
So automatisieren Sie die Orchestrierung von Zugriffsrechten in AWS S3-Buckets
Veröffentlicht: 2023-01-13Vor Jahren, als On-Premise-Unix-Server mit großen Dateisystemen eine Rolle spielten, bauten Unternehmen umfangreiche Ordnerverwaltungsregeln und -strategien auf, um Zugriffsrechte auf verschiedene Ordner für verschiedene Personen zu verwalten.
Normalerweise dient die Plattform einer Organisation verschiedenen Benutzergruppen mit völlig unterschiedlichen Interessen, Einschränkungen der Vertraulichkeitsstufe oder Inhaltsdefinitionen. Im Fall globaler Organisationen könnte dies sogar bedeuten, Inhalte nach Standorten zu trennen, also im Grunde zwischen den Benutzern aus verschiedenen Ländern.

Weitere typische Beispiele könnten sein:
- Datentrennung zwischen Entwicklungs-, Test- und Produktionsumgebungen
- Verkaufsinhalte, die einem breiten Publikum nicht zugänglich sind
- länderspezifische gesetzliche Inhalte, die in einer anderen Region nicht angezeigt oder abgerufen werden können
- projektbezogene Inhalte, bei denen „Führungsdaten“ nur einem begrenzten Personenkreis zur Verfügung gestellt werden sollen etc.
Es gibt eine potenziell endlose Liste solcher Beispiele. Der Punkt ist, dass es immer notwendig ist, Zugriffsrechte auf Dateien und Daten zwischen allen Benutzern zu orchestrieren, denen die Plattform Zugriff gewährt.
Bei On-Premise-Lösungen war dies eine Routineaufgabe. Der Administrator des Dateisystems hat nur einige Regeln aufgestellt, ein Tool seiner Wahl verwendet, und dann wurden Personen Benutzergruppen zugeordnet, und Benutzergruppen wurden einer Liste von Ordnern oder Einhängepunkten zugeordnet, auf die sie zugreifen können sollen. Dabei wurde die Zugriffsebene als Nur-Lese- oder Lese- und Schreibzugriff definiert.
Wenn man sich nun AWS-Cloud-Plattformen ansieht, ist es offensichtlich zu erwarten, dass Menschen ähnliche Anforderungen an Inhaltszugriffsbeschränkungen haben. Die Lösung dieses Problems muss jedoch jetzt anders aussehen. Dateien befinden sich nicht mehr auf Unix-Servern, sondern in der Cloud (und sind möglicherweise nicht nur für die gesamte Organisation, sondern sogar für die ganze Welt zugänglich), und die Inhalte werden nicht in Ordnern, sondern in S3-Buckets gespeichert.

Unten beschrieben ist eine Alternative, um dieses Problem anzugehen. Es baut auf den praktischen Erfahrungen auf, die ich gemacht habe, als ich solche Lösungen für ein konkretes Projekt entworfen habe.
Einfacher, aber weitestgehend manueller Ansatz
Eine Möglichkeit, dieses Problem ohne Automatisierung zu lösen, ist relativ unkompliziert und einfach:
- Erstellen Sie für jede einzelne Personengruppe einen neuen Bucket.
- Weisen Sie dem Bucket Zugriffsrechte zu, sodass nur diese bestimmte Gruppe auf den S3-Bucket zugreifen kann.
Dies ist durchaus möglich, wenn es um eine sehr einfache und schnelle Lösung gehen soll. Es gibt jedoch einige Einschränkungen, die Sie beachten sollten.
Standardmäßig können nur bis zu 100 S3-Buckets unter einem AWS-Konto erstellt werden. Dieses Limit kann auf 1000 erweitert werden, indem eine Erhöhung des Servicelimits für das AWS-Ticket eingereicht wird. Wenn diese Limits nicht etwas sind, worüber Sie sich in Ihrem speziellen Implementierungsfall Sorgen machen würden, können Sie jeden Ihrer unterschiedlichen Domänenbenutzer auf einem separaten S3-Bucket arbeiten lassen und damit Schluss machen.
Die Probleme können auftreten, wenn es einige Gruppen von Personen mit funktionsübergreifenden Verantwortlichkeiten gibt oder einfach einige Personen gleichzeitig Zugriff auf die Inhalte mehrerer Domänen benötigen. Zum Beispiel:
- Datenanalysten, die den Dateninhalt für mehrere verschiedene Bereiche, Regionen usw. auswerten.
