
Was ist Web Scraping und wie wird es gemacht?
Veröffentlicht: 2022-06-04Inhaltsverzeichnis
- Was ist Webscraping?
- Warum brauchen Sie Web Scraping?
- Wie funktioniert Web Scraping?
- Was sind einige Best Practices für Web Scraping?
- 5 der besten Web-Scraping-Tools
- Viel Spaß beim Scrapen im Web ... mit Vorsicht!
Wenn Sie Web Scraping derzeit nicht als Teil Ihres Arsenals verwenden, lassen Sie definitiv eine große Chance aus, sich einen Vorteil gegenüber Ihrer Konkurrenz zu verschaffen.
Wenn Sie wie die meisten Verkäufer sind, suchen Sie immer nach einem Vorteil gegenüber der Konkurrenz. Sie möchten neue Leads finden, Beziehungen zu bestehenden Kunden stärken und Ihre Branche als Ganzes besser verstehen.
Web Scraping kann Ihnen dabei helfen, all diese Dinge und mehr zu tun. Denken Sie an all die Zeiten, in denen Sie sich gewünscht haben, Sie könnten einfach eine Liste aller Unternehmen Ihrer Branche erhalten, die in einer bestimmten Stadt ansässig sind. Oder vielleicht wollten Sie eine Liste aller Kontakte in einem bestimmten Unternehmen erhalten.
Web Scraping kann Ihnen helfen, diese Informationen schnell und einfach zu erhalten. Aber was ist das und wie funktioniert es? In diesem Blogbeitrag beantworten wir diese Fragen und mehr. Lesen Sie also weiter, um alles zu erfahren, was Sie über dieses leistungsstarke Tool wissen müssen!

Was ist Webscraping?
Stellen Sie sich vor, Sie müssten sich den ganzen Tag so etwas anschauen. Spaß, oder …?
Stellen Sie sich nun vor, es gäbe eine Möglichkeit, all diese Daten in Sekundenschnelle zu sortieren, um einen organisierten Satz zu erhalten. Das ist im Grunde das Scraping von Daten.
Kurz gesagt, Web Scraping ist eine Möglichkeit, Daten von Websites zu extrahieren. Es wird normalerweise automatisch von Computern durchgeführt, kann aber auch manuell durchgeführt werden.
Es gibt verschiedene Möglichkeiten, dies zu tun, aber die Grundidee besteht darin, eine Webseite zu laden und dann den HTML-Code zu analysieren, um die gewünschten Daten zu finden. Sobald Sie die gewünschten Daten gefunden haben, können Sie sie zur späteren Verwendung in einer Datei oder Datenbank speichern.
Web Scraping kann für eine Vielzahl von Aufgaben nützlich sein, z. B. das Abrufen einer Liste aller Produktnamen und Preise aus einem Online-Shop oder das Extrahieren von Daten aus einem Webforum, um zu sehen, was die Leute zu einem bestimmten Thema sagen.
Ist Web Scraping kostenlos?
Die meisten Web-Scraping-Tools können kostenlos verwendet werden, obwohl es einige kostenpflichtige Optionen gibt. Die kostenpflichtigen Optionen bieten normalerweise mehr Funktionen und sind einfacher zu verwenden, aber die kostenlosen Optionen erledigen die Arbeit normalerweise gut.
Schneller Tipp
Ist Web Scraping legal?
Dies ist die am häufigsten gestellte Frage, und die Antwort lautet … es kommt darauf an. Im Allgemeinen ist es völlig in Ordnung, öffentliche Daten von Websites zu kratzen. Wenn Sie jedoch Daten kratzen, die privat sein sollen (wie die Kontaktinformationen einer Person), könnten Sie in rechtliche Schwierigkeiten geraten.
Dies ist eine häufig gestellte Frage, und die Antwort lautet … es kommt darauf an. Im Allgemeinen ist es völlig in Ordnung, öffentliche Daten von Websites zu kratzen. Wenn Sie jedoch Daten kratzen, die privat sein sollen (wie die Kontaktinformationen einer Person), könnten Sie in rechtliche Schwierigkeiten geraten.
