
Entlarvung von 3 verbreiteten Mythen hinter Site-Crawling, Indexierung und XML-Sitemaps
Veröffentlicht: 2018-03-07Viele von uns glauben fälschlicherweise, dass beim Starten einer Website, die mit einer XML-Sitemap ausgestattet ist, automatisch alle Seiten gecrawlt und indexiert werden.
In dieser Hinsicht bauen sich einige Mythen und Missverständnisse auf. Die häufigsten sind:
- Google crawlt automatisch alle Seiten und das schnell.
- Beim Crawlen einer Website folgt Google allen Links und besucht alle ihre Seiten und nimmt sie alle sofort in den Index auf.
- Das Hinzufügen einer XML-Sitemap ist der beste Weg, um alle Seiten der Website zu crawlen und zu indizieren.
Leider ist es etwas komplizierter, Ihre Website in den Index von Google aufzunehmen. Lesen Sie weiter, um eine bessere Vorstellung davon zu bekommen, wie der Prozess des Crawlens und Indexierens funktioniert und welche Rolle eine XML-Sitemap dabei spielt.
Bevor wir uns daran machen, die oben genannten Mythen zu entlarven, wollen wir einige grundlegende SEO-Begriffe lernen:
Crawling ist eine Aktivität, die von Suchmaschinen implementiert wird, um URLs aus dem gesamten Web zu verfolgen und zu sammeln.
Die Indexierung ist der Prozess, der auf das Crawlen folgt. Grundsätzlich geht es um das Parsen und Speichern von Webdaten, die später beim Bereitstellen von Ergebnissen für Suchmaschinenanfragen verwendet werden. Der Suchmaschinenindex ist der Ort, an dem alle gesammelten Webdaten zur weiteren Verwendung gespeichert werden.
Crawl Rank ist der Wert, den Google Ihrer Website und ihren Seiten zuweist. Es ist noch unbekannt, wie diese Metrik von der Suchmaschine berechnet wird. Google hat mehrfach bestätigt, dass die Indexierungshäufigkeit nicht mit dem Ranking zusammenhängt, sodass es keinen direkten Zusammenhang zwischen der Ranking-Autorität einer Website und ihrem Crawling-Rang gibt.
Nachrichten-Websites, Websites mit wertvollen Inhalten und Websites, die regelmäßig aktualisiert werden, haben höhere Chancen, regelmäßig gecrawlt zu werden.
Das Crawl-Budget ist eine Menge an Crawling-Ressourcen, die die Suchmaschine einer Website zuweist. Normalerweise berechnet Google diesen Betrag basierend auf dem Crawling-Rang Ihrer Website.
Die Crawling-Tiefe ist ein Ausmaß, in dem Google beim Erkunden eine Website-Ebene aufbohrt.
Die Crawling-Priorität ist eine Ordnungszahl, die einer Site-Seite zugewiesen wird und ihre Bedeutung in Bezug auf das Crawling angibt.
Nun, nachdem wir alle Grundlagen des Prozesses kennen, lassen Sie uns diese 3 Mythen hinter XML-Sitemaps, Crawling und Indexierung aufdecken!
Inhaltsverzeichnis
- Mythos 1. Google crawlt automatisch alle Seiten und das schnell.
- Imbiss
- Mythos 2. Das Hinzufügen einer XML-Sitemap ist der beste Weg, um alle Seiten der Website zu crawlen und zu indizieren.
- Imbiss
- Mythos 3. Eine XML-Sitemap kann alle Crawling- und Indexierungsprobleme lösen.
- Imbiss
Mythos 1. Google crawlt automatisch alle Seiten und das schnell.
Google behauptet, dass es beim Sammeln von Webdaten agil und flexibel ist.
Aber um ehrlich zu sein, denn im Moment gibt es Billionen von Seiten im Web, technisch gesehen kann die Suchmaschine sie nicht alle schnell durchsuchen.
Auswählen von Websites, denen Crawl-Budget zugewiesen werden soll
Der intelligente Google-Algorithmus (alias Crawl Budget) verteilt die Suchmaschinenressourcen und entscheidet, welche Seiten es wert sind, gecrawlt zu werden und welche nicht.
