
Optimierung des Crawl-Budgets: 8 Tipps, um verschwendetes Crawl-Budget zu stoppen
Veröffentlicht: 2022-07-26Fazit: Wenn Google Ihre wichtigen Seiten nicht crawlen kann, werden sie nicht in den Suchergebnissen angezeigt. Dies könnte zu einem niedriger als erwarteten organischen Traffic und deprimierten Rankings führen.
Die Optimierung des Crawling-Budgets erleichtert Google den Zugriff, das Crawling und die Indizierung jeder Ihrer wichtigen Seiten, sodass Sie mehr Kunden über die Suche erreichen können. Hier ist, was Sie über das Crawl-Budget wissen müssen, wie Sie Verschwendung von Crawl-Budget erkennen und was Sie tun können, um Ihre Website zu optimieren, um mögliche Probleme mit dem Crawl-Budget für SEO zu vermeiden.
Was ist Crawl-Budget?
Ihr Crawl-Budget bezieht sich auf die Anzahl der Seiten Ihrer Website, die Google an einem bestimmten Tag durchsucht. Sie basiert auf Ihrem Limit für die Crawling-Rate und der Crawling-Nachfrage.
Ihr Limit für die Crawling-Rate ist die Anzahl der Seiten, die Google crawlen kann, ohne die Nutzererfahrung Ihrer Website zu beeinträchtigen. Im Wesentlichen möchte Google Ihren Server nicht mit Anfragen überlasten, also findet es einen guten Mittelweg zwischen dem, was Ihr Server handhaben kann (Ihre Serverressourcen) und wie viel er Ihre Website crawlen „will“.
Ihre Crawling-Nachfrage wird durch die Beliebtheit und Aktualität einer URL bestimmt. Wenn eine URL veraltet ist und nur wenige Leute danach suchen, wird Google sie seltener crawlen.
Während Sie Ihre Crawling-Rate nicht beeinflussen können, können Sie Ihre Crawling-Nachfrage beeinflussen, indem Sie neue Inhalte erstellen, Ihre Website mit SEO-Best Practices optimieren und SEO-Probleme wie 404-Fehler und unnötige Weiterleitungen angehen.
Was ist Crawl-Budget-Optimierung?
Durch die Optimierung des Crawling-Budgets wird der Zugriff, das Crawling und die Indizierung Ihrer Website für den Googlebot erleichtert, indem die Navigation des Such-Crawlers verbessert und die Verschwendung von Crawling-Budget reduziert wird. Dazu gehören die Reduzierung von Fehlern und defekten Links, die Verbesserung der internen Verlinkung, die Noindexierung von doppelten Inhalten und mehr.
Das Crawling-Budget kann zu einem Problem werden, wenn Google die Seiten Ihrer Website nicht ausreichend oder nicht häufig genug crawlt.
Da Google nur über eine bestimmte Anzahl von Ressourcen verfügt, kann es einer bestimmten Website an einem bestimmten Tag nur eine bestimmte Anzahl von Crawls zuweisen. Wenn Sie eine große Website haben, bedeutet dies, dass Google möglicherweise nur über die Ressourcen verfügt, um täglich einen kleinen Teil der Seiten Ihrer Website zu crawlen. Dies kann sich darauf auswirken, wie lange es dauert, bis Ihre Seiten indexiert oder Inhaltsaktualisierungen in den Google-Rankings widergespiegelt werden.
Wenn Sie der Meinung sind, dass Ihre Website möglicherweise unter Problemen mit dem Crawl-Budget von Google leidet, gibt es zum Glück bestimmte Dinge, die Sie tun können, um Ihre Website zu optimieren und das Beste aus Ihrem Crawl-Budget herauszuholen.
So überprüfen Sie Ihren Crawling-Statistikbericht
Sie können Probleme mit dem Crawling-Budget identifizieren, indem Sie Ihre Crawling-Statistiken in der Google Search Console überprüfen oder Ihre Serverdateiprotokolle analysieren.
Wenn Sie Ihren Crawling-Statistikbericht in der Google Search Console anzeigen, können Sie besser verstehen, wie der Googlebot mit Ihrer Website interagiert. Hier ist, wie Sie es verwenden können, um zu sehen, was der Crawler von Google vorhat.
