
Apache Solr を最大限に活用する: 検索インデックス作成の技術的調査
公開: 2023-02-21検索機能は、ユーザーが探しているものを簡単かつ迅速に見つけられるようにすることで、Web サイトのユーザー エクスペリエンスを向上させます。 大規模な Web サイト、e コマース サイト、および動的コンテンツを含むサイト (ニュース サイト、ブログ) の場合はなおさらです。
Apache Solr は、あらゆる規模の Web サイトで使用されている最も人気のある検索プラットフォームの 1 つです。 記事、製品、顧客レビューなどの大量のデータを検索できる、Java ベースのオープンソース検索エンジンです。 この記事では、Apache Solr について詳しく説明します。
Drupal で Apache Solr を構成する方法については、この記事をご覧ください。

Apache Solr が人気の理由
Apache Solr は高速かつ柔軟で、全文検索、ヒットの強調表示(一致する検索語を強調表示)、ファセット検索(より洗練された検索)、リアルタイムのインデックス作成(新しいコンテンツをすぐにインデックス作成できるようにする)、動的クラスタリング(検索結果をグループに整理する)、データベース統合、NoSQL 機能(非リレーショナル データベース)、豊富なドキュメント処理(PDF、MS Office、Open Office などのさまざまなドキュメント形式のインデックスを作成するため)。
Apache Solr に関するいくつかの知っておくべき事実:
