
كيفية مزامنة Oracle Database المحلية الخاصة بك مع AWS
نشرت: 2023-01-11عند مشاهدة تطوير برامج الشركة من الصف الأول لمدة عقدين من الزمن ، فإن الاتجاه الذي لا يمكن إنكاره في السنوات القليلة الماضية واضح - نقل قواعد البيانات إلى السحابة.
لقد شاركت بالفعل في عدد قليل من مشاريع الترحيل ، حيث كان الهدف هو جلب قاعدة البيانات المحلية الحالية إلى قاعدة بيانات Amazon Web Services (AWS) Cloud. بينما من خلال مواد توثيق AWS ، ستتعلم مدى سهولة ذلك ، وأنا هنا لأخبرك أن تنفيذ مثل هذه الخطة ليس دائمًا سهلًا ، وهناك حالات يمكن أن تفشل فيها.

في هذا المنشور ، سأغطي تجربة العالم الحقيقي للحالة التالية:
- المصدر : بينما من الناحية النظرية ، لا يهم حقًا ما هو مصدرك (يمكنك استخدام نهج مشابه جدًا لغالبية قواعد البيانات الأكثر شيوعًا) ، كانت Oracle هي نظام قاعدة البيانات المفضل في شركات الشركات الكبرى لسنوات عديدة ، و هذا حيث سيكون تركيزي.
- الهدف : لا يوجد سبب للتحديد في هذا الجانب. يمكنك اختيار أي قاعدة بيانات مستهدفة في AWS ، وسيظل النهج مناسبًا.
- الوضع : يمكنك الحصول على تحديث كامل أو تحديث تزايدي. تحميل بيانات الدُفعات (حالات المصدر والهدف تتأخر) أو (بالقرب) من تحميل البيانات في الوقت الفعلي. سيتم التطرق إلى كلاهما هنا.
- التكرار : قد ترغب في ترحيل لمرة واحدة متبوعًا بتبديل كامل إلى السحابة أو تتطلب فترة انتقالية وتحديث البيانات على كلا الجانبين في وقت واحد ، مما يعني تطوير المزامنة اليومية بين داخل الشركة و AWS. الأول أبسط وأكثر منطقية ، لكن الأخير مطلوب في كثير من الأحيان ولديه نقاط فاصل أكبر بكثير. سأغطي كلاهما هنا.
وصف المشكلة
المتطلبات غالبًا ما تكون بسيطة:
نريد أن نبدأ في تطوير الخدمات داخل AWS ، لذا يرجى نسخ جميع بياناتنا إلى قاعدة بيانات "ABC". بسرعة وبساطة. نحن بحاجة إلى استخدام البيانات الموجودة داخل AWS الآن. لاحقًا ، سنكتشف أجزاء تصميمات قاعدة البيانات التي يجب تغييرها لتتناسب مع أنشطتنا.
قبل المضي قدمًا ، هناك شيء يجب مراعاته:
- لا تقفز إلى فكرة "نسخ ما لدينا والتعامل معه لاحقًا" بسرعة كبيرة. أعني ، نعم ، هذا هو أسهل ما يمكنك القيام به ، وسيتم تنفيذه بسرعة ، ولكن هذا لديه القدرة على إنشاء مثل هذه المشكلة المعمارية الأساسية التي سيكون من المستحيل إصلاحها لاحقًا دون إعادة هيكلة جادة لغالبية النظام الأساسي السحابي الجديد . فقط تخيل أن النظام البيئي السحابي مختلف تمامًا عن النظام الداخلي. سيتم تقديم العديد من الخدمات الجديدة بمرور الوقت. بطبيعة الحال ، سيبدأ الناس في استخدام نفس الشيء بشكل مختلف تمامًا. تكاد لا تكون فكرة جيدة أن تقوم بتكرار الحالة المحلية في السحابة بطريقة 1: 1. قد يكون في حالتك الخاصة ، ولكن تأكد من إعادة التحقق من ذلك.
- اسأل الشرط ببعض الشكوك ذات المعنى مثل:
- من سيكون المستخدم النموذجي الذي يستخدم النظام الأساسي الجديد؟ أثناء وجوده في مكان العمل ، يمكن أن يكون مستخدمًا تجاريًا للمعاملات ؛ في السحابة ، يمكن أن يكون عالم بيانات أو محلل مستودع بيانات ، أو قد يكون المستخدم الرئيسي للبيانات خدمة (على سبيل المثال ، Databricks ، Glue ، نماذج التعلم الآلي ، إلخ).