Öffnen Sie die Google Search Console, melden Sie sich an und wählen Sie Ihre Website aus. Wählen Sie dann im Search Console-Menü die Option „Einstellungen“.
Sie können Ihren Crawling-Bericht für die letzten 90 Tage im Abschnitt Crawling-Statistiken einsehen. Öffnen Sie ihn, indem Sie auf „Bericht öffnen“ klicken.
Was Ihr Crawl-Statistikbericht bedeutet
Da Sie nun die Aktivitäten des Googlebots sehen können, ist es an der Zeit, die Daten zu entschlüsseln. Hier ist eine kurze Aufschlüsselung der Art von Informationen, die Sie aus Ihrem Crawling-Bericht erhalten können.
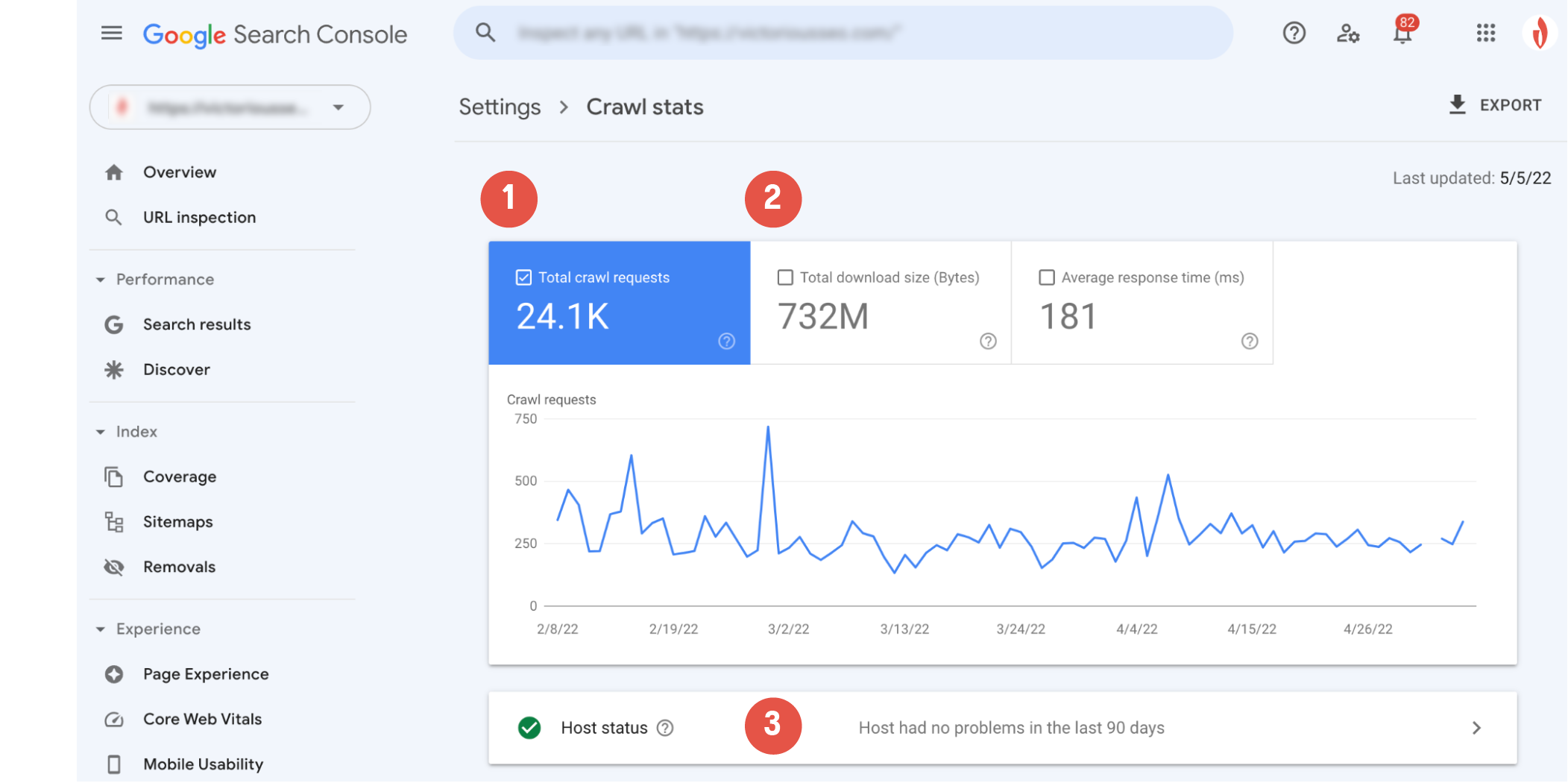
Das Haupt-Crawling-Diagramm zeigt Ihnen eine visuelle Darstellung der Crawling-Aktivität des Googlebot. Hier sehen Sie (1) wie viele Crawl-Anfragen Google in den letzten 90 Tagen gestellt hat und (2) die durchschnittliche Antwortzeit des Servers Ihrer Website und die Gesamtmenge der beim Crawlen heruntergeladenen Bytes.