- 当初は CNET ネットワークスによって開発されました。 ウェブサイトや記事の検索エンジンとして。 その後、オープンソース化され、トップレベルの Apache プロジェクトになりました。
- PHP、Java、Python、Ruby などの複数のプログラミング言語をサポートします。 また、これらの言語用の API も提供します。
- 地理空間検索のサポートが組み込まれており、その場所に基づいてコンテンツを検索できます。 不動産サイトや旅行サイトなどのサイトで特に役立ちます。
- スペル チェック、オートコンプリート、カスタム検索などの高度な検索機能を、API とプラグインを介してサポートします。
- インデックス作成と検索に Lucene を使用します。
ルセンとは
Apache Lucene は、検索や情報取得をアプリケーションに簡単に追加できるオープンソースの Java 検索ライブラリです。 用途が広く、強力で、正確で、効率的な検索アルゴリズムで動作します。
Lucene は全文検索機能で知られていますが、ドキュメントの分類、データ分析、および情報検索にも使用できます。 また、ドイツ語、フランス語、スペイン語、中国語、日本語など、英語以外の多くの言語もサポートしています。
インデックス作成とは
すべての検索エンジンはインデックス作成から始まります。 索引付けとは、迅速な検索を容易にするために、元のデータを非常に効率的な相互参照ルックアップに処理することです。
