマップはクロールとインデックス作成の問題をすべて解決できる。
XML サイトマップは、サイトの URL とそれらに到達する方法について Google に警告する優れたコミュニケーション ツールですが、サイトが検索エンジン ボットによってアクセスされることを保証するものではありません (すべてのサイト ページをインデックスに含めることは言うまでもありません)。 .
また、サイトマップはサイトのランキングを向上させるのに役立たないことを理解する必要があります. ページがクロールされて検索エンジンのインデックスに含まれたとしても、そのランキングのパフォーマンスは、他の多くの要因 (内部リンクと外部リンク、コンテンツ、サイトの品質など) に左右されます。
ただし、XML サイトマップを正しく使用すれば、サイトのクロール効率を大幅に向上させることができます。 以下は、このツールの SEO の可能性を最大化する方法に関するアドバイスです。
一貫性を保つ
サイトマップを作成するときは、Google クローラーのロードマップとして使用されることに注意してください。 したがって、間違った方向を提供して検索エンジンを誤解させないことが重要です。
たとえば、XML サイトマップにいくつかのユーティリティ ページ (お問い合わせ、TOS ページ、ログイン ページ、失われたパスワードの復元ページ、コンテンツ共有ページなど) を含める場合があります。
これらのページは通常、noindex robots メタ タグを使用してインデックス作成から隠されているか、robots.txt ファイルで許可されていません。
そのため、それらを XML サイトマップに含めても、Googlebot を混乱させるだけであり、Web サイトに関する情報を収集するプロセスに悪影響を与える可能性があります.
定期的に更新する
Web 上のほとんどの Web サイトは、ほぼ毎日変更されます。 特に、製品とカテゴリが定期的にサイト内外でシャッフルされる e コマース Web サイト。
Google に十分な情報を提供するには、XML サイトマップを最新の状態に保つ必要があります。
一部のプラットフォーム (Magento、Shopify) には、XML サイトマップを定期的に更新できる機能が組み込まれているか、このタスクを実行できるサードパーティ ソリューションがサポートされています。
たとえば、Magento 2 では、サイトマップの更新サイクルの周期を設定できます。 プラットフォームの構成設定でこれを定義すると、サイト ページが一定の間隔 (時間、週、月) で更新され、サイトに別のクロールが必要であることをクローラーに通知します。
詳細については、ここをクリックしてください。
ただし、サイトマップの更新の優先度と頻度を設定することは役立ちますが、実際の変更に追いつかず、真の全体像が得られない場合があることに注意してください。
そのため、最近行ったすべての変更がサイトマップに反映されていることを確認してください。
 サイト コンテンツをセグメント化し、適切なクロール優先度を設定する
サイト コンテンツをセグメント化し、適切なクロール優先度を設定する
Google は、サイト全体の品質を測定し、最適で最も関連性の高い Web サイトのみを表示するよう努めています。
しかしよくあることですが、すべてのサイトが同じように作られ、真の価値を提供できるわけではありません。
たとえば、Web サイトが 1,000 ページで構成されている場合、そのうちの 50 ページのみが「A」グレードです。 他のものは、純粋に機能するか、コンテンツが古いか、コンテンツがまったくないかのいずれかです。
Google がそのような Web サイトの調査を開始した場合、価値の低いページ、スパム行為のあるページ、または古いページの割合が高いため、おそらく非常にくだらないと判断するでしょう。
そのため、XML サイトマップを作成するときは、Web サイトのコンテンツをセグメント化し、検索エンジン ボットを適切なサイト領域のみに誘導することをお勧めします。
また、覚えているかもしれませんが、XML サイトマップで最も重要なサイト ページに割り当てられたプライオリティ タグも非常に役立ちます。
お持ち帰り
• サイトマップを作成するときは、noindex robots メタ タグでインデックスから非表示になっているページや、robots.txt ファイルで許可されていないページを含めないようにしてください。
• Web サイトの構造とコンテンツに変更を加えた直後に、XML サイトマップを (手動または自動で) 更新します。
• サイト コンテンツをセグメント化して、«A» グレードのページのみをサイトマップに含めます。
• さまざまなページ タイプにクロールの優先度を設定します。
基本的にはそれだけです。
このトピックについて何か言いたいことがありますか? 以下のコメント セクションで、クロール、インデックス作成、またはサイトマップに関するご意見をお気軽に共有してください。