Der Abschnitt „Hoststatus“ (3) informiert Sie darüber, ob der Crawler beim Zugriff auf Ihre Website auf Verfügbarkeitsprobleme gestoßen ist.
Ein grüner Kreis mit einem weißen Häkchen bedeutet, dass der Googlebot keine Probleme festgestellt hat, und zeigt an, dass Ihr Host reibungslos läuft.
Ein weißer Kreis mit einem grünen Häkchen bedeutet, dass der Googlebot vor über einer Woche auf ein Problem gestoßen ist, aber jetzt läuft alles einwandfrei.
Ein roter Kreis mit einem weißen Ausrufezeichen zeigt an, dass der Googlebot in der vergangenen Woche auf mindestens ein schwerwiegendes Problem gestoßen ist.
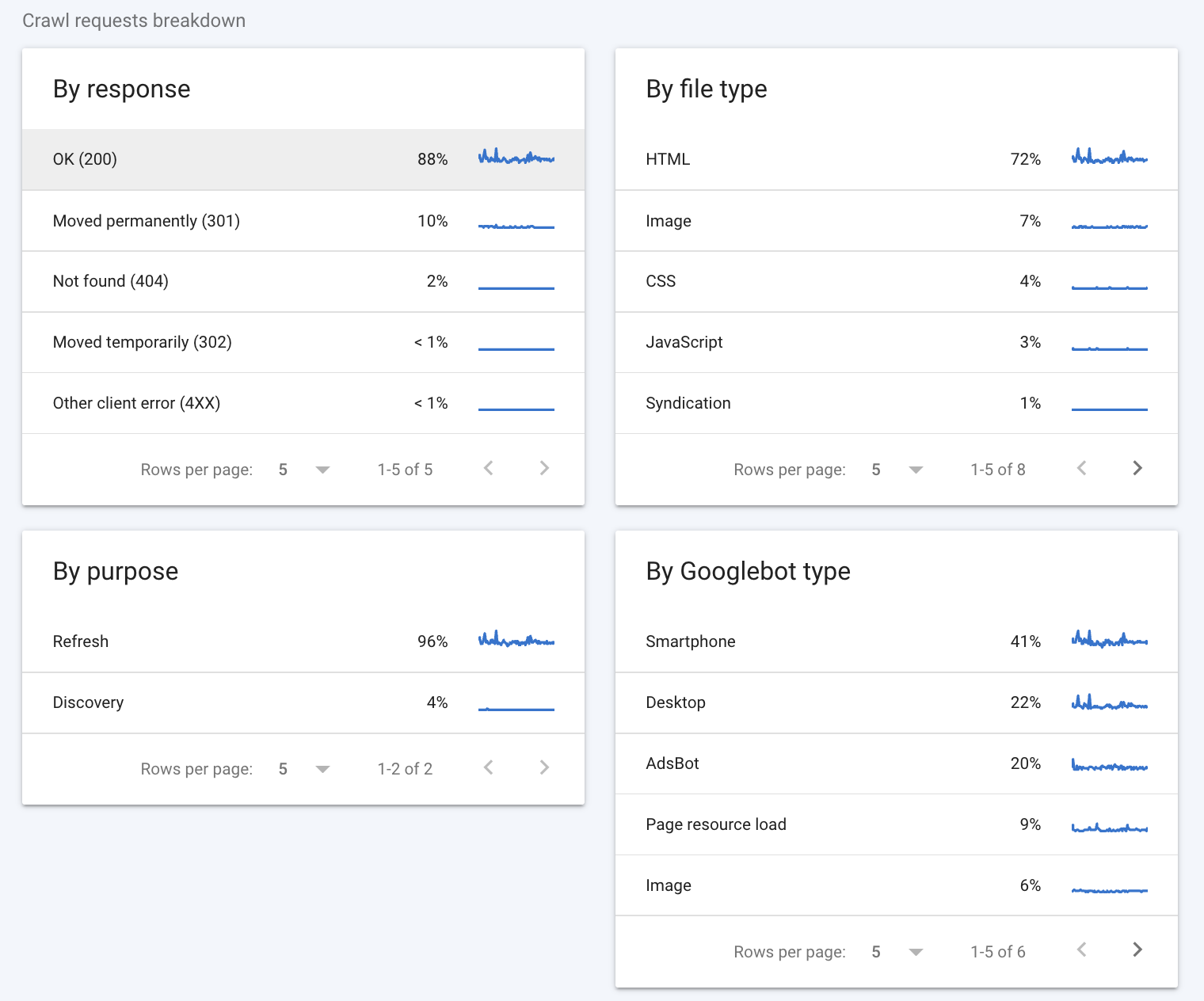
Die Aufschlüsselung der Crawling-Anforderungen bietet einige detailliertere Informationen darüber, wie die Crawler von Google mit Ihrer Website interagiert haben.
Nach Antwort
Der erste Abschnitt, den Sie sich ansehen sollten, ist der Abschnitt „Nach Antwort“. In diesem Abschnitt erfahren Sie, welche Art von Antworten der Googlebot erhalten hat, als er versuchte, die Seiten Ihrer Website zu crawlen. Google betrachtet die folgenden Antworten als gute Antworten:
- OK (200)
- Dauerhaft verschoben (301)
- Vorübergehend verschoben (302)
- Umgezogen (andere)
- Nicht modifiziert (304)
Idealerweise sollte die Mehrheit der Antworten 200 sein (einige 301er sind auch ok). Codes wie „Nicht gefunden (404)“ weisen darauf hin, dass es wahrscheinlich Sackgassen auf Ihrer Website gibt, die sich möglicherweise auf Ihr Crawl-Budget auswirken.