検索エンジンはデータを直接インデックスしません。 テキストは、最初にトークン (原子要素) に分割されます。 検索とは、検索インデックスを調べて、クエリに一致するドキュメントを取得するプロセスです。
索引付けの利点
- 高速で正確な情報検索 (収集、解析、保存)
- インデックスを作成しないと、検索エンジンはすべてのドキュメントをスキャンするのにより多くの時間を必要とします
インデックス作成の流れ
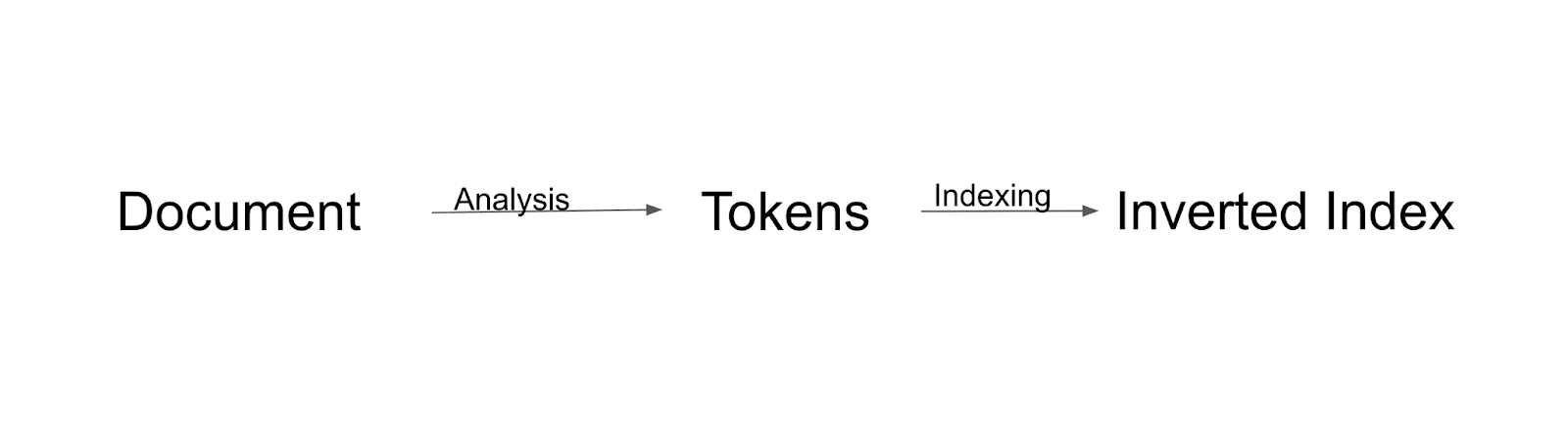
まず、ドキュメントが分析され、トークンに分割されます。 これらのトークンはすべて、逆インデックスにインデックス付けされます。 逆索引は、Solr が索引を作成する方法です。
逆索引付けの仕組み
3 つのドキュメントがあるとします。
- チョコレートが大好き (D 1)
- チョコレートケーキを注文しました(D2)
- 大きなバニラケーキを用意しました (D 3)
トークン化される方法は、下の表の 2 列目に示されているとおりです。

「チョコレート」はD1とD2で利用可能
「ケーキ」はD2とD3で利用可能
「ビッグ」はD3で利用可能
「オーダー済み」はD2で利用可能
「準備完了」はD3で利用可能
「バニラ」はD3で利用可能です
「私」や「愛」などの単語がトークン化されていないことに気付くでしょう。 これらはストップ ワードと呼ばれ、Solr によってインデックスが作成されたり、検索されたりすることはありません。