- Die gemeinsam genutzten Dienste des Testteams dienen verschiedenen Entwicklungsteams.
- Meldende Benutzer, die eine Dashboard-Analyse über verschiedene Länder innerhalb derselben Region aufbauen müssen.
Wie Sie sich vorstellen können, kann diese Liste noch einmal so weit wachsen, wie Sie sich vorstellen können, und die Anforderungen von Organisationen können alle Arten von Anwendungsfällen generieren.
Je komplexer diese Liste wird, desto komplexer wird die Orchestrierung der Zugriffsrechte, um all diesen verschiedenen Gruppen unterschiedliche Zugriffsrechte auf verschiedene S3-Buckets in der Organisation zu gewähren. Es sind zusätzliche Tools erforderlich, und möglicherweise muss sogar eine dedizierte Ressource (Administrator) die Zugriffsrechtelisten pflegen und sie aktualisieren, wenn eine Änderung angefordert wird (was sehr oft der Fall sein wird, insbesondere wenn die Organisation groß ist).
Wie kann man also dasselbe auf organisiertere und automatisiertere Weise erreichen?
Einführung von Tags für Buckets
Wenn der Bucket-per-Domain-Ansatz nicht funktioniert, wird jede andere Lösung mit gemeinsam genutzten Buckets für mehr Benutzergruppen enden. In solchen Fällen ist es notwendig, die gesamte Logik der Zuweisung von Zugriffsrechten in einem Bereich aufzubauen, der leicht zu ändern oder dynamisch zu aktualisieren ist.
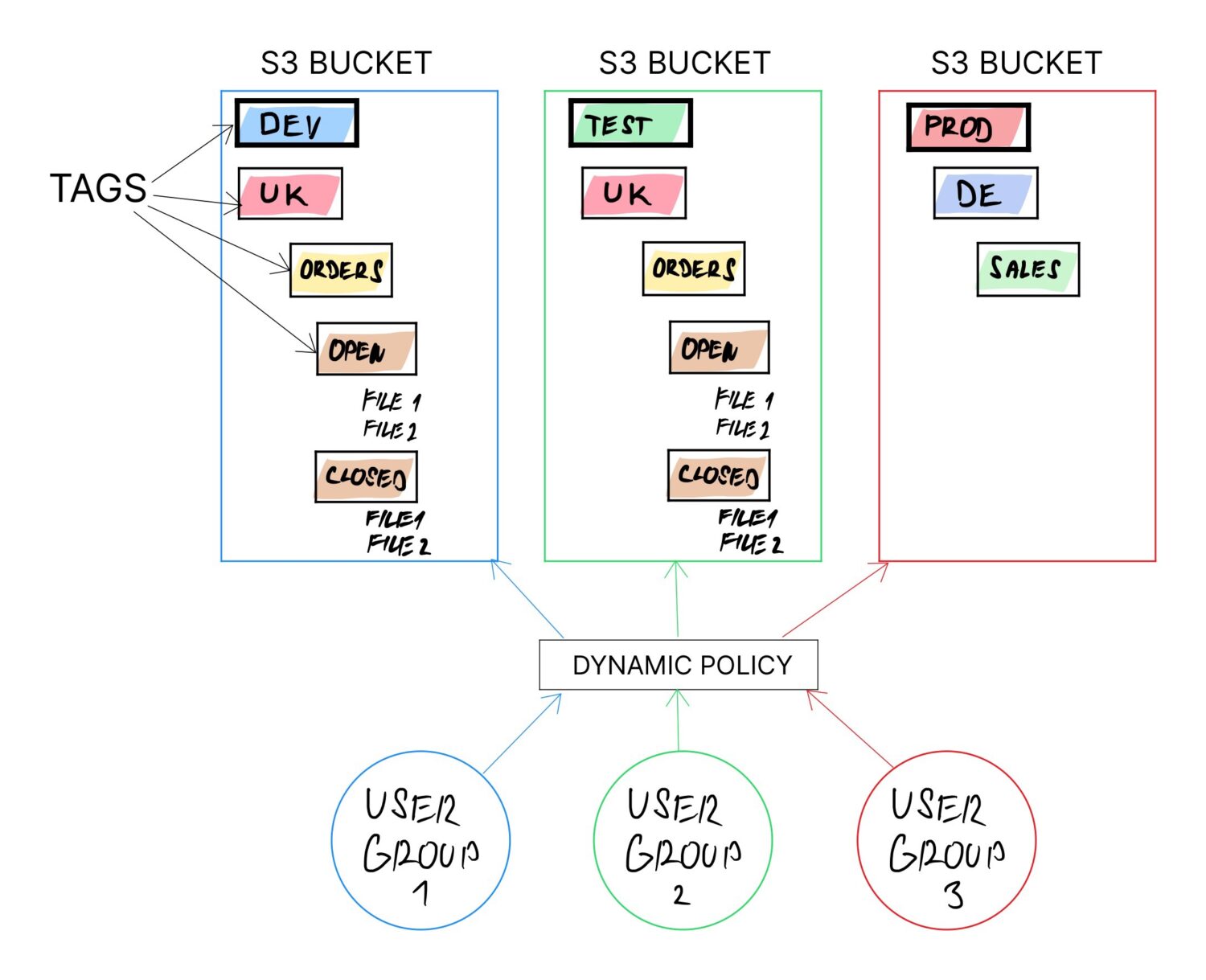
Eine Möglichkeit, dies zu erreichen, ist die Verwendung von Tags für die S3-Buckets. Die Verwendung der Tags wird auf jeden Fall empfohlen (schon allein um eine einfachere Abrechnungskategorisierung zu ermöglichen). Das Tag kann jedoch jederzeit in der Zukunft für jeden beliebigen Bucket geändert werden.
Wenn die gesamte Logik basierend auf den Bucket-Tags aufgebaut wird und der Rest dahinter von den Tag-Werten abhängige Konfiguration ist, wird die dynamische Eigenschaft sichergestellt, da man den Zweck des Buckets einfach durch Aktualisieren der Tag-Werte neu definieren kann.