Normalerweise priorisiert Google vertrauenswürdige Websites, die den festgelegten Anforderungen entsprechen und als Grundlage für die Definition dienen, wie andere Websites abschneiden.
Wenn Sie also eine Website haben, die gerade aus dem Ofen kommt, oder eine Website mit abgekratztem, doppeltem oder dünnem Inhalt, sind die Chancen, dass sie richtig gecrawlt wird, ziemlich gering.
Die wichtigen Faktoren, die auch die Zuweisung des Crawling-Budgets beeinflussen können, sind:
- Website-Größe,
- sein allgemeiner Zustand (dieser Satz von Metriken wird durch die Anzahl der Fehler bestimmt, die Sie möglicherweise auf jeder Seite haben),
- und die Anzahl eingehender und interner Links.
Um Ihre Chancen auf das Crawling-Budget zu erhöhen, stellen Sie sicher, dass Ihre Website alle oben genannten Google-Anforderungen erfüllt, und optimieren Sie die Crawling-Effizienz (siehe nächster Abschnitt im Artikel).
Vorhersage des Crawling-Zeitplans
Google gibt seine Pläne zum Crawlen von Web-URLs nicht bekannt. Außerdem ist es schwierig, die Periodizität zu erraten, mit der die Suchmaschine einige Websites besucht.
Es kann sein, dass eine Website mindestens einmal täglich gecrawlt wird, während eine andere einmal im Monat oder noch seltener besucht wird.
- Die Periodizität der Crawls hängt ab von:
- die Qualität der Seiteninhalte,
- die Neuheit und Relevanz der Informationen, die eine Website liefert,
- und davon, wie wichtig oder beliebt die Suchmaschine Website-URLs sind.
Unter Berücksichtigung dieser Faktoren können Sie versuchen vorherzusagen, wie oft Google Ihre Website besuchen wird.
Die Rolle von externen/internen Links und XML-Sitemaps
Als Verbindungswege verwenden Googlebots Links, die Site-Seiten und Website miteinander verbinden. Somit erreicht die Suchmaschine Billionen miteinander verbundener Seiten, die im Web existieren.
Die Suchmaschine kann Ihre Website von jeder Seite aus scannen, nicht unbedingt von der Startseite. Die Auswahl des Crawl-Einstiegspunkts hängt von der Quelle eines eingehenden Links ab. Angenommen, einige Ihrer Produktseiten enthalten viele Links, die von verschiedenen Websites stammen. Google verbindet die Punkte und besucht solche beliebten Seiten in der ersten Runde.
Eine XML-Sitemap ist ein großartiges Werkzeug, um eine gut durchdachte Seitenstruktur aufzubauen. Darüber hinaus kann es den Prozess des Website-Crawlings zielgerichteter und intelligenter gestalten.
Grundsätzlich ist die Sitemap ein Hub mit allen Site-Links. Jeder darin enthaltene Link kann mit einigen zusätzlichen Informationen ausgestattet werden: das letzte Aktualisierungsdatum, die Aktualisierungshäufigkeit, seine Beziehung zu anderen URLs auf der Website usw.
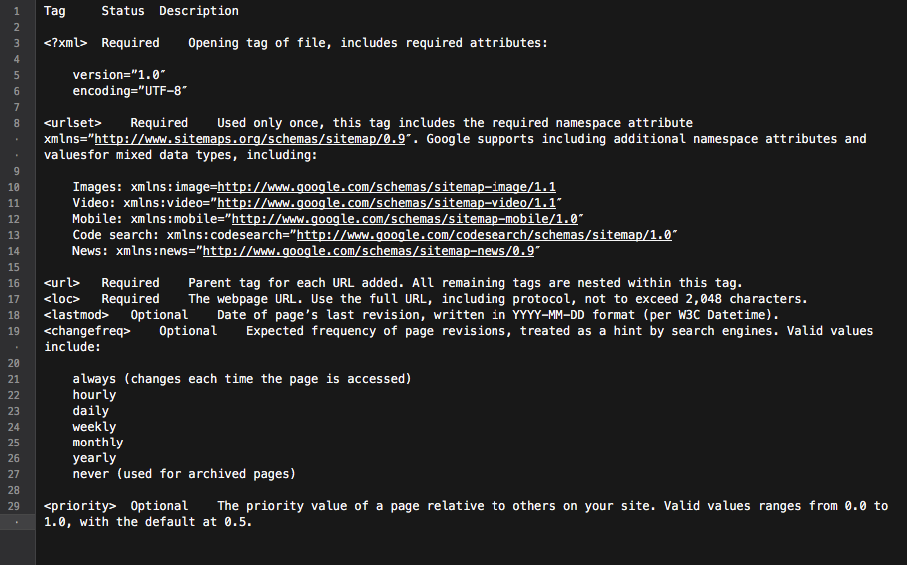 All dies bietet Googlebots eine detaillierte Roadmap zum Crawlen von Websites und macht das Crawlen fundierter. Außerdem geben alle großen Suchmaschinen URLs, die in einer Sitemap aufgeführt sind, Vorrang.