そのため、誰かが「Chocolate Cake」という用語を検索すると、エンジンはインデックスを調べます。 ドキュメントを探す代わりに、まずインデックスを調べて、「Chocolate」と「Cake」という単語がどのドキュメントに該当するかを調べます。 これにより、特定のドキュメントのみを簡単かつ迅速に取得できます。 これは、逆索引付けと呼ばれます。
ストレージ スキーマ
Apache Solr はドキュメント ベースのストレージ スキーマを使用し、すべてのデータをコレクション内の個別のドキュメントとして保存します。 これにより、データの効率的かつ柔軟な保存と検索が可能になります。
Drupal では、各ノードはドキュメントと見なされます。 そのため、ノードを Apache Solr にインデックス付けすると、それはドキュメントと見なされます。 各ドキュメントには複数のフィールドを含めることができます。 Lucene には共通のグローバル スキーマがありません。 つまり、Apache Solr の各ドキュメントの任意のタイプのフィールドにインデックスを付けることができます。

Apache Solr のインストール方法
- まず、システムに Java がインストールされていることを確認します。
- 次に、ここから Solr をインストールしましょう: https://solr.apache.org/downloads.html
- Solr をダウンロードして解凍します。
- Solr フォルダーでこのコマンドを実行します。
◦ bin/solr -e techproducts
これにより、デモ用のダミー コアが作成され、Solr サーバーも起動します。
- サーバーが起動したら、ブラウザに移動して「http://localhost:8983/」と入力します。
