
Verpassen Sie nicht die Neuigkeiten aus der Social-Media-Branche von morgen
Veröffentlicht: 2023-04-01Wie von Twitter-Chef Elon Musk Anfang dieses Monats versprochen, hat Twitter heute seinen Empfehlungsalgorithmus-Code auf GitHub für alle sichtbar veröffentlicht, während es auch einen neuen Überblick über die Funktionsweise seines Tweet-Empfehlungsalgorithmus veröffentlicht hat, der neue Einblicke in die Reihenfolge bietet in denen Tweets angezeigt werden.
Wie von Twitter erklärt:
„ Auf GitHub finden Sie zwei neue Repositories ( main repo , ml repo ), die den Quellcode für viele Teile von Twitter enthalten, einschließlich unseres Empfehlungsalgorithmus, der die Tweets steuert, die Sie auf der For You-Timeline sehen. Für diese Veröffentlichung haben wir uns das höchstmögliche Maß an Transparenz zum Ziel gesetzt und gleichzeitig jeden Code ausgeschlossen, der die Sicherheit und Privatsphäre der Benutzer oder die Fähigkeit, unsere Plattform vor schlechten Akteuren zu schützen, beeinträchtigen würde, einschließlich der Untergrabung unserer Bemühungen zur Bekämpfung der sexuellen Ausbeutung und Manipulation von Kindern.“
Es ist auch wichtig anzumerken, dass Twitter die Gewichtungsinformationen nicht mit jedem Element verknüpft hat – dh wie viel Gewicht jeder Faktor bei der Steuerung der endgültigen Ausgabeergebnisse erhält.
Es ist also nicht jedes Detail, aber es bietet einen allgemeinen Einblick in die Funktionsweise der Algorithmen von Twitter, während Twitter auch eine eher laienhafte Erklärung des Systems liefert, um den Leuten zu helfen, zu verstehen, wie es entscheidet, was Sie in Ihrer Zeitleiste sehen werden wenn Sie die App öffnen.
Laut Twitter:
„ Die Grundlage der Empfehlungen von Twitter ist eine Reihe von Kernmodellen und -funktionen, die latente Informationen aus Tweet-, Benutzer- und Interaktionsdaten extrahieren. Diese Modelle zielen darauf ab, wichtige Fragen über das Twitter-Netzwerk zu beantworten, wie z. B. „Wie hoch ist die Wahrscheinlichkeit, dass Sie in Zukunft mit einem anderen Benutzer interagieren werden?“ oder „Was sind die Communitys auf Twitter und welche Tweets sind in ihnen angesagt?“Die genaue Beantwortung dieser Fragen ermöglicht es Twitter, relevantere Empfehlungen zu liefern.”
Das letzte Element ist wichtig und stimmt mit dem überein, was Ryan Broderick von Garbage Day in seinen Experimenten beim Testen herausgefunden hatte, was jetzt per Tweet an Bedeutung gewinnt.
Wie von Broderick zusammengefasst:
„Twitter verwendet unsichtbare Subreddits über Topics, um Tweets algorithmisch zu organisieren. Da die For You-Seite nicht mehr chronologisch ist, können virale Tweets nicht mehr so aktuell sein wie früher. Sie müssen immergrün sein. Es hilft, wenn sie etwas kommentieren, das bereits viral geht. Und es hilft wirklich, wenn Sie einen Thread posten, sich selbst antworten oder in den Antworten eine Art Diskussion erzeugen. Video scheint jetzt auch eine größere Betonung zu sein. ”
Es stellte sich heraus, dass Ryan Recht hatte – Twitter versucht nun, mehr Tweets im „For You“-Feed basierend auf thematischem Engagement zu bewerben, das Twitter auf Kontoebene definiert, indem es bestimmte Konten in Themenkategorien filtert und diese dann als Leitfaden für die Kategorisierung verwendet das wahrscheinliche Thema jedes ihrer Tweets.
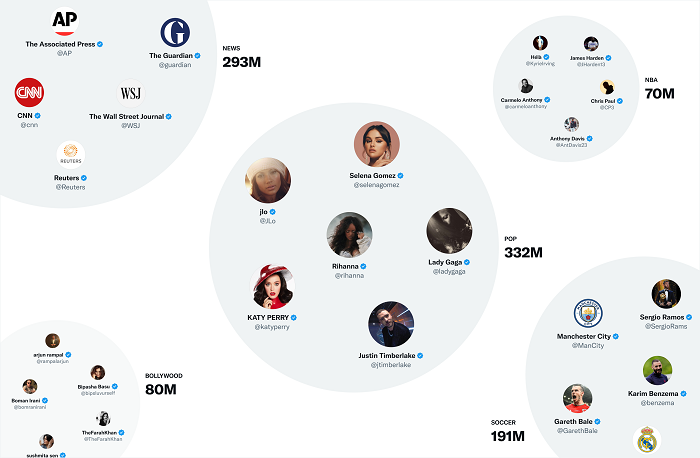
Laut Twitter:
„ Einer der nützlichsten Einbettungsbereiche von Twitter sind SimClusters . SimClusters entdecken Gemeinschaften, die von einem Cluster einflussreicher Benutzer verankert sind, indem sie einen benutzerdefinierten Matrixfaktorisierungsalgorithmus verwenden . Es gibt 145.000 Communities, die alle drei Wochen aktualisiert werden. Die Größe der Communities reicht von einigen tausend Benutzern für einzelne Freundesgruppen bis hin zu Hunderten von Millionen von Benutzern für Nachrichten oder Popkultur. Je mehr Benutzer einer Community einen Tweet mögen, desto mehr wird dieser Tweet dieser Community zugeordnet.“

Das obige Bild zeigt einige der größten Twitter-„Gemeinschaften“ oder thematische Sammlungen, die auf der algorithmischen Filterung von Twitter basieren.