Dateityp
Im Abschnitt "Nach Dateityp" erfahren Sie, auf welchen Dateityp der Googlebot beim Crawlen gestoßen ist. Die angezeigten Prozentwerte sind repräsentativ für den Prozentsatz der Antworten dieses Typs und nicht für den Prozentsatz der Bytes jedes Dateityps.
Nach Verwendungszweck
Der Abschnitt „Nach Zweck“ gibt an, ob die gecrawlte Seite eine Seite war, die der Crawler zuvor gesehen hat (eine Aktualisierung) oder eine, die für den Crawler neu ist (eine Entdeckung).
Nach Googlebot-Typ
Schließlich informiert Sie der Abschnitt "Nach Googlebot-Typ" über die Arten von Googlebot-Crawling-Agenten, die verwendet werden, um Anfragen zu stellen und Ihre Website zu crawlen. Beispielsweise weist der Typ „Smartphone“ auf einen Besuch durch den Smartphone-Crawler von Google hin, während der Typ „AdsBot“ auf einen Crawl durch einen der AdsBot-Crawler von Google hinweist. Als Nebenbemerkung können Sie jederzeit bestimmte Arten von Googlebots daran hindern, Ihre Website zu crawlen, indem Sie die robots.txt-Datei bearbeiten.
Sehen Sie sich den Google-Leitfaden zu Search Console-Crawling-Berichten an, wenn Sie mehr darüber erfahren möchten, wie Sie die Daten in Ihrem Crawling-Bericht interpretieren.
So erkennen Sie, ob Sie Ihr Crawl-Budget verschwenden
Ob die Optimierung des Crawling-Budgets dem Googlebot hilft, mehr Ihrer Seiten zu crawlen, lässt sich schnell feststellen, indem Sie sehen, wie viel Prozent der Seiten Ihrer Website tatsächlich pro Tag gecrawlt werden.