Welche Art von Tags müssen verwendet werden, damit dies funktioniert?
Dies hängt von Ihrem konkreten Anwendungsfall ab. Zum Beispiel:
- Es kann erforderlich sein, Buckets pro Umgebungstyp zu trennen. In diesem Fall sollte einer der Tag-Namen so etwas wie „ENV“ und mit möglichen Werten „DEV“, „TEST“, „PROD“ usw. sein.
- Vielleicht möchten Sie das Team nach Ländern trennen. In diesem Fall ist ein anderes Tag „COUNTRY“ und hat einen Wert für einen Ländernamen.
- Oder Sie möchten die Benutzer basierend auf der funktionalen Abteilung, zu der sie gehören, wie Business Analysts, Data Warehouse-Benutzer, Data Scientists usw., trennen. Erstellen Sie also ein Tag mit dem Namen „USER_TYPE“ und dem entsprechenden Wert.
- Eine andere Möglichkeit könnte sein, dass Sie für bestimmte Benutzergruppen explizit eine feste Ordnerstruktur definieren möchten, die diese verwenden müssen (um nicht ein eigenes Ordner-Wirrwarr zu erstellen und sich dort mit der Zeit zu verirren). Sie können dies wieder mit Tags tun, in denen Sie mehrere Arbeitsverzeichnisse angeben können, z. B. „Daten/Import“, „Daten/Verarbeitet“, „Daten/Fehler“ usw.
Idealerweise möchten Sie die Tags so definieren, dass sie logisch kombiniert werden können und sie eine ganze Ordnerstruktur auf dem Bucket bilden.

Sie können beispielsweise die folgenden Tags aus den obigen Beispielen kombinieren, um eine dedizierte Ordnerstruktur für verschiedene Arten von Benutzern aus verschiedenen Ländern mit vordefinierten Importordnern zu erstellen, die sie voraussichtlich verwenden werden:
- /<ENV>/<USER_TYPE>/<LAND>/<UPLOAD>
Durch einfaches Ändern des <ENV>-Werts können Sie den Zweck des Tags neu definieren (ob es der Testumgebung Ecosystem, dev, prod usw. zugewiesen werden soll).