- Solr がダミー コアで正常にインストールされていることを確認します。
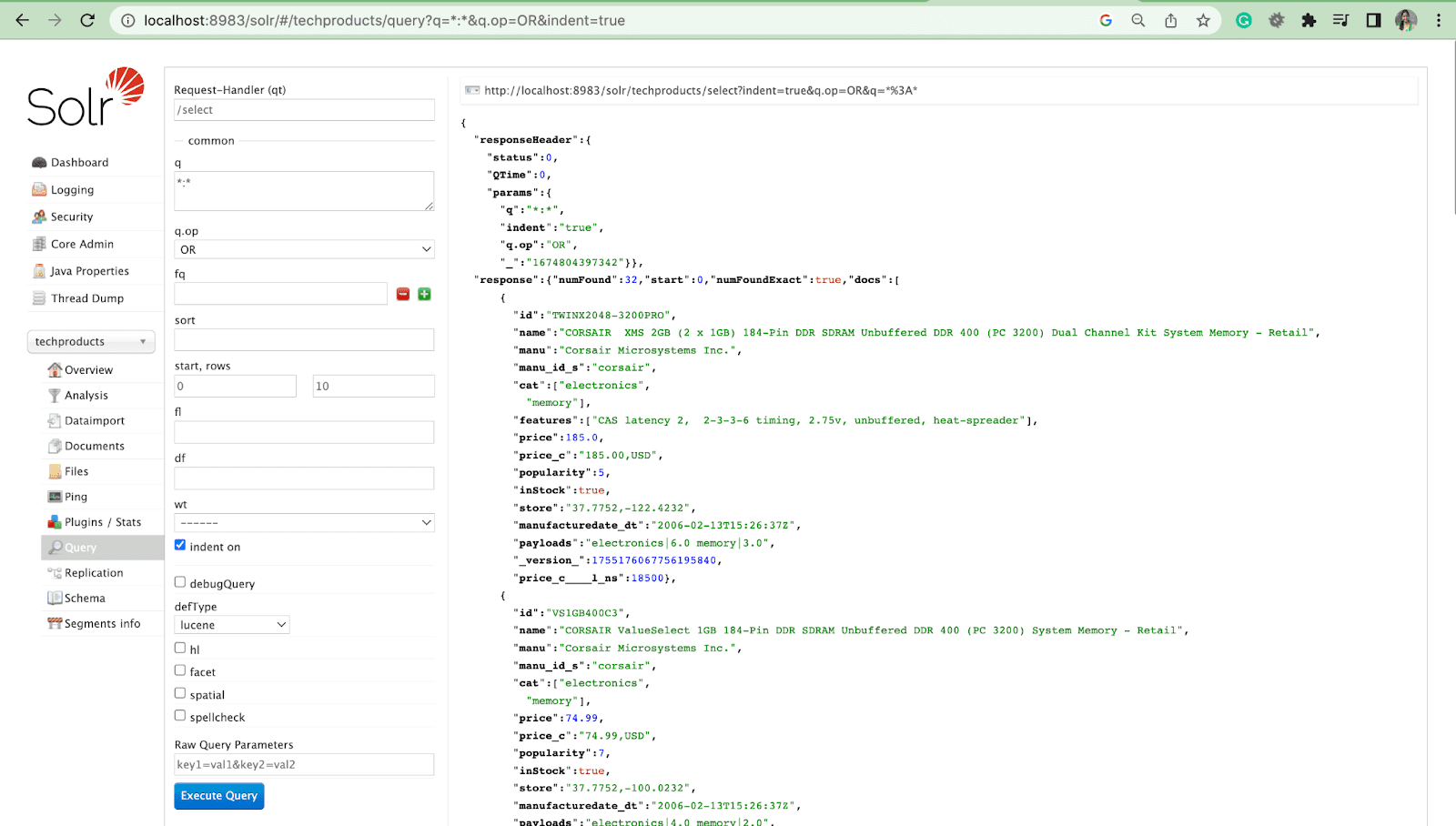
ディレクトリ構造
Solr をインストールすると、次のような多くのフォルダーが表示されます。
ドキュメント- Solr に関するドキュメントが含まれています
Dist - Solr メイン .jar ファイル
Contrib - アドオン プラグインと Solr の特殊な機能が含まれています
Bin - Solr のスクリプト
例- solr 機能のデモが含まれています
サーバー- Solr の心臓部。 Solr Web アプリケーション、ログ、Solr コアが含まれています
設定ファイル
コアを作成するには、2 つのファイルが必須です。

- スキーマ.xml
- Solrconfig.xml
スキーマ.xml
- これには、サポートする予定のフィールドのタイプと、それらのタイプを分析する方法が含まれます。
Solrconfig.xml
- リクエスト ハンドラー、リクエスト ディスパッチャー、クエリ コンポーネント、更新ハンドラーなど、Solr コアの動作を制御するさまざまな設定が含まれています。
Solr でのクエリ
次に、Solr 管理 UI で Solr の結果を照会する方法を見てみましょう。
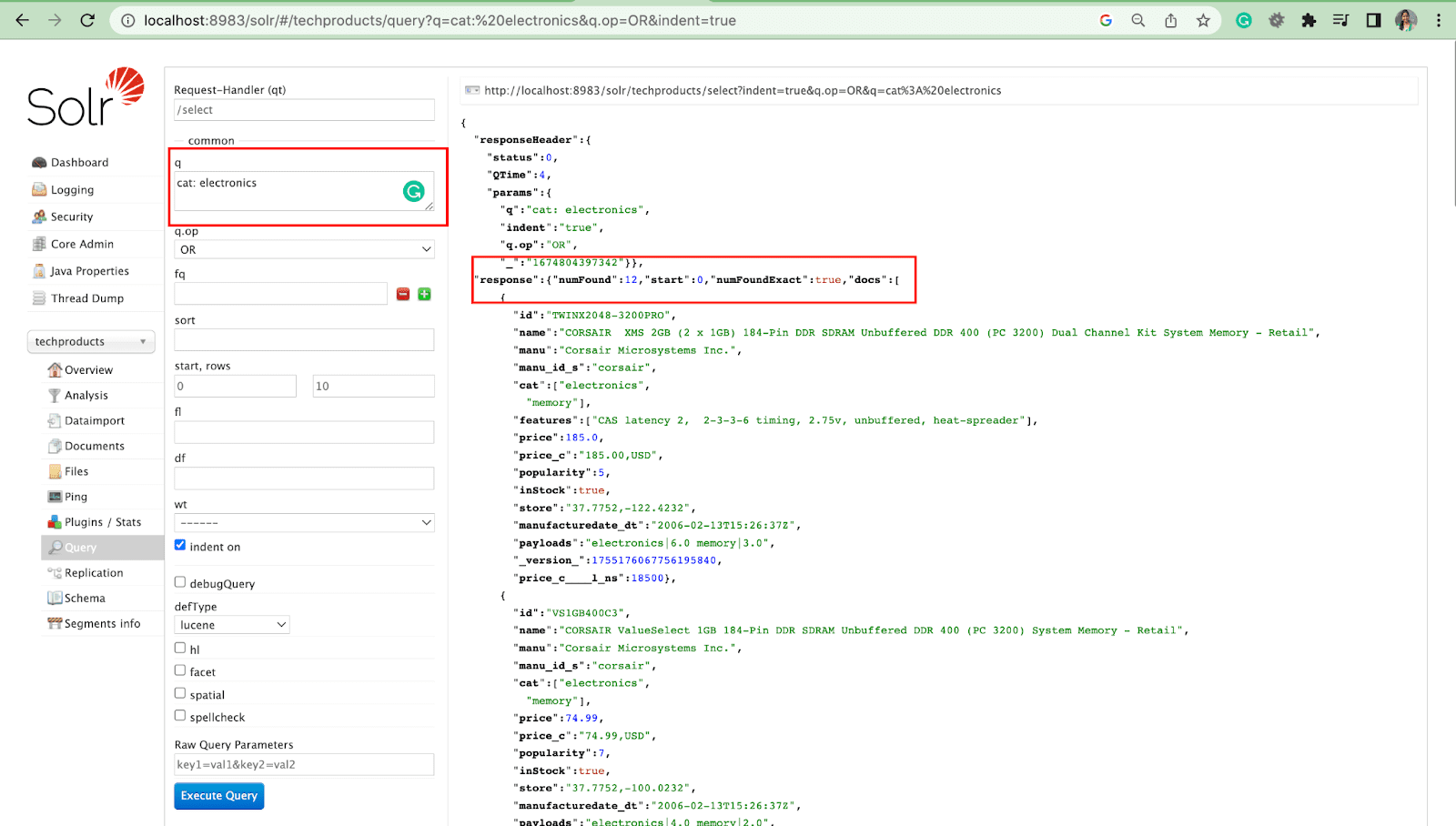
クエリ パラメータ
- ローカル パラメーターは、クエリ パラメーターに固有の Solr 要求の引数です。