Finden Sie genau heraus, wie viele eindeutige Seiten Sie auf Ihrer Website haben, und teilen Sie sie durch die Zahl „durchschnittlich gecrawlt pro Tag“. Wenn Sie zehn oder mehr Seiten insgesamt pro Tag gecrawlt haben, sollten Sie eine Optimierung des Crawl-Budgets in Betracht ziehen.
Wenn Sie der Meinung sind, dass Sie Probleme mit dem Crawling-Budget haben, sehen Sie sich zunächst den Abschnitt „Nach Antwort“ an, um zu sehen, auf welche Art von Fehlern der Crawler möglicherweise stößt. Sie müssen wahrscheinlich eine tiefere Analyse durchführen, um genau zu sehen, was Ihr Budget auffrisst. Ein Blick auf Ihre Serverprotokolle kann Ihnen weitere Informationen darüber geben, wie der Crawler mit Ihrer Website interagiert.
Überprüfen Sie Ihre Serverprotokolle
Eine weitere Möglichkeit, um zu überprüfen, ob Sie Crawl-Budget verschwenden, besteht darin, sich die Serverprotokolle Ihrer Website anzusehen. Diese Protokolle speichern jede einzelne Anfrage an Ihre Website, einschließlich der Anfragen, die der Googlebot beim Crawlen Ihrer Website stellt. Die Analyse Ihrer Serverprotokolle kann Ihnen Aufschluss darüber geben, wie oft Google Ihre Website crawlt, auf welche Seiten der Crawler am häufigsten zugreift und auf welche Art von Fehlern der Crawler-Bot gestoßen ist.

Sie können diese Protokolle manuell überprüfen, obwohl das Graben nach diesen Daten etwas mühsam sein kann. Glücklicherweise können Ihnen mehrere verschiedene Protokollanalyse-Tools helfen, Ihre Protokolldaten zu sortieren und zu verstehen, wie der SEMRush-Protokolldatei-Analysator oder der Screaming Frog SEO-Protokolldatei-Analysator.
Crawl-Budget-SEO: 8 Möglichkeiten zur Optimierung Ihres Crawl-Budgets
Haben Sie verschwendetes Crawl-Budget aufgedeckt? SEO-Optimierungsstrategien für Crawl-Budgets können Ihnen dabei helfen, Verschwendung einzudämmen. Hier sind acht Tipps, die Ihnen helfen, Ihr SEO-Crawling-Budget für eine bessere Leistung zu optimieren.
1. Optimieren Sie die Robots.txt- und Meta-Roboter-Tags
Eine Möglichkeit, verschwendetes Crawl-Budget einzudämmen, besteht darin, den Crawler von Google von vornherein daran zu hindern, bestimmte Seiten zu crawlen. Indem Sie den Googlebot von Seiten fernhalten, die Sie nicht indexieren möchten, können Sie seine Aufmerksamkeit auf Ihre wichtigeren Seiten lenken.
Die robots.txt-Datei setzt Grenzen für Such-Crawler, indem sie angibt, welche Seiten gecrawlt werden sollen und welche tabu sind. Wenn Sie Ihrer robots.txt-Datei einen disallow-Befehl hinzufügen, werden Crawler daran gehindert, auf die angegebenen Unterverzeichnisse zuzugreifen, sie zu crawlen und zu indizieren, es sei denn, es gibt Links, die auf diese Seiten verweisen.
Auf Seitenebene können Sie Meta-Roboter-Tags verwenden, um bestimmte Seiten zu noindexen. Ein Noindex-Tag ermöglicht es dem Googlebot, auf Ihre Seite zuzugreifen und deren Links darauf zu folgen, aber es weist den Googlebot an, die Seite selbst nicht zu indizieren. Dieses Tag geht direkt in das <head>-Element Ihres HTML-Codes und sieht so aus:
<meta name=”robots” content=”noindex” />2. Inhalt beschneiden
Das Hosten von URLs mit geringem Wert oder doppelten Inhalten auf Ihrer Website kann Ihr Crawl-Budget belasten. Ein tiefer Einblick in die Seiten Ihrer Website kann Ihnen helfen, unnötige Seiten zu identifizieren, die das Crawl-Budget auffressen und verhindern können, dass wertvollere Inhalte gecrawlt und indexiert werden.