Dies ermöglicht die Verwendung desselben Buckets für viele verschiedene Benutzer. Buckets unterstützen Ordner nicht explizit, aber sie unterstützen „Labels“. Diese Labels funktionieren letztendlich wie Unterordner, da die Benutzer eine Reihe von Labels durchlaufen müssen, um zu ihren Daten zu gelangen (genau wie sie es mit Unterordnern tun würden).
Erstellen Sie dynamische Richtlinien und ordnen Sie Bucket-Tags darin zu
Nachdem die Tags in einer verwendbaren Form definiert wurden, besteht der nächste Schritt darin, S3-Bucket-Richtlinien zu erstellen, die die Tags verwenden würden.
Wenn die Richtlinien die Tag-Namen verwenden, erstellen Sie etwas, das als „dynamische Richtlinien“ bezeichnet wird. Dies bedeutet im Grunde, dass sich Ihre Richtlinie für Buckets mit unterschiedlichen Tag-Werten, auf die sich die Richtlinie in Form oder Platzhaltern bezieht, anders verhält.
Dieser Schritt beinhaltet natürlich eine benutzerdefinierte Codierung der dynamischen Richtlinien, aber Sie können diesen Schritt mit dem Amazon AWS-Richtlinien-Editor-Tool vereinfachen, das Sie durch den Prozess führt.
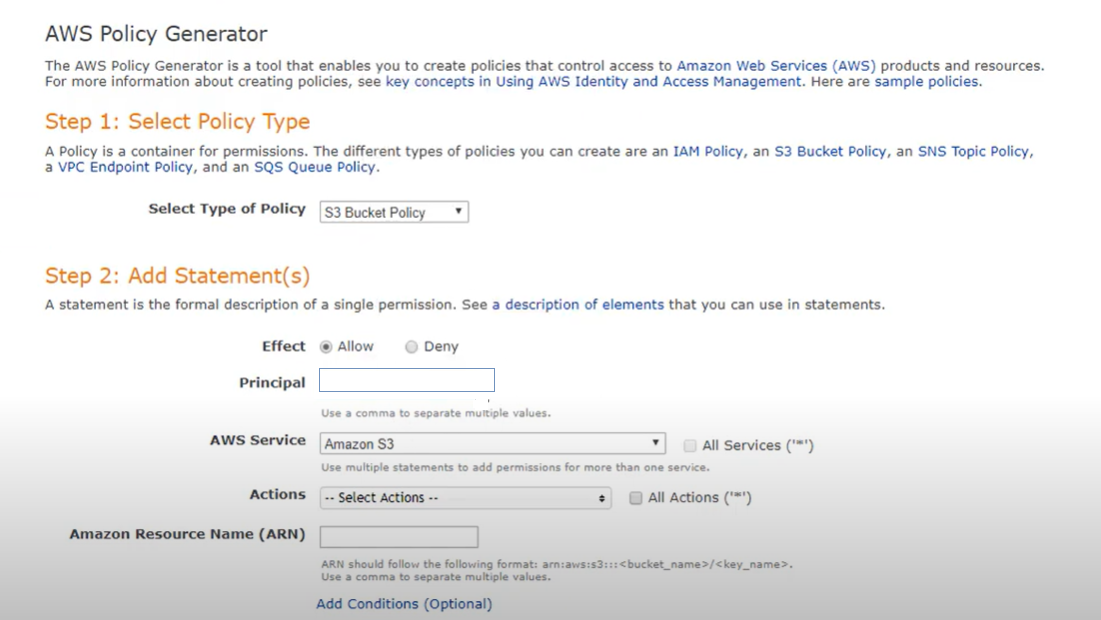
In der Richtlinie selbst möchten Sie konkrete Zugriffsrechte codieren, die auf den Bucket angewendet werden sollen, sowie die Zugriffsebene dieser Rechte (Lesen, Schreiben). Die Logik liest die Tags auf den Buckets und baut die Ordnerstruktur auf dem Bucket auf (Erstellung von Labels basierend auf den Tags). Anhand der konkreten Werte der Tags werden die Unterordner erstellt und entlang der Linie die erforderlichen Zugriffsrechte vergeben.
Das Schöne an einer solchen dynamischen Richtlinie ist, dass Sie nur eine dynamische Richtlinie erstellen und dann dieselbe dynamische Richtlinie vielen Buckets zuweisen können. Diese Richtlinie verhält sich für Buckets mit unterschiedlichen Tag-Werten anders, entspricht jedoch immer Ihren Erwartungen an einen Bucket mit solchen Tag-Werten.