Es ist immer eine gute Idee, die Nutzungsbedingungen für die Website, die Sie scrapen, zu überprüfen, um sicherzustellen, dass Sie keine Regeln verletzen.
Hier bei LaGrowthMachine haben wir unsere eigenen Scraping-Methoden entwickelt, die mehrere Datenquellen und verschiedene Technologien verwenden, was es uns ermöglicht, eine der besten Datenanreicherungsfunktionen auf dem Markt zu haben.
Wir stellen bis zu 28 verschiedene Datenelemente zu unseren Leads wieder her (immer nach einem RGPD-freundlichen Ansatz), was es Ihnen ermöglicht, nach sehr präzisen Variablen zu automatisieren und in Ihrem Ansatz sehr natürlich zu sein.
Obwohl die Praxis nicht neu ist, wird sie tendenziell weiter verbreitet und umfassender.
Es ist zu einem wesentlichen Vorteil für Wachstumsvermarkter und KMU geworden, die Effizienz und Reaktionsfähigkeit kombinieren möchten.
Okay, darum geht es also, aber wie nützt Web Scraping Ihrem Unternehmen tatsächlich?
Warum brauchen Sie Web Scraping?
Der offensichtlichste Vorteil von Web Scraping ist, dass Sie viel Zeit sparen können.
Stellen Sie sich vor, Sie müssten jedes Mal Daten von Websites manuell kopieren und einfügen, wenn Sie Marktforschung betreiben möchten. Es würde ewig dauern! Aber mit Web Scraping haben Sie alle Daten, die Sie brauchen, in nur wenigen Minuten.
Ein weiterer großer Vorteil ist, dass es Ihnen helfen kann, Daten zu erhalten, die auf andere Weise nur schwer oder gar nicht zu bekommen wären. Wenn Sie beispielsweise einen neuen Markt recherchieren möchten, kann Web Scraping Ihnen helfen, schnell und einfach eine Liste aller Unternehmen in diesem Markt zu erhalten.
Darüber hinaus kann Web Scraping für eine Vielzahl von Aufgaben verwendet werden, einige der häufigsten Anwendungen sind:
- Lead-Generierung: Das Scraping von Daten von Websites kann eine großartige Möglichkeit sein, neue Leads zu finden. Sie könnten beispielsweise Daten aus einem Unternehmensverzeichnis durchsuchen, um alle Unternehmen Ihrer Branche zu finden, die sich in einer bestimmten Stadt befinden.
- Marktforschung: Web Scraping kann verwendet werden, um Daten über eine bestimmte Branche oder einen bestimmten Markt zu sammeln. Diese Daten können dann analysiert werden, um Ihnen zu helfen, den Markt als Ganzes besser zu verstehen.
- Wettbewerbsanalyse: Die Konkurrenz im Auge zu behalten, ist in jedem Unternehmen wichtig. Indem Sie Daten von ihren Websites abkratzen, können Sie ihre Produkte, Preise und Marketingstrategien besser verstehen.
Wenn Sie noch weiter gehen, können Sie mit den gesammelten Daten Multi-Channel-Kampagnen in LaGrowthMachine einrichten.