例: 猫: エレクトロニクス
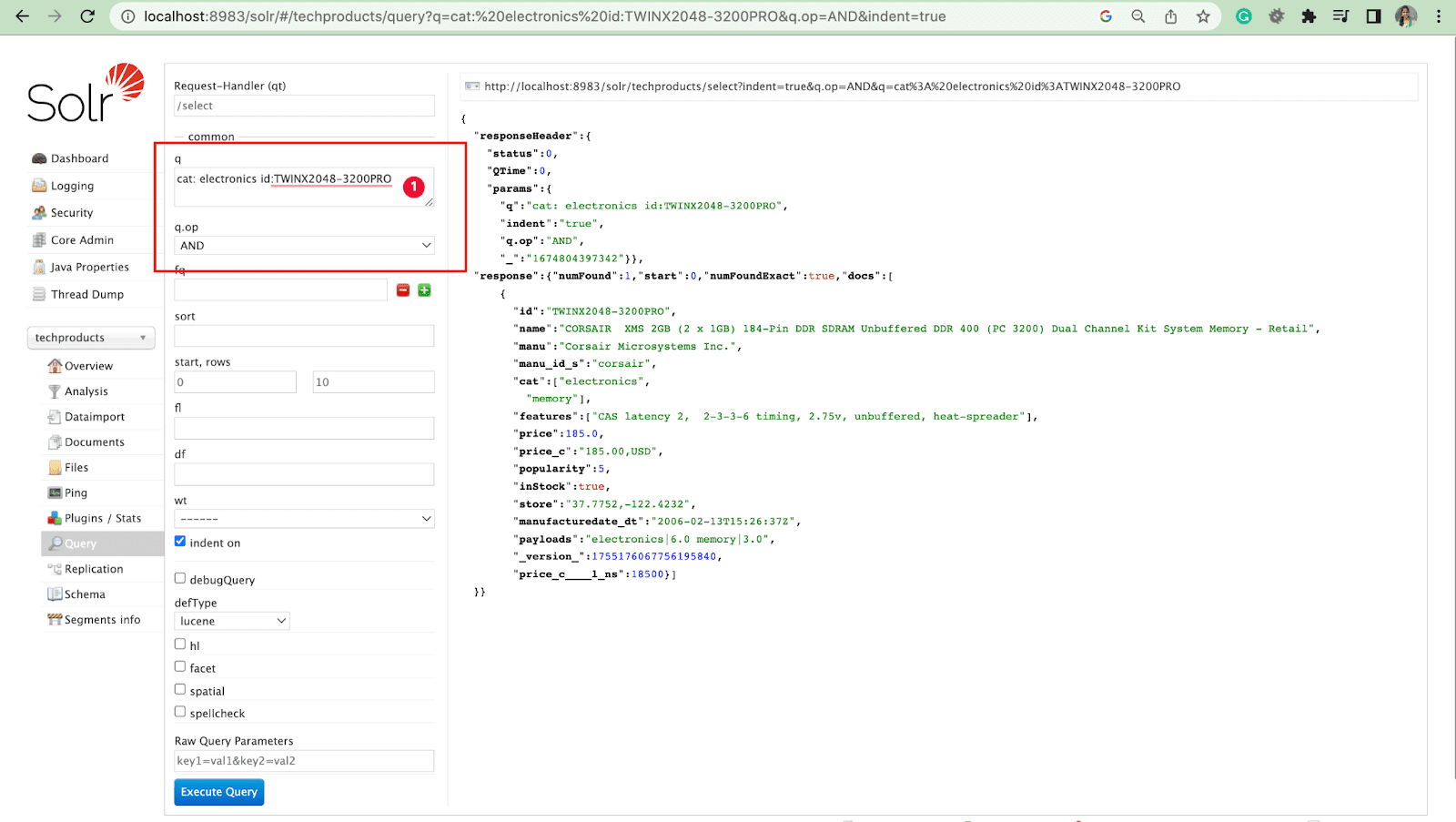
操作を伴うクエリ パラメータ
- 操作で複数のフィールドをクエリできます。
例: cat: electronic id:TWINX2048-3200PRO with q.op AND
[また]
cat: エレクトロニクス AND id:TWINX2048-3200PRO
[また]
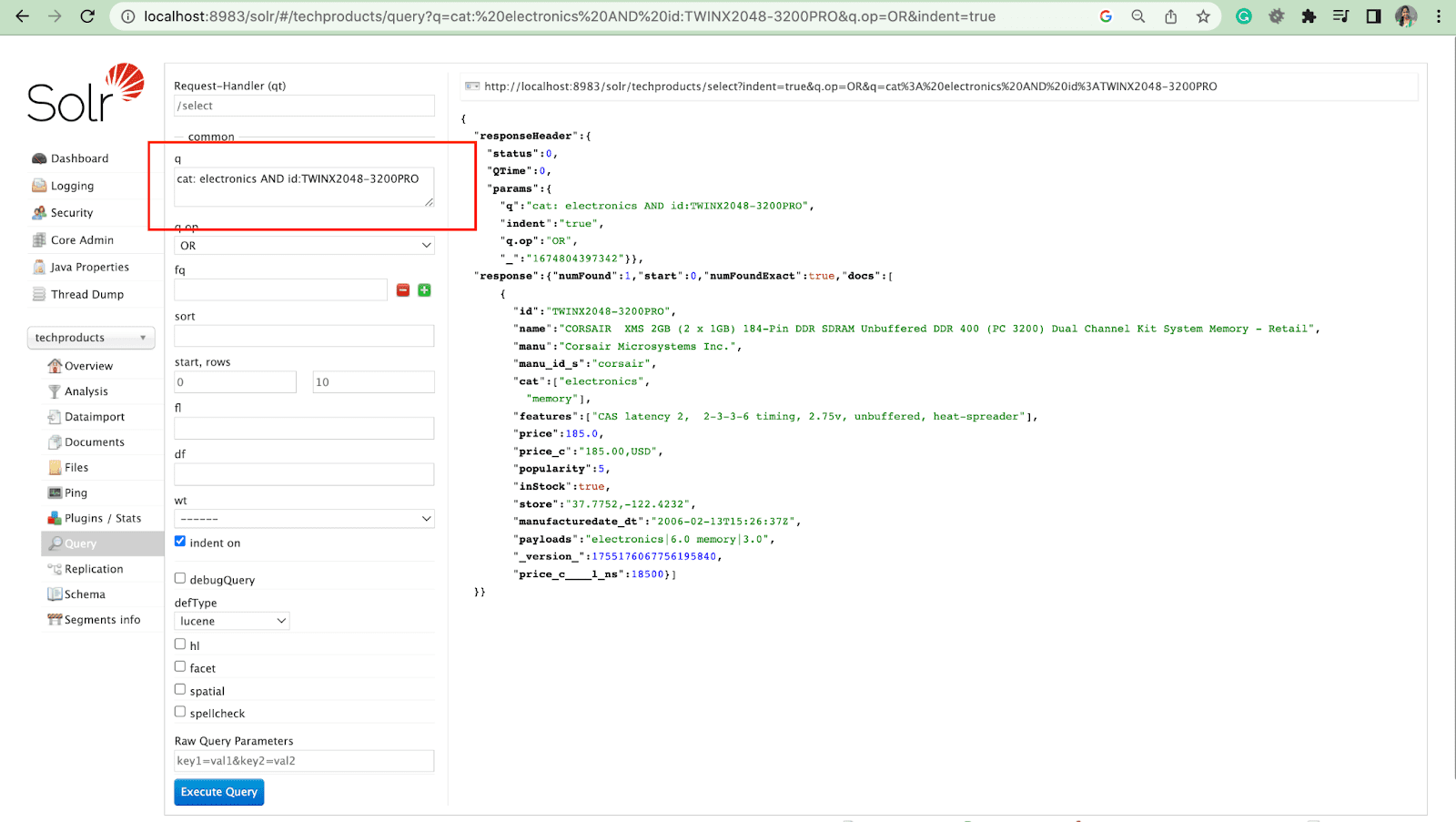
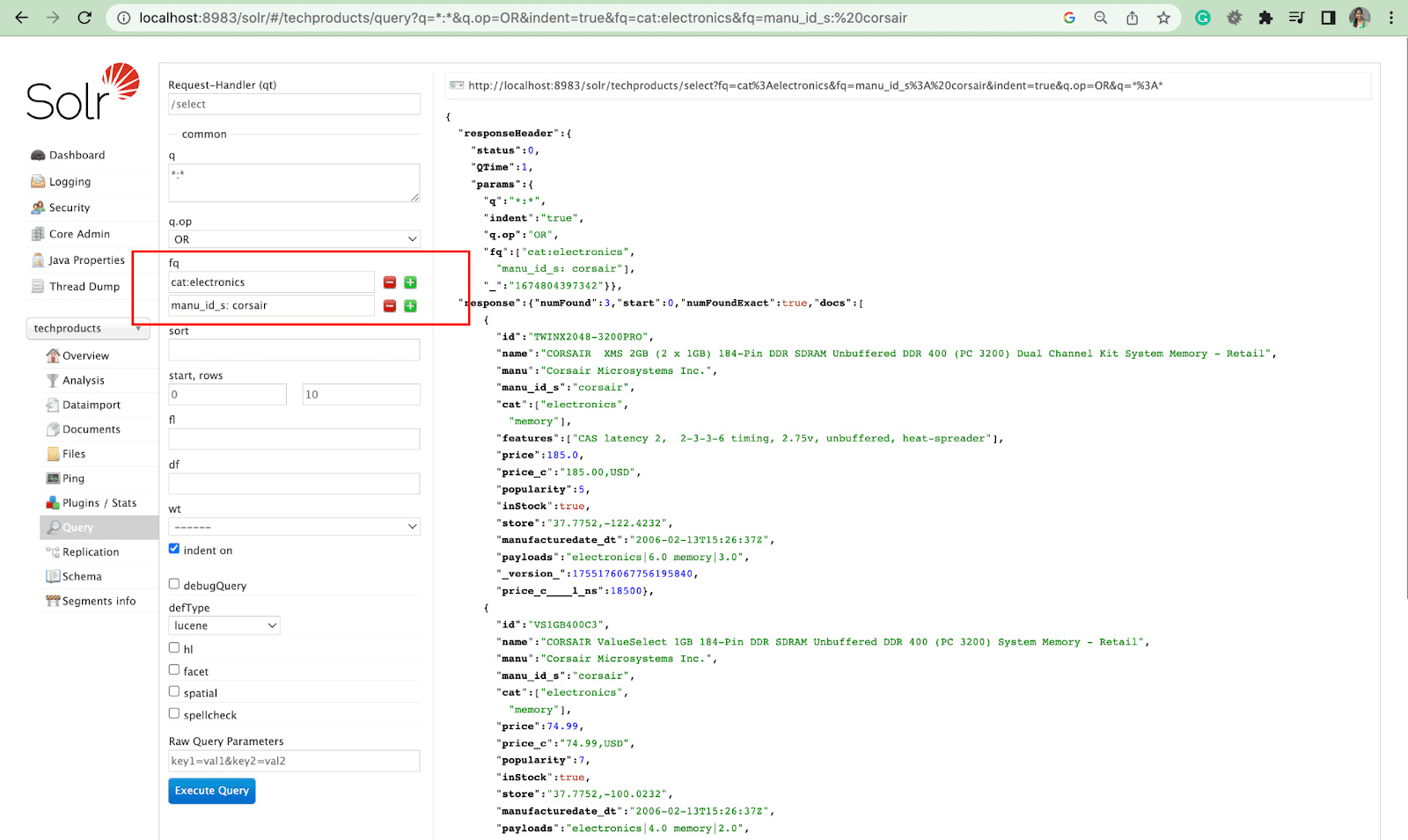
フィルタ クエリ
フィルタ クエリは、検索結果を絞り込むのに役立ちます。 fq パラメーターでクエリを指定して、スコアに影響を与えることなく、スーパーセットで返されるドキュメントを制限できます。
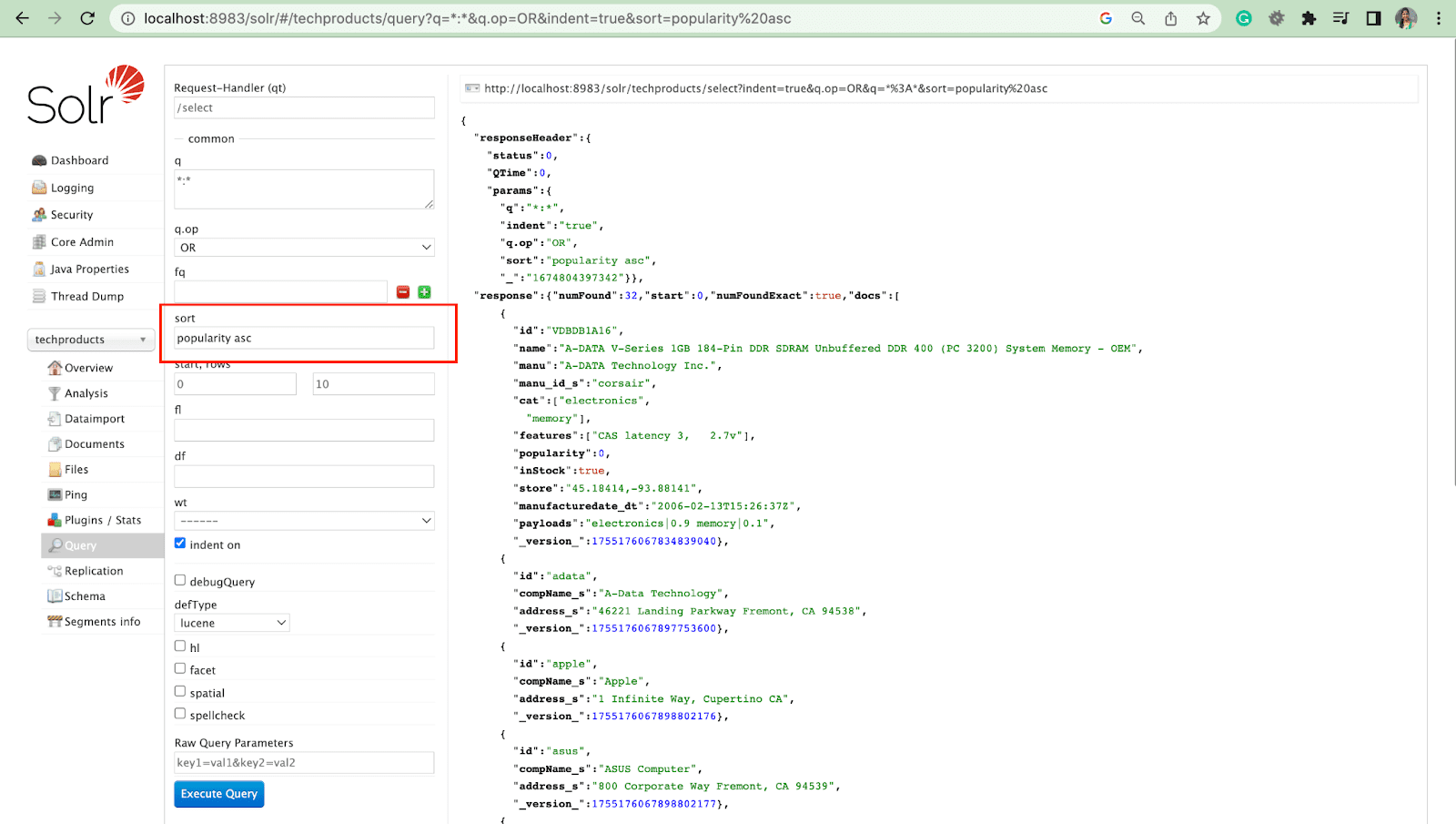
並べ替えパラメータ
sort パラメータは、検索結果を昇順 (asc) または降順 (desc) に並べ替えます。 内容に応じて、パラメーターは数字またはアルファベット順に使用できます。
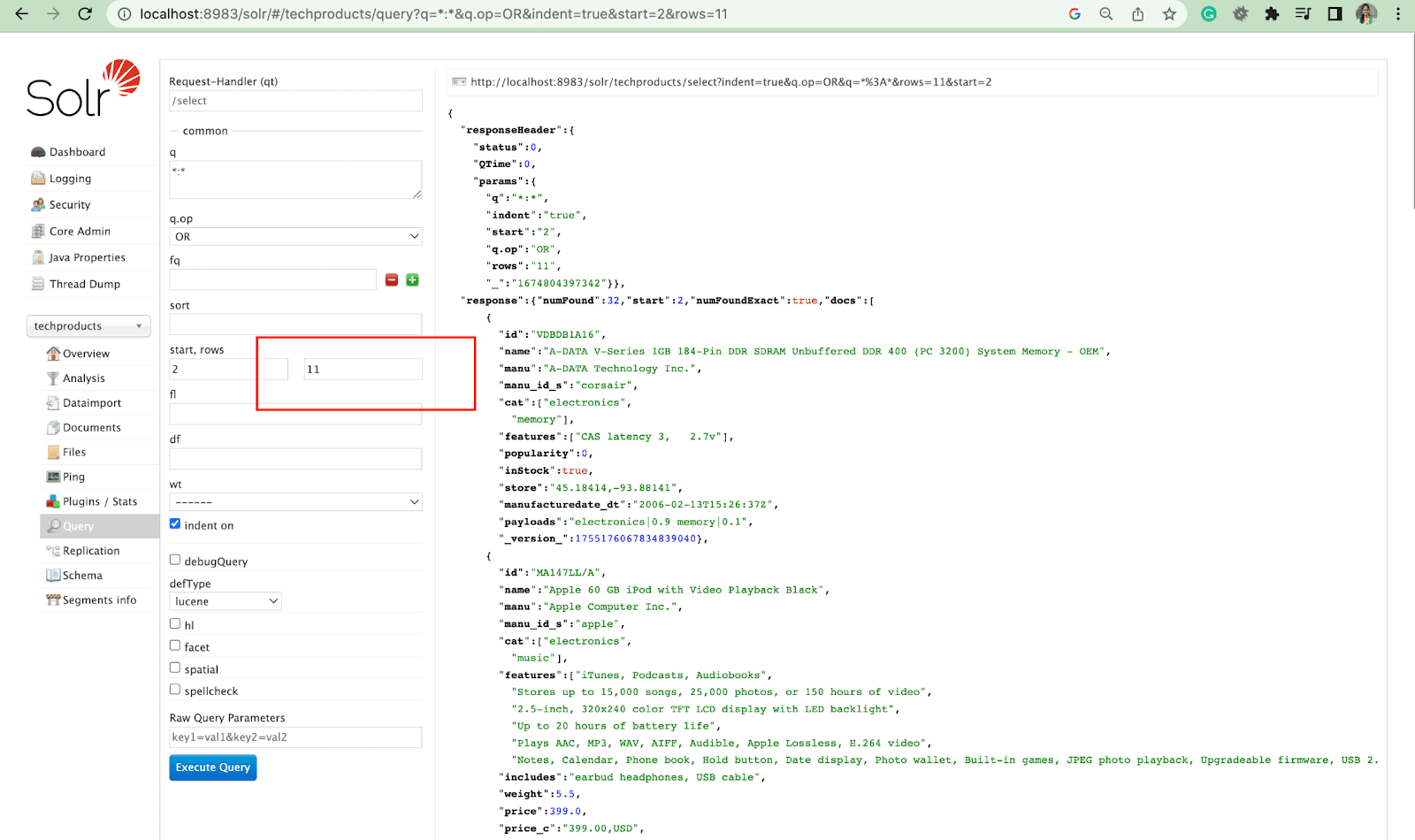
行パラメータ
行パラメーターを使用すると、クエリの結果をページ分割できます。
フィールド リスト パラメータ
fl パラメータは、クエリ応答に含まれる情報を、指定されたフィールドのリストに制限します。
