
Wie optimieren Sie Ihre Website für Suchmaschinen-Crawler?
Veröffentlicht: 2023-04-27Webcrawler gehen ständig Websites durch, um festzustellen, worum es auf jeder Seite geht. Die Daten können indiziert und modifiziert und gefunden werden, wenn der Benutzer die Anfrage absendet. Einige Websites verwenden Web-Crawling-Roboter, um den Inhalt ihrer Website zu aktualisieren.
Suchmaschinen wie Google oder Bing verwenden eine Suchmaschine in Verbindung mit dem Sammeln von Informationen durch Webcrawler, um relevante Websites und relevante Informationen als Ergebnis von Benutzersuchen anzuzeigen.
Wenn ein Webdesign Unternehmens- oder Websitebesitzer möchten, dass ihre Website in den Suchergebnissen erscheint, muss sie gecrawlt und indexiert werden. Wenn Websites nicht gecrawlt oder indexiert werden, können Suchmaschinen sie nicht organisch finden.
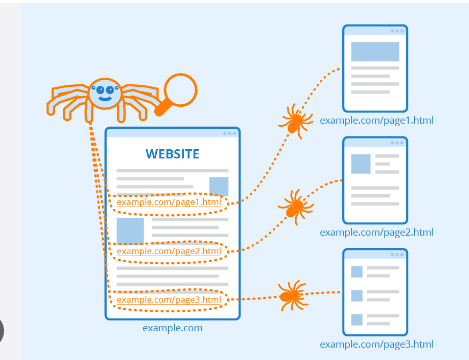
Webcrawler beginnen mit dem Crawlen bestimmter Seiten und folgen dann Hyperlinks auf den Seiten zu neuen Seiten.
Websites, die nicht von Suchmaschinen gecrawlt oder entdeckt werden möchten, können Tools wie die in der robots.txt-Datei verwenden, um Robots anzuweisen, eine Website nicht oder nur einen kleinen Teil davon zu indizieren.
Die Durchführung von Site-Inspektionen mit Crawling-Tools kann Website-Eigentümern dabei helfen, fehlerhafte Hyperlinks oder doppelte Inhalte zu identifizieren. Titel, die fehlen oder zu lang oder zu kurz sind.
Inhaltsverzeichnis
Rolle von Suchmaschinen beim Web Crawling:
1. Knirschen: Suchen Sie im Internet nach Informationen und dann im Quellcode/Inhalt für jede URL, auf die sie stoßen.
2. Indizierung: Verwalten und speichern Sie Informationen, die beim Crawling-Prozess gesammelt wurden. Nachdem eine Seite in den Index aufgenommen wurde, kann es ein kontinuierlicher Prozess sein, sie als Ergebnis relevanter Suchen anzuzeigen.
3. Ranking: Präsentieren Sie die Informationen, die am ehesten den Anforderungen des Benutzers entsprechen.
Was genau ist Crawlen bei Google?
Crawling ist die Suchmethode, die Suchmaschinen verwenden, um eine Reihe von Robotern (Spider und Crawler) zu verteilen, um frische und aktualisierte Inhalte zu finden.
Die Inhalte können in verschiedenen Formaten vorliegen, wie Bilder, Webseiten oder Videos, PDFs usw. Unabhängig vom Formattyp werden die Inhalte über Hyperlinks gefunden.
Der Googlebot beginnt damit, bestimmte Websites zu durchsuchen; Danach scannt es die Hyperlinks der Seiten, um neue URLs zu finden.
Beim Durchlaufen der Hyperlinks kann der Crawler neue Inhalte entdecken, die er in seinen Index namens Caffeine aufnehmen kann.
Es ist eine riesige Datenbank mit kürzlich entdeckten URLs, die abgerufen werden kann, wenn jemand nach Informationen auf einer Website sucht, deren Inhalts-URL perfekt übereinstimmt.
Suchmaschinen-Rankings:
Wenn jemand eine Google-Suche durchführt, scannen die Suchmaschinen ihre Indizes, um relevanten Inhalt zu finden, und ordnen dann den Inhalt, um die Frage zu lösen.
Die Reihenfolge, in der Suchergebnisse nach Relevanz angeordnet sind, wird als Ranking bezeichnet.
Sie können die Crawler von Suchmaschinen daran hindern, einen bestimmten Teil oder sogar Ihre gesamte Website zu crawlen, oder Suchmaschinen anweisen, bestimmte Websites nicht in ihren Index aufzunehmen.
Wenn Sie möchten, dass Ihre Website über Suchmaschinenergebnisse indexiert wird, sollten Sie sicherstellen, dass sie für Crawler zugänglich und indexierbar ist.