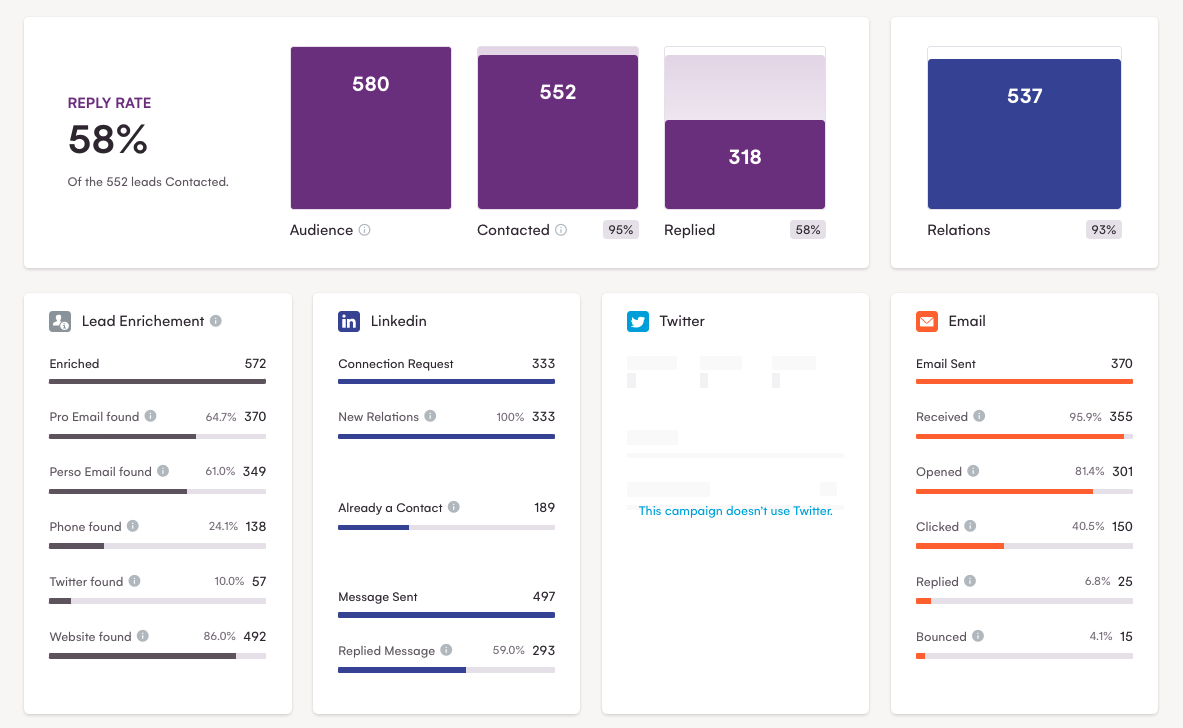
Wie Sie sehen können, ist diese Methode mit einer Rücklaufquote von fast 60 % sehr erfolgreich!
Nachdem wir Ihnen nun das Web Scraping vorgestellt und Ihnen einige seiner Vorteile gezeigt haben, werfen wir einen Blick auf die Grundlagen seiner Funktionsweise.
Wie funktioniert Web Scraping?
Web Scraping wird normalerweise automatisch von Computern durchgeführt, kann aber auch manuell durchgeführt werden.
Es gibt verschiedene Möglichkeiten, dies zu tun, aber die Grundidee besteht darin, eine Webseite zu laden und dann den HTML-Code zu analysieren, um die gewünschten Daten zu finden. Sobald Sie die gewünschten Daten gefunden haben, können Sie sie zur späteren Verwendung in eine Datei oder Datenbank extrahieren.
Angenommen, Sie möchten Daten aus einem Online-Shop abrufen, um eine Liste aller Produktnamen und Preise zu erhalten.
Zuerst müssten Sie die Webseite finden und laden, die Sie schaben möchten.
Dann müssten Sie einen Code schreiben, der den HTML-Code der Webseite analysiert und die Daten extrahiert, an denen Sie interessiert sind.
Zuletzt müssten Sie die Daten in einer Datei oder Datenbank speichern.
Web Scraping kann in einer Vielzahl von Programmiersprachen durchgeführt werden, aber die beliebtesten sind Python, Java und PHP.
Wenn Sie gerade erst mit Web Scraping beginnen, empfehlen wir die Verwendung eines Tools wie ParseHub oder Scrapy. Diese Tools machen es einfach, Daten von Websites zu kratzen, ohne Code schreiben zu müssen.
Was sind einige Best Practices für Web Scraping?

Nachdem Sie nun die Grundlagen des Web Scraping kennen, werfen wir einen Blick auf einige Best Practices, die Sie beachten sollten.
Überprüfen Sie die Nutzungsbedingungen
Wie bereits erwähnt, müssen Sie die Nutzungsbedingungen für die Website, die Sie scrapen, überprüfen. Dadurch wird sichergestellt, dass Sie gegen keine Regeln verstoßen und potenzielle Probleme – rechtliche oder andere – später vermeiden. Es ist auch eine gute Idee, die Erlaubnis des Websitebesitzers einzuholen, bevor Sie seine Website scrapen, da einige Webmaster möglicherweise nicht allzu glücklich darüber sind.