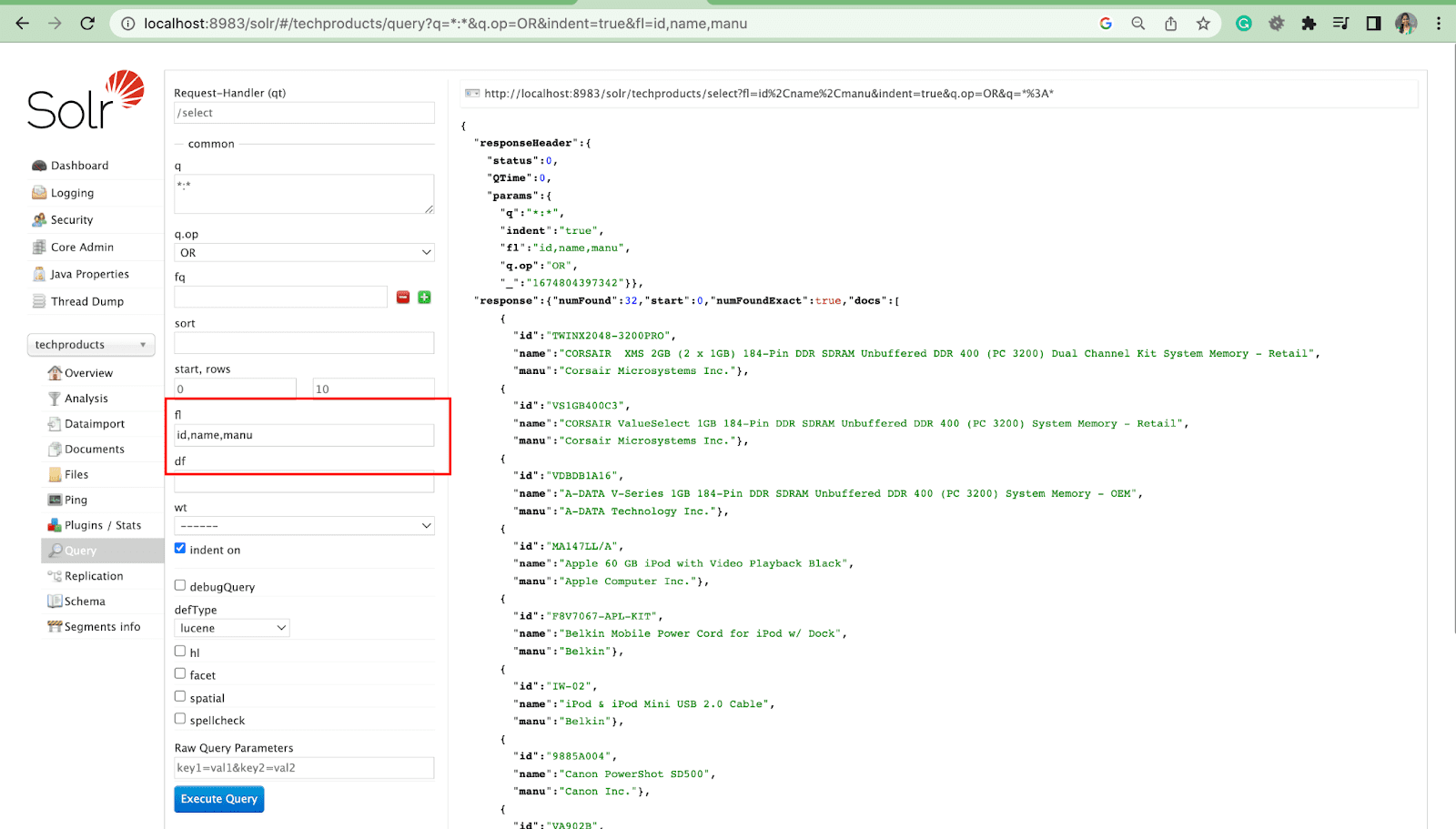
デフォルト フィールド パラメータ
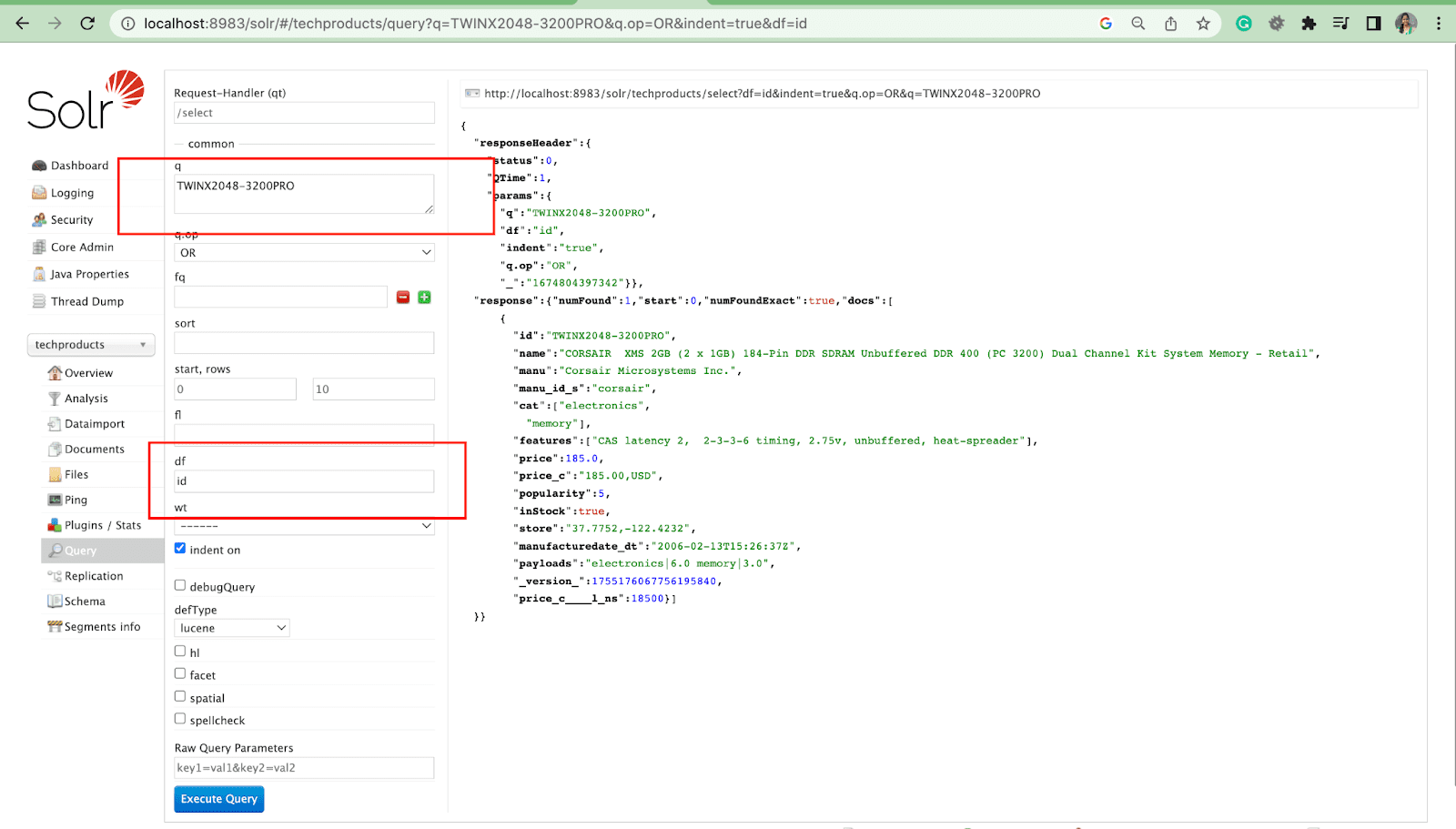
既定のフィールド パラメーターは、クエリ パラメーターの既定のフィールドです。
ハイライト パラメータ
Solr の強調表示機能を使用すると、クエリに一致するドキュメントのフラグメントを含めることができます。
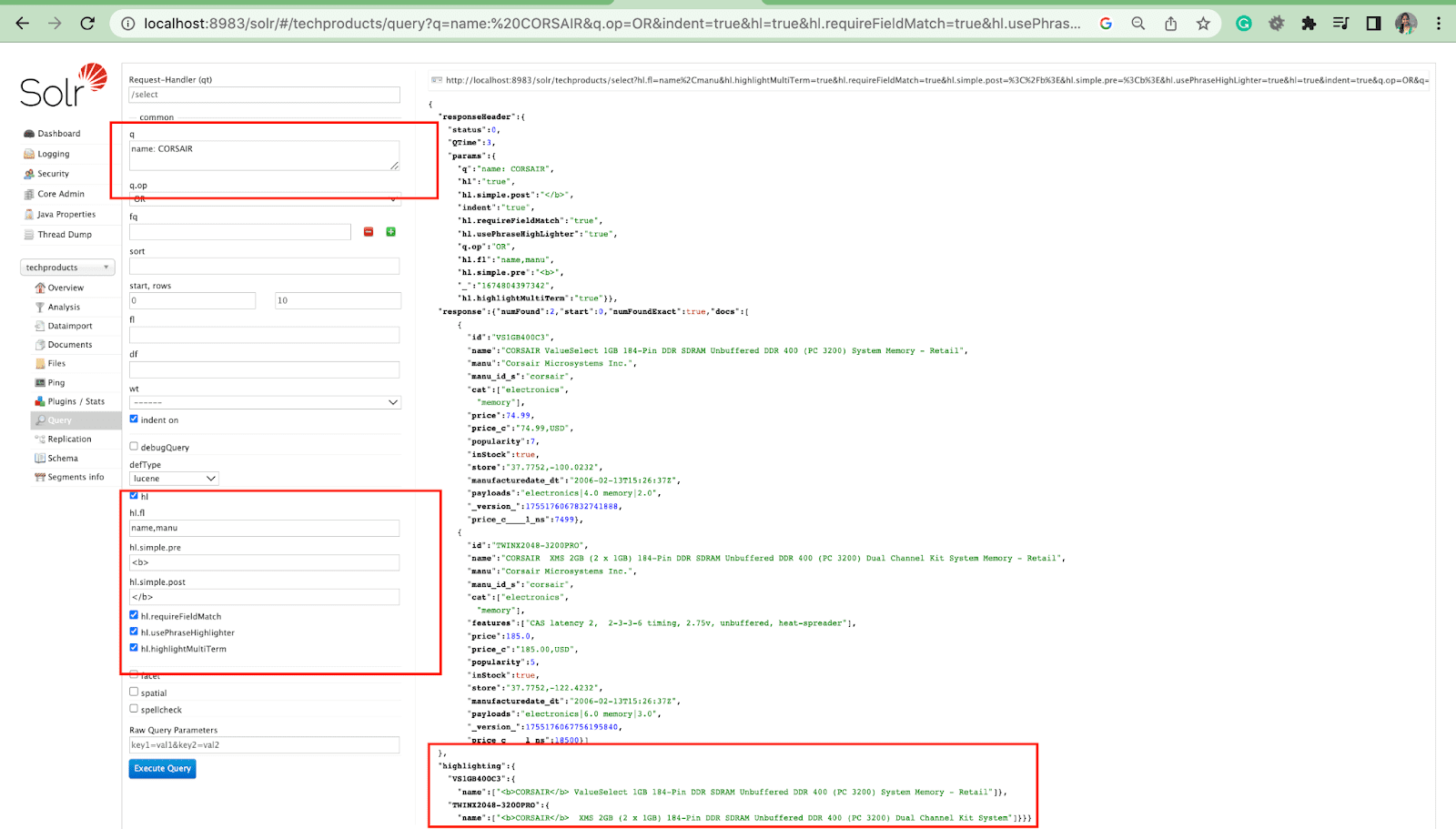
最も一般的なハイライト パラメータのいくつかは次のとおりです。
- Hl.fl - フィールドのリストを強調表示します。
- Hl.simple.pre - 強調表示された単語の前に使用する「タグ」を指定します。
- Hl.simple.post - ハイライトされた用語の後に使用する「タグ」を指定します。
- hl.highlightMultiTerm - trueに設定されている場合、Solr はワイルドカード クエリを強調表示します。 falseの場合、それらはまったく強調表示されません。
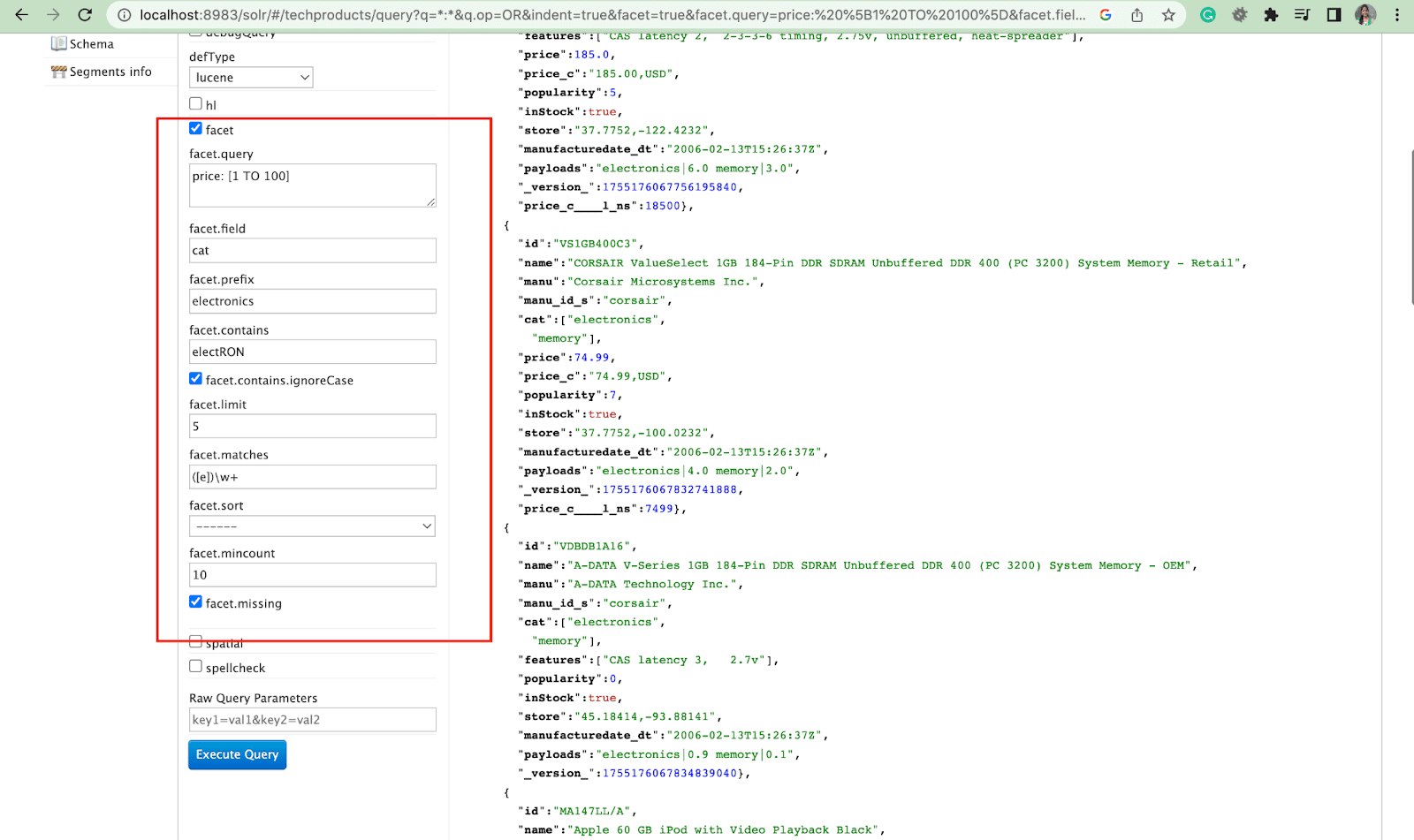
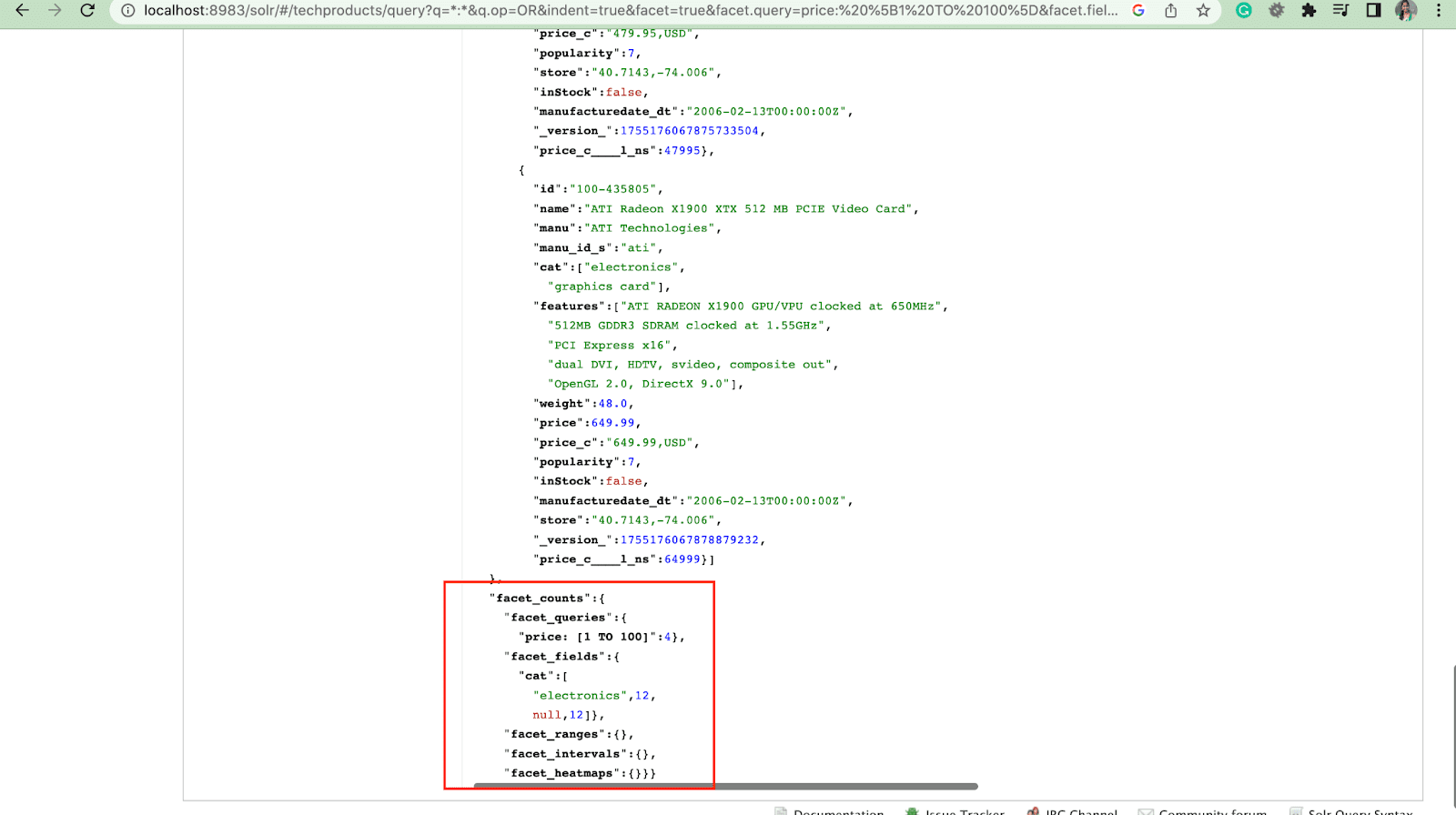
ファセット:
ファセットを使用すると、ユーザーは大量の検索結果セットを探索して絞り込むことができます。 チェックボックス、ドロップダウン、またはその他のコントロールとして UI に表示されます。 ファセットを制御するための 2 つの一般的なパラメーターは次のとおりです。