All dies bietet Googlebots eine detaillierte Roadmap zum Crawlen von Websites und macht das Crawlen fundierter. Außerdem geben alle großen Suchmaschinen URLs, die in einer Sitemap aufgeführt sind, Vorrang.
Zusammenfassend lässt sich sagen, dass Sie, um die Seiten Ihrer Website auf das Radar des Googlebot zu bekommen, eine Website mit großartigen Inhalten erstellen und ihre interne Linkstruktur optimieren müssen.
Imbiss
• Google crawlt nicht automatisch alle Ihre Websites.
• Die Periodizität des Website-Crawlings hängt davon ab, wie wichtig oder beliebt die Website und ihre Seiten sind.
• Durch die Aktualisierung von Inhalten besucht Google eine Website häufiger.
• Websites, die nicht den Anforderungen der Suchmaschinen entsprechen, werden wahrscheinlich nicht richtig gecrawlt.
• Websites und Site-Seiten, die keine internen/externen Links haben, werden normalerweise von den Suchmaschinen-Bots ignoriert.
• Das Hinzufügen einer XML-Sitemap kann den Website-Crawling-Prozess verbessern und ihn intelligenter machen.
Mythos 2. Das Hinzufügen einer XML-Sitemap ist der beste Weg, um alle Seiten der Website zu crawlen und zu indizieren.
Jeder Website-Eigentümer möchte, dass der Googlebot alle wichtigen Website-Seiten (mit Ausnahme der vor der Indexierung verborgenen) besucht und neue und aktualisierte Inhalte sofort erkundet.
Die Suchmaschine hat jedoch ihre eigene Vorstellung von den Prioritäten beim Website-Crawling.
Wenn es darum geht, eine Website und ihren Inhalt zu überprüfen, verwendet Google eine Reihe von Algorithmen, die als Crawl-Budget bezeichnet werden. Grundsätzlich erlaubt es der Suchmaschine, die Seiten der Website zu scannen, während sie geschickt ihre eigenen Ressourcen verwendet.
Überprüfung des Crawling-Budgets einer Website
Es ist ganz einfach herauszufinden, wie Ihre Website gecrawlt wird und ob Sie Probleme mit dem Crawling-Budget haben.
Sie müssen nur:
- Zählen Sie die Anzahl der Seiten auf Ihrer Website und in Ihrer XML-Sitemap,
- Besuchen Sie die Google Search Console, gehen Sie zum Abschnitt Crawl -> Crawl Stats und überprüfen Sie, wie viele Seiten auf Ihrer Website täglich gecrawlt werden,
- Teilen Sie die Gesamtzahl der Seiten Ihrer Website durch die Anzahl der Seiten, die pro Tag gecrawlt werden.