Verwenden Sie die richtigen Werkzeuge
Es gibt eine Vielzahl verschiedener Web-Scraping-Tools, daher ist es wichtig, das richtige für Ihre Bedürfnisse auszuwählen.
Apropos, LaGrowthMachine ist einer von ihnen!
Wir werden später in diesem Handbuch eine Liste der besten Web-Scraping-Tools durchgehen, aber für diesen Punkt erwähnen wir nur einige der beliebtesten:
- Scrapy: Scrapy ist ein in Python geschriebenes Web-Scraping-Framework. Es ist eines der beliebtesten verfügbaren Tools und wird von großen Namen wie Google, Yahoo und Facebook verwendet.
- ParseHub: ParseHub ist ein Web-Scraper, der eine Vielzahl von Sprachen und Webplattformen unterstützt.
- Octoparse: Octoparse ist ein weiterer Web Scraper, der sowohl statische als auch dynamische Webseiten unterstützt.
Server nicht überlasten
Wenn Sie Daten von Websites kratzen, ist es wichtig, deren Server nicht mit zu vielen Anfragen zu überlasten. Dies kann dazu führen, dass Ihre IP-Adresse von der Website gesperrt wird. Um dies zu vermeiden, stellen Sie sicher, dass Sie Ihre Anfragen verteilen und nicht zu viele auf einmal stellen.

Gehen Sie elegant mit Fehlern um
Es ist unvermeidlich, dass Sie irgendwann auf Fehler stoßen. Unabhängig davon, ob es sich um eine Website handelt, die nicht verfügbar ist, oder um Daten, die nicht das erwartete Format aufweisen, ist es wichtig, geduldig und behutsam mit diesen Fehlern umzugehen. Sie wollen nicht riskieren, etwas kaputt zu machen, weil Sie es zu eilig haben.
Überprüfen Sie Ihre Daten regelmäßig
Es ist wichtig, dass Sie Ihre Daten regelmäßig überprüfen. Manchmal ändern sich Webseiten und die Daten, die Sie extrahieren, sind möglicherweise nicht mehr genau. Durch die regelmäßige Überprüfung Ihrer Daten können Sie sicherstellen, dass Sie immer genaue Informationen erhalten.
Kratzen Sie verantwortungsbewusst
Es ist wichtig, respektvoll mit den Websites umzugehen, die Sie scrapen. Das bedeutet, nicht zu viele Daten zu scrapen, nicht zu oft zu scrapen und sensible Daten nicht zu scrapen. Stellen Sie außerdem sicher, dass Ihr Scraper auf dem neuesten Stand ist, damit er nicht versehentlich eine Website beschädigt, die Sie scrapen.
Wissen, wann man aufhören muss
Es wird Zeiten geben, in denen Sie nicht die gewünschten Daten von einer Website abrufen können. Wenn dies passiert, ist es wichtig zu wissen, wann man aufhören und weitermachen muss. Verschwende deine Zeit nicht damit, deinen Web Scraper zum Laufen zu zwingen – es gibt andere Websites mit den Daten, die du benötigst.
Dies sind nur einige der Best Practices, die Sie bei der Datenextraktion beachten sollten. Die Befolgung dieser Richtlinien trägt dazu bei, dass Sie eine positive Erfahrung machen und mögliche Probleme vermeiden.
5 der besten Web-Scraping-Tools

Wie bereits erwähnt, gibt es eine Vielzahl von Web Scrapern, die von komplexen Frameworks bis hin zu einfachen Tools reichen. In diesem Abschnitt gehen wir auf einige der beliebtesten Scraping-Tools ein.
Nun … wir haben bereits die grundlegenden Tools wie Scrapy und ParseHub erwähnt, also gehen wir nur schnell auf ein paar der anderen ein.
Python
Python ist eine der offensichtlichsten Möglichkeiten für Ihre Web-Scraping-Anforderungen. Es ist eine vielseitige Skriptsprache, die für gut … Data Scraping sowie für eine Vielzahl anderer Aufgaben verwendet werden kann.