Es ist eine wirklich effektive Möglichkeit, die Zuweisung von Zugriffsrechten auf organisierte, zentralisierte Weise für eine große Anzahl von Buckets zu verwalten, wobei erwartet wird, dass jeder Bucket einigen im Voraus vereinbarten Vorlagenstrukturen folgt und von Ihren Benutzern innerhalb verwendet wird die ganze Organisation.
Automatisieren Sie das Onboarding neuer Entitäten
Nachdem Sie dynamische Richtlinien definiert und sie den vorhandenen Buckets zugewiesen haben, können die Benutzer damit beginnen, dieselben Buckets zu verwenden, ohne das Risiko einzugehen, dass Benutzer aus verschiedenen Gruppen nicht auf Inhalte zugreifen (die im selben Bucket gespeichert sind), die sich in einer Ordnerstruktur befinden, in der sie keine haben Zugriff.
Außerdem wird es für einige Benutzergruppen mit breiterem Zugriff einfach sein, auf die Daten zuzugreifen, da sie alle im selben Bucket gespeichert werden.
Der letzte Schritt besteht darin, das Onboarding neuer Benutzer, neuer Buckets und sogar neuer Tags so einfach wie möglich zu gestalten. Dies führte zu einer weiteren benutzerdefinierten Codierung, die jedoch nicht übermäßig komplex sein muss, vorausgesetzt, Ihr Onboarding-Prozess hat einige sehr klare Regeln, die mit einfacher, unkomplizierter Algorithmuslogik gekapselt werden können (zumindest können Sie auf diese Weise beweisen, dass Ihre Prozess hat eine gewisse Logik und wird nicht übermäßig chaotisch durchgeführt).
Dies kann so einfach sein wie das Erstellen eines Skripts, das mit einem AWS CLI-Befehl ausführbar ist, mit Parametern, die für das erfolgreiche Onboarding einer neuen Entität in die Plattform erforderlich sind. Es kann sogar eine Reihe von CLI-Skripten sein, die in einer bestimmten Reihenfolge ausführbar sind, wie zum Beispiel:
- create_new_bucket(<ENV>,<ENV_VALUE>,<LAND>,<COUNTRY_VALUE>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<Benutzertyp>,<Land>,<Umgebung>)
- usw.
Du verstehst es.
Ein Profi-Tipp
Wenn Sie möchten, gibt es einen Profi-Tipp, der einfach auf die oben genannten angewendet werden kann.
Die dynamischen Richtlinien können nicht nur für die Zuweisung von Zugriffsrechten für Ordnerstandorte, sondern auch für die automatische Zuweisung von Dienstrechten für die Buckets und Benutzergruppen genutzt werden!
Es müsste lediglich die Liste der Tags auf den Buckets erweitert und dann dynamische Richtlinienzugriffsrechte hinzugefügt werden, um bestimmte Dienste für konkrete Benutzergruppen zu nutzen.
Beispielsweise kann es eine Gruppe von Benutzern geben, die ebenfalls Zugriff auf den bestimmten Datenbank-Cluster-Server benötigen. Dies kann zweifellos durch dynamische Richtlinien erreicht werden, die Bucket-Tasks nutzen, insbesondere wenn die Zugriffe auf die Dienste von einem rollenbasierten Ansatz gesteuert werden. Fügen Sie dem dynamischen Richtliniencode einfach einen Teil hinzu, der Tags bezüglich der Datenbank-Cluster-Spezifikation verarbeitet, und weisen Sie die Richtlinienzugriffsrechte direkt diesem bestimmten DB-Cluster und dieser Benutzergruppe zu.
Auf diese Weise ist das Onboarding einer neuen Benutzergruppe nur durch diese einzige dynamische Richtlinie ausführbar. Da sie dynamisch ist, kann dieselbe Richtlinie außerdem für das Onboarding vieler verschiedener Benutzergruppen wiederverwendet werden (es wird erwartet, dass sie derselben Vorlage folgen, aber nicht unbedingt denselben Diensten).
Sie können sich auch diese AWS S3-Befehle zum Verwalten von Buckets und Daten ansehen.