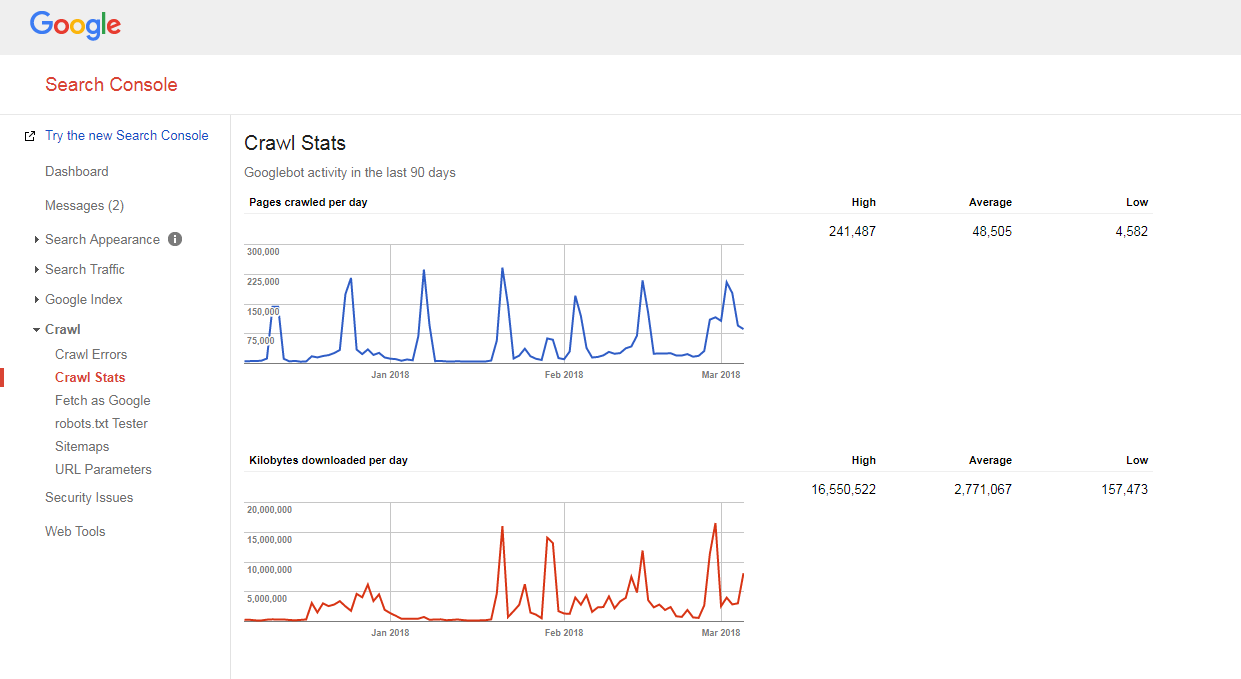 Wenn die Zahl, die Sie haben, größer als 10 ist (es gibt 10x mehr Seiten auf Ihrer Website als Google täglich crawlt), haben wir schlechte Nachrichten für Sie: Ihre Website hat Crawling-Probleme.
Wenn die Zahl, die Sie haben, größer als 10 ist (es gibt 10x mehr Seiten auf Ihrer Website als Google täglich crawlt), haben wir schlechte Nachrichten für Sie: Ihre Website hat Crawling-Probleme.
Aber bevor Sie lernen, wie man sie repariert, müssen Sie einen anderen Begriff verstehen, nämlich ...
Kriechtiefe
Die Crawling-Tiefe ist das Ausmaß, in dem Google eine Website bis zu einem bestimmten Level durchsucht.
Im Allgemeinen wird die Homepage als Level 1 betrachtet, eine Seite, die 1 Klick entfernt ist, ist Level 2 usw.
Deep-Level-Seiten haben einen niedrigeren Pagerank (oder gar keinen) und werden mit geringerer Wahrscheinlichkeit vom Googlebot gecrawlt. Normalerweise gräbt die Suchmaschine nicht tiefer als Stufe 4.
Im Idealfall sollte eine bestimmte Seite 1-4 Klicks von der Startseite oder den Hauptkategorien der Website entfernt sein. Je länger der Pfad zu dieser Seite ist, desto mehr Ressourcen müssen die Suchmaschinen zuweisen, um sie zu erreichen.
Wenn Sie sich auf einer Website befinden, schätzt Google den Pfad als viel zu lang ein und stoppt das weitere Crawling.