Der Hauptvorteil der Verwendung der Web-Scraping-Software von Python besteht darin, dass sie relativ einfach zu erlernen und zu verwenden ist.
Darüber hinaus verfügt Python über eine große Auswahl an Bibliotheken und Modulen, die für die Extraktion von Webdaten verwendet werden können, was es zu einem bemerkenswert leistungsfähigen Werkzeug macht.
Ein Nachteil ist, dass Python-Web-Scraper langsam sein können, insbesondere wenn sie versuchen, große Datenmengen zu scrapen.
Darüber hinaus können einige Websites den Zugriff blockieren, was bedeutet, dass das Web-Scraping mit Python oft zeitaufwändiger und schwieriger sein kann als die Verwendung anderer Web-Scraping-Tools.
Insgesamt hat die Webdatenextraktion mit Python sowohl Vor- als auch Nachteile, bleibt aber eine beliebte Wahl für viele Leute, die Daten aus dem Web kratzen möchten.
Import.io

Dies ist ein Tool zum Extrahieren von Webdaten, mit dem Sie Daten von Websites entfernen können, ohne Code schreiben zu müssen. Es ist eines der benutzerfreundlichsten verfügbaren Web-Scraping-Tools und ein Bonus: Es ist großartig für Anfänger!
Es enthält tolle Funktionen wie:
- Eine benutzerfreundliche Point-and-Click-Oberfläche
- Die Möglichkeit, Daten hinter einem Login zu kratzen
- Automatische IP-Rotation, um eine Sperrung zu vermeiden
Was import.io so großartig macht, ist, dass es Daten von mehreren Seiten einer Website abkratzen kann. Dies ist nützlich, wenn Sie Daten von einer großen Website mit vielen Seiten kratzen möchten. Dies bedeutet jedoch auch, dass es langsam sein kann, wenn Daten von Websites mit einer Vielzahl von Seiten geschabt werden.
Ein weiterer Vorteil von import.io besteht darin, dass es Daten von Websites „kratzen“ kann, die „schwierig“ zu schaben sind: Das heißt, es kann einige der Schutzmechanismen umgehen, die Websites verwenden, um Scraping zu verhindern. Sie laufen jedoch Gefahr, dass das Tool kaputt geht, wenn Websites ihre Schutzmechanismen ändern.
Insgesamt ist import.io ein großartiges Tool zum schnellen Sammeln von Daten aus dem Internet, aber es ist wichtig, sich seiner Einschränkungen bewusst zu sein.
Mozenda

Mozenda ist ein weiteres Web-Scraping-Tool, das keine Programmierung erfordert. Es enthält Funktionen wie Webseiten-Rendering, Webseiten-Crawling und Datenextraktion.
Es ist eine großartige Lösung, weil es einfach zu bedienen ist und so konfiguriert werden kann, dass es Daten von fast jeder Website kratzt.
Einer der Hauptvorteile der Verwendung von Mozenda ist, dass es sehr schnell und effizient ist. Es kann große Datenmengen sehr schnell und einfach verarbeiten.
Außerdem ist es sehr benutzerfreundlich. Die Benutzeroberfläche ist intuitiv und einfach zu bedienen. Es gibt auch eine große Auswahl an Online-Ressourcen, die Ihnen beim Einstieg in das Web Scraping mit diesem Tool helfen.
Einer der Hauptnachteile ist jedoch, dass es ziemlich teuer ist. Wenn Sie Web Scraping nur für den persönlichen Gebrauch planen, ist Mozenda möglicherweise nicht die beste Option für Sie.
Es funktioniert auch nicht immer perfekt. Manchmal können Websites ihre Struktur oder ihr Design ändern, was zu Problemen mit Ihrem Web Scraping führen kann.
Apify

Als Web-Scraping-Plattform ermöglicht Ihnen Apify, Websites in strukturierte Daten umzuwandeln. Es bietet eine breite Palette von Funktionen, einschließlich der Möglichkeit, dynamische Webseiten zu scrapen, APIs zu erstellen und ganze Websites zu crawlen.