Was gilt als URL mit niedrigem Wert? Laut Google fallen URLs mit geringem Wert typischerweise in eine von mehreren Kategorien:
- Doppelte Inhalte
- Sitzungskennungen
- Weiche Fehlerseiten
- Gehackte Seiten
- Niedrige Qualität und Spam-Inhalte
Duplicate Content ist nicht immer leicht zu erkennen. Wenn die meisten Inhalte auf einer Seite mit denen einer anderen Seite identisch sind – selbst wenn Sie weitere Inhalte hinzugefügt oder einige Wörter geändert haben – wird Google sie als deutlich ähnlich ansehen. Verwenden Sie noindex-Meta-Tags und kanonische Tags, um anzugeben, welche Seite das Original ist, das indiziert werden soll.
Indem Sie Inhalte aktualisieren, entfernen oder nicht indizieren, die möglicherweise als geringwertig eingestuft werden, geben Sie dem Googlebot mehr Möglichkeiten, die wirklich wichtigen Seiten Ihrer Website zu crawlen.
Literatur-Empfehlungen
- Duplicate Content SEO: So prüfen Sie auf Duplicate Content
- Warum Content Pruning Ihrer SEO hilft (und wie es geht)
3. JavaScript entfernen oder rendern
Der Googlebot hat kein Problem damit, HTML zu lesen, er muss jedoch JavaScript rendern, bevor er es lesen und indizieren kann. Anstatt also ein JavaScript-Element auf einer Seite zu crawlen und zu indizieren, crawlt Google den HTML-Inhalt auf der Seite und platziert die Seite dann in einer Render-Warteschlange. Wenn es Zeit und Ressourcen hat, sich dem Rendern zu widmen, wird es das JavaScript rendern und „lesen“ und es schließlich indizieren. Dieser zusätzliche Schritt nimmt nicht nur mehr Zeit in Anspruch, sondern auch mehr Crawl-Budget.
JavaScript kann sich auch auf die Ladezeiten Ihrer Seite auswirken, und da sich die Geschwindigkeit der Website und die Serverlast auf Ihr Crawl-Budget auswirken, crawlt Google Ihre Website möglicherweise weniger häufig als Sie möchten, wenn sie mit zu viel JavaScript festgefahren ist.
Um das Crawling-Budget zu schonen, können Sie Seiten mit JavaScript noindexieren, Ihre JavaScript-Elemente entfernen oder ein Tool wie Prerender verwenden, das dynamische JavaScript-Inhalte als statisches HTML rendert und es Google erleichtert, sie zu verstehen und zu crawlen.
4. Entfernen Sie 301-Umleitungsketten
301-Weiterleitungen sind eine nützliche und SEO-freundliche Methode, um Traffic und Linkkapital von einer URL, die Sie entfernen möchten, auf eine andere relevante URL zu übertragen.
Es ist jedoch leicht, versehentlich Weiterleitungsketten zu erstellen, wenn Sie Ihre Weiterleitungen nicht verfolgen. Dies kann nicht nur zu längeren Ladezeiten für die Besucher Ihrer Website führen, sondern auch dazu führen, dass Crawler mehrere URLs crawlen, nur um auf eine Seite mit tatsächlichem Inhalt zuzugreifen. Das bedeutet, dass Google jede URL in der Weiterleitungskette crawlen muss, um zur Zielseite zu gelangen, und dabei Ihr Crawl-Budget auffrisst.
Um dies zu verhindern, stellen Sie sicher, dass alle Ihre Weiterleitungen auf ihr endgültiges Ziel verweisen. Es empfiehlt sich immer, die Verwendung von Umleitungsketten nach Möglichkeit zu vermeiden. Trotzdem passieren Fehler, also nehmen Sie sich etwas Zeit, um Ihre Website manuell zu durchsuchen, oder verwenden Sie ein Tool zur Weiterleitungsprüfung, um 301-Weiterleitungsketten zu erkennen und zu bereinigen.