Optimierung der Crawling-Tiefe und des Budgets
Um zu verhindern, dass der Googlebot langsamer wird, optimieren Sie das Crawling-Budget und die Crawling-Tiefe Ihrer Website. Gehen Sie dazu wie folgt vor:
- alle 404-, JS- und andere Seitenfehler beheben;
Eine übermäßige Anzahl von Seitenfehlern kann die Geschwindigkeit des Google-Crawlers erheblich verlangsamen. Um alle Hauptseitenfehler zu finden, melden Sie sich in Ihrem Google (Bing, Yandex) Webmaster-Tools-Panel an und befolgen Sie alle hier gegebenen Anweisungen.

- Paginierung optimieren;
Falls Sie zu lange Paginierungslisten haben oder Ihr Paginierungsschema es nicht erlaubt, weiter als ein paar Seiten in der Liste weiter zu klicken, wird der Suchmaschinen-Crawler wahrscheinlich aufhören, einen solchen Seitenstapel auszugraben.
Wenn es auf einer solchen Seite nur wenige Elemente gibt, kann sie als Thin-Content betrachtet werden und wird nicht durchsucht.
- Navigationsfilter prüfen;
Einige Navigationsschemata enthalten möglicherweise mehrere Filter, die neue Seiten generieren (z. B. Seiten, die durch mehrstufige Navigation gefiltert wurden). Obwohl solche Seiten organisches Traffic-Potenzial haben können, können sie auch eine unerwünschte Belastung der Suchmaschinen-Crawler erzeugen.
Der beste Weg, dies zu lösen, besteht darin, systematische Links auf die gefilterten Listen zu beschränken. Idealerweise sollten Sie maximal 1-2 Filter verwenden. Wenn Sie zB einen Shop mit 3 LN-Filtern (Farbe/Größe/Geschlecht) haben, sollten Sie die systematische Kombination von nur 2 Filtern (zB Farbe-Größe, Geschlecht-Größe) zulassen. Falls Sie Kombinationen aus mehreren Filtern hinzufügen müssen, sollten Sie ihnen manuell Links hinzufügen.
- Tracking-Parameter in URLs optimieren;
Verschiedene URL-Tracking-Parameter (z. B. '?source=thispage') können Fallen für die Crawler erstellen, da sie eine riesige Menge neuer URLs generieren. Dieses Problem ist typisch für Seiten mit Blöcken zu „ähnlichen Produkten“ oder „verwandte Geschichten“, bei denen diese Parameter verwendet werden, um das Verhalten der Benutzer zu verfolgen.
Um die Crawling-Effizienz in diesem Fall zu optimieren, empfiehlt es sich, die Tracking-Informationen hinter einem „#“ am Ende der URL zu übermitteln. Auf diese Weise bleibt eine solche URL unverändert. Darüber hinaus ist es auch möglich, URLs mit Tracking-Parametern auf dieselben URLs, jedoch ohne Tracking, umzuleiten.
- übermäßige 301-Weiterleitungen entfernen;
Angenommen, Sie haben einen großen Teil von URLs, auf die ohne nachgestellten Schrägstrich verwiesen wird. Besucht der Suchmaschinen-Bot solche Seiten, wird er auf die Version mit Schrägstrich umgeleitet.
Daher muss der Bot doppelt so viel tun, wie er soll, und schließlich kann er aufgeben und aufhören zu kriechen. Um dies zu vermeiden, versuchen Sie einfach, alle Links auf Ihrer Website zu aktualisieren, wenn Sie die URLs ändern.
Crawl-Priorität
Wie oben erwähnt, priorisiert Google Websites zum Crawlen. Kein Wunder also, dass es dasselbe mit Seiten innerhalb einer gecrawlten Website macht.
Bei den meisten Websites ist die Seite mit der höchsten Crawl-Priorität die Startseite.
Wie bereits erwähnt, kann dies in einigen Fällen jedoch auch die beliebteste Kategorie oder die meistbesuchte Produktseite sein. Um die Seiten zu finden, die vom Googlebot häufiger gecrawlt werden, sehen Sie sich einfach Ihre Serverprotokolle an.
Obwohl Google nicht offiziell ankündigt, dass die Faktoren, die vermutlich die Crawling-Priorität einer Website-Seite beeinflussen können, folgende sind:
- Aufnahme in eine XML-Sitemap (und Hinzufügen der Priority-Tags* für die wichtigsten Seiten),
- die Anzahl eingehender Links,
- die Anzahl der internen Links,
- Seitenpopularität (Anzahl der Besuche),
- Seitenrang.