Crawlende Suchmaschinen:
Wie Sie gesehen haben, ist es wichtig, sicherzustellen, dass Ihre Website gecrawlt, indexiert und gecrawlt wird, damit sie in den Suchergebnissen erscheint. Wenn es Ihr Unternehmen ist site im Index der aufgerufenen Site befindet, ist es eine gute Idee, sich zunächst die Anzahl der Seiten in den Suchergebnissen anzusehen.

Dies kann Ihnen einen hervorragenden Einblick geben, wie Google Ihre Website durchsucht hat, um jede Seite zu finden, auf die Sie verlinken möchten, aber keine Seiten entdeckt, die Sie nicht sind.
Ergebnisse: Die Anzahl der Ergebnisse, die Google anzeigt, ist nicht exakt. Es vermittelt Ihnen jedoch einen Einblick in die auf Ihrer Website gefundenen Seiten und die Art und Weise, wie sie auf den Suchergebnisseiten angezeigt werden.
Das Tool ermöglicht es Webdesign-Trends, Sitemaps auf Ihre Website hochzuladen und die Anzahl der eingereichten Seiten zu verfolgen, die in den Index von Google aufgenommen werden sollen, und andere Aspekte.
Wenn Ihre Website nicht auf der Ergebnisseite erscheint, gibt es viele Gründe, warum Sie nachsehen sollten:
- Ihre Website ist neu und muss noch gecrawlt werden.
- Die Navigation Ihrer Website macht es Crawlern schwer, effizient darin zu navigieren.
- Ihre Website hat einen elementaren Code namens Crawler-Direktiven, die Anweisungen des Crawlers von Suchmaschinen blockieren.
- Ihre Website wurde von Google aus der Liste entfernt, weil sie Spam-Methoden verwendete.
Lassen Sie Suchmaschinen wissen, wie sie zu Ihrer Website gelangen können :
Wenn Sie die Google Search Console oder die erweiterte Suchmaschine „site: domain.com“ ausprobiert und festgestellt haben, dass einige Ihrer wichtigen Seiten nicht im Index aufgeführt sind oder dass bestimmte Seiten, die nicht so wichtig sind, nicht richtig indexiert wurden , gibt es einige Möglichkeiten, den Googlebot so zu verwalten, wie der Inhalt Ihrer Website gecrawlt werden soll.
Viele konzentrieren sich darauf, sicherzustellen, dass Google ihre wichtigsten Websites findet, aber es ist leicht zu übersehen, was höchstwahrscheinlich ein paar Seiten sind, die der Googlebot nicht finden soll.
Dies können ältere URLs ohne Informationen und zahlreiche URLs (wie Filter und Sortierparameter für E-Commerce), Aktionscodes, Staging- oder Testseiten und vieles mehr sein.
Abschluss:
Google leistet hervorragende Arbeit bei der Bestimmung der richtigen URL für Ihre Website.
Sie können diese Funktion jedoch auch in der Search Console verwenden, um Google genau mitzuteilen, wie Ihre Websites Ihrer Meinung nach behandelt werden sollen.
Wenn Sie diese Funktion verwenden, um den Googlebot anzuweisen, „URLs zu finden, die den Parameter ____ nicht enthalten“, versucht er Google davon zu überzeugen, diese Informationen vom Googlebot fernzuhalten und diese Seiten somit aus den Suchergebnissen zu entfernen.
Das suchen Sie, wenn diese Parameter zu doppelten Seiten führen. Es gibt jedoch bessere Alternativen dazu, wenn Sie möchten, dass diese Seiten aufgenommen werden.
Häufig gestellte Fragen:
Finden Sie, dass der Inhalt Ihrer Website verschwindet, wenn Sie das Anmeldeformular verwenden?
Suchmaschinen können nicht auf geschützte Seiten zugreifen, wenn Sie von Benutzern verlangen, dass sie sich anmelden und Formulare oder Umfragen ausfüllen, bevor sie auf bestimmte Websites zugreifen. Ein Crawler benötigt zwangsläufig Unterstützung beim Einloggen.
Sollten Sie die Suchseite von Google verwenden?
Suchformulare sind für Roboter nicht zugänglich. Einige Leute glauben, dass Suchmaschinen finden können, wonach Benutzer suchen, wenn sie Suchoptionen in ihre Website aufnehmen.
Können Suchmaschinen der Richtung Ihrer Website folgen?
Ein Crawler muss Ihre Website über Hyperlinks zu anderen Websites finden und benötigt eine Liste von Links, die den Benutzer von einer Seite zur anderen leiten. Wenn Sie eine Seite haben, die von Suchmaschinen gefunden werden soll, aber nicht mit einer anderen Seite verbunden ist, ist dies viel effektiver, als unbemerkt zu bleiben.