Laut Twitter ist dieser Ansatz zu einem Schlüsselfaktor bei der Entscheidung geworden, welche „Out-of-Network“-Tweets in Ihren „For You“-Feed eingefügt werden sollen oder welche Tweets Ihnen von Konten angezeigt werden, denen Sie nicht folgen. Und da immer mehr dieser Empfehlungen in Benutzer-Feeds eingefügt werden, ist dies zu einem größeren Treiber für die Tweet-Präsenz geworden – obwohl sich das bald wieder ändern wird, wenn Twitter „Für dich“-Empfehlungen weiter auf Tweets von zahlenden Abonnentenkonten beschränkt.
Wie sich das auf die Twitter-Erfahrung auswirkt, ist zum jetzigen Zeitpunkt unklar, aber es wird zumindest den „For You“-Feed grundlegend verändern, indem es den Pool an Quell-Tweets einschränkt, aus dem Twitter ziehen kann.
Und wenn insbesondere Prominente nicht zahlen oder infolgedessen aufhören zu twittern, könnten diese Auswirkungen erheblich sein.
Dies ist die bedeutendste Enthüllung der algorithmischen Übersicht von Twitter, obwohl die Dokumentation mehrere andere interessante Anmerkungen und Punkte enthält:
- Für jede Benutzersitzung extrahiert Twitter etwa 1500 Tweets, von denen es glaubt, dass sie für jede Person möglicherweise von Interesse sind, bevor sie in den „For You“-Feed eingeordnet werden
- Die For You-Timeline besteht derzeit im Durchschnitt zu 50 % aus In-Network-Tweets (Personen, denen Sie folgen) und zu 50 % aus Out-of-Network-Tweets
- Twitter sagt auch die Wahrscheinlichkeit einer Interaktion zwischen zwei Benutzern voraus. „Je höher der Real Graph Score zwischen dir und dem Autor des Tweets ist, desto mehr Tweets nehmen wir auf.“
- Ein weiterer Faktor sind die Tweets, mit denen Personen, denen Sie folgen, interagieren – was keine Offenbarung ist, sondern nur eine Anmerkung
- Das Tweet-Ranking wird über ein „ungefähr 48 Millionen Parameter umfassendes neuronales Netzwerk durchgeführt, das kontinuierlich auf Tweet-Interaktionen trainiert wird, um es für positives Engagement zu optimieren (z. B. Likes, Retweets und Antworten)“. Es gibt jedoch keinen Hinweis darauf, wie Twitter in diesem Zusammenhang zwischen positivem und negativem Engagement bestimmt
Das liefert einen interessanten Kontext dafür, wie Twitter Tweets einordnet und die Präsenz im Hauptfeed „For You“ maximiert – obwohl sich dies am 15. April ändern wird, wenn Twitter darauf umstellt, nur Tweets von zahlenden Benutzern anzuzeigen seine „Für Sie“-Empfehlungen.
Was in gewisser Weise viele dieser Erkenntnisse überflüssig macht – obwohl ich denke, wenn die Arbeitstheorie besagt, dass die meisten Benutzer letztendlich bezahlen werden, dann könnte dies noch einige Zeit indikativ bleiben.
Außer, sie werden es nicht tun.
Weniger als 1 % der Twitter-Nutzer zahlen derzeit für Twitter Blue, und obwohl die Entscheidung, „alte“ blaue Häkchen zu entfernen und den „For You“-Ranking-Prozess rückgängig zu machen, für zusätzliche Akzeptanz sorgen wird, scheint es unwahrscheinlich, dass Twitter Blue wird eine wichtige Überlegung für die überwiegende Mehrheit der Twitter-Nutzer.
Ich denke, das andere Element, das in dieser Hinsicht berücksichtigt werden muss, ist, dass die überwiegende Mehrheit der Tweets von sehr wenigen Benutzern stammt, wobei die meisten Twitter-Profile selten selbst twittern. Vielleicht braucht Twitter also nur eine kleinere Gruppe von Benutzern, um sich für Blue anzumelden, um es zu einem bedeutenderen Element im Tweet-Ranking zu machen. Es scheint jedoch immer noch unwahrscheinlich, bessere Ergebnisse bei der Hervorhebung der relevantesten Inhalte aus der gesamten App zu erzielen.
Unabhängig davon scheint es, dass Twitter voranschreitet, und jetzt haben externe Entwickler mehr Einblick in die Funktionsweise des Twitter-Algorithmus, was zu einer neuen Flut von Erkenntnissen und Hinweisen führen wird, wie man das System spielen kann.
Twitter hofft, dass es auch dabei hilft, seine Algorithmen schnell zu verbessern. Vielleicht kommt das auch vor. Wir müssen abwarten.