Aber selbst nachdem Sie den Suchmaschinen-Bots den Weg zum Crawlen Ihrer Website frei gemacht haben, können sie sie immer noch ignorieren. Lesen Sie weiter, um zu erfahren, warum.
Sehen Sie sich diese virtuelle Keynote von Gary Illyes an, um die Crawling-Priorität besser zu verstehen.
Apropos Prioritäts-Tags in einer XML-Sitemap: Sie können entweder manuell oder mit Hilfe der integrierten Funktionalität der Plattform, auf der Ihre Website basiert, hinzugefügt werden. Außerdem unterstützen einige Plattformen XML-Sitemap-Erweiterungen/Apps von Drittanbietern, die den Prozess vereinfachen.
Mit dem XML-Sitemap-Prioritäts-Tag können Sie verschiedenen Kategorien von Website-Seiten die folgenden Werte zuweisen:
- 0.0-0.3 auf Hilfsseiten, veraltete Inhalte und alle Seiten von untergeordneter Bedeutung,
- 0,4-0,7 zu Ihren Blogartikeln, FAQs und sachkundigen Seiten, Kategorie- und Unterkategorieseiten von untergeordneter Bedeutung und
- 0,8-1,0 zu Ihren Hauptseitenkategorien, wichtigen Zielseiten und der Startseite.
Imbiss
• Google hat seine eigene Vorstellung von den Prioritäten des Crawling-Prozesses.
• Eine Seite, die in den Index der Suchmaschine aufgenommen werden soll, sollte 1-4 Klicks von der Homepage, den Hauptkategorien der Website oder den beliebtesten Seiten der Website entfernt sein.
• Um zu verhindern, dass der Googlebot langsamer wird, und um Ihr Website-Crawling-Budget und Ihre Crawling-Tiefe zu optimieren, sollten Sie 404-, JS- und andere Seitenfehler finden und beheben, Seitenumbruch- und Navigationsfilter optimieren, übermäßige 301-Weiterleitungen entfernen und Tracking-Parameter in URLs optimieren.
• Um die Crawling-Priorität wichtiger Website-Seiten zu verbessern, stellen Sie sicher, dass sie in eine XML-Sitemap (mit Prioritäts-Tags) aufgenommen und gut mit anderen Website-Seiten verlinkt sind und Links von anderen relevanten und maßgeblichen Websites haben.
Mythos 3. Eine XML-Sitemap kann alle Crawling- und Indexierungsprobleme lösen.
Eine XML-Sitemap ist zwar ein gutes Kommunikationstool, das Google über Ihre Website-URLs und die Wege zu ihrer Erreichbarkeit informiert, gibt jedoch KEINE Garantie dafür, dass Ihre Website von den Suchmaschinen-Bots besucht wird (ganz zu schweigen davon, dass alle Seiten der Website in den Index aufgenommen werden). .
Außerdem sollten Sie verstehen, dass Sitemaps Ihnen nicht dabei helfen, Ihre Website-Rankings zu verbessern. Selbst wenn eine Seite gecrawlt und in den Suchmaschinenindex aufgenommen wird, hängt ihre Platzierungsleistung von unzähligen anderen Faktoren ab (interne und externe Links, Inhalt, Seitenqualität usw.).
Bei richtiger Verwendung kann eine XML-Sitemap jedoch die Crawling-Effizienz Ihrer Website erheblich verbessern. Nachfolgend finden Sie einige Ratschläge, wie Sie das SEO-Potenzial dieses Tools maximieren können.
Sei konsequent
Denken Sie beim Erstellen einer Sitemap daran, dass sie als Roadmap für Google-Crawler verwendet wird. Daher ist es wichtig, die Suchmaschine nicht durch falsche Wegbeschreibungen in die Irre zu führen.
Beispielsweise können Sie gelegentlich einige Dienstprogrammseiten in Ihre XML-Sitemap aufnehmen ( Kontakt- oder TOS-Seiten, Seiten zum Anmelden, Seite zum Wiederherstellen verlorener Passwörter, Seiten zum Teilen von Inhalten usw.).