5. Befolgen Sie die Best Practices für XML-Sitemaps
Ihre Sitemap teilt alle Ihre wichtigen Seiten mit Such-Crawlern – oder sollte es zumindest. Suchmaschinen crawlen Sitemaps, um Seiten leicht zu finden. Obwohl Google sagt, dass es keinen braucht, um Ihre Seiten zu finden, ist es trotzdem eine gute Idee, einen zu pflegen.
Um gut zu funktionieren, sollte Ihre Sitemap nur Seiten enthalten, die Sie indizieren möchten. Sie sollten alle nicht indexierten oder umgeleiteten URLs aus Ihrer Sitemap entfernen. Eine einfache Möglichkeit, dies zu tun, ist eine dynamisch generierte XML-Sitemap. Dynamisch generierte Sitemaps aktualisieren sich selbst, sodass Sie sich keine Gedanken über die Bearbeitung Ihrer nach jeder 301-Implementierung machen müssen.
Wenn Sie mehrere Unterverzeichnisse auf Ihrer Website haben, verwenden Sie einen Sitemap-Index, der Links zu den Sitemaps aller Unterverzeichnisse enthält. Dies hilft, Ihre Website-Architektur zu präsentieren und bietet eine einfache Roadmap für Such-Crawler, der sie folgen können.
6. Erstellen Sie eine interne Verlinkungsstrategie
Interne Links helfen den Website-Besuchern nicht nur, sich fortzubewegen; Sie schaffen auch einen klareren Bewegungspfad für Crawler-Bots.
Eine gut entwickelte interne Verlinkungsstrategie kann Crawler auf die Seiten verweisen, die gecrawlt werden sollen. Da Crawler Links verwenden, um andere Seiten zu finden, kann die Verknüpfung tieferer Seiten mit übergeordneten Inhalten dem Crawler helfen, schneller auf sie zuzugreifen. Gleichzeitig kann das Entfernen von Links von Seiten mit niedriger Priorität, die Sie nicht in Ihr Crawl-Budget fressen möchten, dazu beitragen, sie an das Ende der Warteschlange zu schieben und sicherzustellen, dass Ihre wichtigen Seiten zuerst gecrawlt werden.
7. Beheben Sie Site-Fehler
Website-Fehler können Such-Crawler zum Stolpern bringen und wertvolles Crawl-Budget verschwenden. Idealerweise möchten Sie, dass der Crawler entweder auf eine tatsächliche Seite oder auf eine einzelne Weiterleitung zu dieser Seite trifft. Wenn es auf Umleitungsketten oder eine 404-Fehlerseite stößt, verschwenden Sie Crawl-Budget.
Verwenden Sie Ihren Crawl-Bericht der Google Search Console, um festzustellen, wo der Crawler auf Fehler stößt und um welche Art von Fehlern es sich handelt. Das Ausbügeln aller identifizierbaren Fehler sorgt für ein reibungsloseres Crawling-Erlebnis für den Googlebot.
8. Suchen Sie nach defekten Links
Eine URL ist im Grunde eine Brücke zwischen zwei Seiten. Es bietet Suchmaschinen-Crawlern einen Weg, um neue Seiten zu finden – aber einige URLs führen nirgendwohin. Ein defekter Link ist eine Sackgasse für Suchmaschinen-Crawler und eine Verschwendung Ihres begrenzten Crawl-Budgets.
Nehmen Sie sich etwas Zeit, um Ihre Website auf defekte Links zu überprüfen, die Such-Crawler möglicherweise auf tote Seiten schicken, und korrigieren oder entfernen Sie diese. Sie reduzieren nicht nur die Verschwendung von Crawl-Budget, sondern verbessern auch das Surferlebnis der Besucher, indem Sie fehlerhafte Links entfernen. Daher ist eine regelmäßige Überprüfung der Links immer eine gute Idee.
Stoppen Sie verschwendetes Crawl-Budget mit einem SEO-Audit
Fühlen Sie sich überfordert oder sind sich nicht sicher, wo Sie mit der Optimierung des Crawl-Budgets Ihrer Website oder der allgemeinen SEO beginnen sollen? Es besteht keine Notwendigkeit, es alleine zu tun. Buchen Sie noch heute eine Beratung bei Victorious und lassen Sie sich von unseren Experten bei der Durchführung eines SEO-Audits und der Entwicklung einer Strategie zur Optimierung der SEO Ihrer Website unterstützen.