- ファセット パラメータ
ユーザーは facet パラメーターを使用して、検索インデックス内の 1 つ以上のフィールドの値に基づいてファセットを生成できます。 検索結果では、ファセット パラメーターを構成して、ファセットの生成方法と表示方法を制御できます。
2. Facet.query パラメータ
ユーザーが Solr クエリに facet.query パラメーターを含めると、Solr は、各クエリに一致するインデックス内のドキュメントの数に対応するファセット カウントのリストを生成します。 Facet.query は、単純なフィールド値を使用して簡単に表すことができない複雑な検索基準に基づいてファセットを生成する場合に役立ちます。
facet.field (ファセットの生成に使用する必要があるフィールドを指定するため) 、 facet.limit (各フィールドに表示するファセットの最大数) 、 facet.mincount (必要なドキュメントの最小数) など、他にもいくつかのファセット パラメーターがあります。応答に含まれるファセット) 、 facet.sort (ファセット値が表示される順序を指定します) 。
最終的な考え
Apache Solr は非常に用途の広い検索エンジンであり、要件に応じてカスタマイズできる多くの興味深い機能が付属しています。 Drupal は Apache Solr と非常にうまく連携します。 新しいプロジェクト用に強力な検索エンジンを構成する Drupal の専門家を探している場合は、ぜひさらに進めてください。