Obwohl Apify ein leistungsstarkes Tool ist, hat es einige Einschränkungen:
Erstens ist die Nutzung nicht kostenlos. Wenn Sie also knapp bei Kasse sind, ist es möglicherweise nicht die beste Option für Sie. Es kann auch schwierig sein, es einzurichten und zu verwenden, insbesondere für Benutzer, die mit Web Scraping nicht vertraut sind.
Wie dem auch sei, dies ist einer der am besten skalierbaren Web Scraper, die Sie verwenden können. Die Plattform kann groß angelegte Scraps verarbeiten und ist daher ideal für Unternehmen, die Daten in großem Umfang sammeln müssen.
Nichtsdestotrotz hat diese Skalierbarkeit einen Nachteil; Da Apify solche groß angelegten Scraps verarbeiten kann, kann es anfälliger für Fehler sein und einige Daten können während des Scraping-Prozesses verloren gehen.
Insgesamt bleibt Apify aufgrund seiner Flexibilität und Funktionsvielfalt eine beliebte Web-Scraping-Plattform. Wenn Sie nach einer einfach zu bedienenden Web-Scraping-Plattform mit einer Vielzahl von Funktionen suchen, ist Apify möglicherweise eine gute Option für Sie.
DiffBot

Diffbot ist eine Web-Scraping-Software, die künstliche Intelligenz verwendet, um Daten von Webseiten zu extrahieren. Es bietet eine breite Palette von Funktionen, darunter die Möglichkeit, Web Scraping in großem Umfang durchzuführen, Websites zu crawlen und Daten aus JavaScript-Webseiten zu extrahieren.
Der Hauptvorteil der Verwendung von Diffbot besteht darin, dass es sehr präzise ist. Das Tool ist in der Lage, bestimmte Daten mit einem hohen Maß an Genauigkeit zu extrahieren, was bedeutet, dass Sie bei der Verwendung des Tools weniger wahrscheinlich auf Fehler stoßen. Es hat auch die Fähigkeit, Daten von mehreren Seiten zu kratzen und AJAX-Anfragen zu verarbeiten, was immer ein Plus ist.
Außerdem ist es sehr benutzerfreundlich. Die Benutzeroberfläche ist intuitiv und einfach zu bedienen, und es steht eine große Auswahl an Online-Ressourcen zur Verfügung, die Ihnen beim Einstieg in das Web Scraping mit Diffbot helfen.
Einer der größten Nachteile von Diffbot ist jedoch, dass es ziemlich teuer ist und nicht in der Lage ist, Daten von Websites zu kratzen, die JavaScript zum Laden von Inhalten verwenden.
Darüber hinaus muss es auch eine gut strukturierte Website haben, damit es sein volles Potenzial entfalten kann. Wenn nicht, kann der Daten-Scraping-Prozess ziemlich langsam sein.
Viel Spaß beim Scrapen im Web ... mit Vorsicht!
Web Scraping kann eine großartige Möglichkeit sein, Daten aus dem Internet zu sammeln. Es ist schnell, effizient und relativ einfach zu bewerkstelligen. Es gibt jedoch einige Dinge, die Sie beachten müssen, bevor Sie mit dem Web Scraping beginnen.
Erstens kann Web Scraping in einigen Fällen illegal sein. Wenn Sie Web Scraping für kommerzielle Zwecke planen, müssen Sie sicherstellen, dass Sie dazu berechtigt sind.
Zweitens kann Web Scraping eine Herausforderung sein. Während es viele Web-Scraping-Tools gibt, die recht benutzerfreundlich sind und keine Programmierung erfordern, können einige Websites schwieriger zu schaben sein als andere.
Schließlich kann Web Scraping zeitaufwändig sein. Wenn Sie das Web Scraping für eine große Website planen, kann es einige Zeit dauern, bis Sie alle benötigten Daten erhalten.
Nichtsdestotrotz kann Web Scraping eine großartige Möglichkeit sein, Daten schnell und effizient zu sammeln. Stellen Sie einfach sicher, dass Sie sich der damit verbundenen Risiken bewusst sind, bevor Sie mit dem Web Scraping beginnen.
Fröhliches Schaben!