Diese Seiten werden normalerweise mit noindex-Roboter-Meta-Tags vor der Indexierung ausgeblendet oder in der robots.txt-Datei nicht zugelassen.
Wenn Sie sie also in eine XML-Sitemap aufnehmen, werden Googlebots nur verwirrt, was den Prozess des Sammelns der Informationen über Ihre Website negativ beeinflussen kann.
Regelmäßig aktualisieren
Die meisten Websites im Web ändern sich fast täglich. Insbesondere E-Commerce-Website mit Produkten und Kategorien, die regelmäßig auf der Website ein- und ausgeblendet werden.
Um Google gut informiert zu halten, müssen Sie Ihre XML-Sitemap auf dem neuesten Stand halten.
Einige Plattformen (Magento, Shopify) verfügen entweder über integrierte Funktionen, mit denen Sie Ihre XML-Sitemaps regelmäßig aktualisieren können, oder unterstützen einige Lösungen von Drittanbietern, die diese Aufgabe ausführen können.
In Magento 2 können Sie beispielsweise die Periodizität der Sitemap-Aktualisierungszyklen festlegen. Wenn Sie es in den Konfigurationseinstellungen der Plattform definieren, signalisieren Sie dem Crawler, dass Ihre Website-Seiten in einem bestimmten Zeitintervall (stündlich, wöchentlich, monatlich) aktualisiert werden und Ihre Website einen weiteren Crawl benötigt.
Klicken Sie hier, um mehr darüber zu erfahren.
Denken Sie jedoch daran, dass das Festlegen von Priorität und Häufigkeit für Sitemap-Aktualisierungen zwar hilfreich ist, sie jedoch möglicherweise nicht mit den tatsächlichen Änderungen Schritt halten und manchmal kein wahres Bild vermitteln.
Stellen Sie daher sicher, dass Ihre Sitemap alle kürzlich vorgenommenen Änderungen widerspiegelt.
 Segmentieren Sie den Website-Content und legen Sie die richtigen Crawling-Prioritäten fest
Segmentieren Sie den Website-Content und legen Sie die richtigen Crawling-Prioritäten fest
Google arbeitet hart daran, die Gesamtqualität der Website zu messen und nur die besten und relevantesten Websites anzuzeigen.
Aber wie es oft vorkommt, sind nicht alle Websites gleich und in der Lage, einen echten Mehrwert zu liefern.
Angenommen, eine Website kann aus 1.000 Seiten bestehen, und nur 50 davon sind mit der Note „A“ ausgezeichnet. Die anderen sind entweder rein funktional, haben veraltete Inhalte oder gar keine Inhalte.
Wenn Google anfängt, eine solche Website zu erkunden, wird es wahrscheinlich entscheiden, dass sie aufgrund des hohen Prozentsatzes an minderwertigen, spammigen oder veralteten Seiten ziemlich trashig ist.
Aus diesem Grund ist es ratsam, beim Erstellen einer XML-Sitemap den Website-Inhalt zu segmentieren und die Suchmaschinen-Bots nur zu den würdigen Website-Bereichen zu leiten.
Und wie Sie sich vielleicht erinnern, können auch die Prioritäts-Tags, die den wichtigsten Website-Seiten in Ihrer XML-Sitemap zugewiesen sind, eine große Hilfe sein.
Imbiss
• Stellen Sie beim Erstellen einer Sitemap sicher, dass Sie keine Seiten mit noindex-Roboter-Meta-Tags vor der Indexierung verbergen oder in der robots.txt-Datei nicht zulassen.
• Aktualisieren Sie XML-Sitemaps (manuell oder automatisch), direkt nachdem Sie Änderungen an der Struktur und dem Inhalt der Website vorgenommen haben.
• Segmentieren Sie den Inhalt Ihrer Website, um nur „A“-Seiten in die Sitemap aufzunehmen.
• Legen Sie die Crawling-Priorität für verschiedene Seitentypen fest.
Das ist es im Grunde.
Haben Sie etwas zum Thema zu sagen? Zögern Sie nicht, Ihre Meinung zu Crawling, Indexierung oder Sitemaps im Kommentarbereich unten mitzuteilen.