- هل من المتوقع أن تستمر الوظائف اليومية العادية حتى بعد الانتقال إلى السحابة؟ إذا لم يكن الأمر كذلك ، فكيف يتوقع أن يتغيروا؟
- هل تخطط لنمو كبير للبيانات بمرور الوقت؟ على الأرجح ، الإجابة هي نعم ، لأن هذا غالبًا هو السبب الوحيد الأكثر أهمية للهجرة إلى السحابة. يجب أن يكون نموذج البيانات الجديد جاهزًا لذلك.
- توقع أن يفكر المستخدم النهائي في بعض الاستفسارات العامة والمتوقعة التي ستتلقاها قاعدة البيانات الجديدة من المستخدمين. سيحدد هذا مدى تغيير نموذج البيانات الحالي ليظل وثيق الصلة بالأداء.
إعداد الهجرة
بمجرد اختيار قاعدة البيانات المستهدفة ومناقشة نموذج البيانات بشكل مرض ، فإن الخطوة التالية هي التعرف على أداة تحويل مخطط AWS. هناك العديد من المجالات التي يمكن أن تخدم فيها هذه الأداة:
- تحليل واستخراج نموذج البيانات المصدر. ستقرأ SCT ما هو موجود في قاعدة البيانات المحلية الحالية وستقوم بإنشاء نموذج بيانات مصدر للبدء به.
- اقترح هيكل نموذج بيانات مستهدف على أساس قاعدة البيانات الهدف.
- قم بإنشاء برامج نصية لنشر قاعدة البيانات الهدف لتثبيت نموذج البيانات الهدف (بناءً على ما اكتشفته الأداة من قاعدة البيانات المصدر). سيؤدي ذلك إلى إنشاء برامج نصية للنشر ، وبعد تنفيذها ، ستكون قاعدة البيانات في السحابة جاهزة لتحميلات البيانات من قاعدة البيانات المحلية.
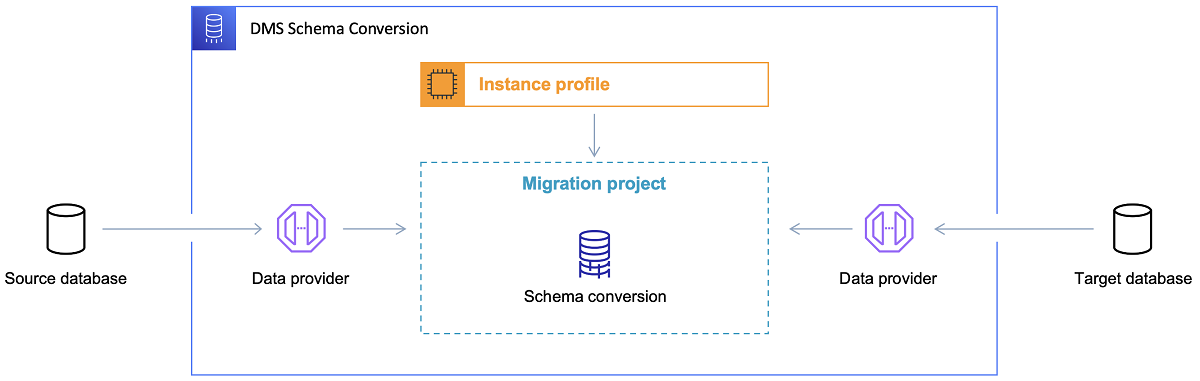
يوجد الآن بعض النصائح لاستخدام أداة تحويل المخطط.
أولاً ، يجب ألا يكون استخدام الإخراج مباشرة تقريبًا هو الحال. سأعتبرها أشبه بنتائج مرجعية ، حيث يتعين عليك إجراء تعديلاتك بناءً على فهمك والغرض من البيانات والطريقة التي سيتم بها استخدام البيانات في السحابة.
ثانيًا ، في وقت سابق ، ربما تم اختيار الجداول من قبل المستخدمين الذين يتوقعون نتائج قصيرة سريعة حول بعض كيانات مجال البيانات الملموسة. ولكن الآن ، قد يتم اختيار البيانات لأغراض تحليلية. على سبيل المثال ، فهارس قاعدة البيانات التي كانت تعمل سابقًا في قاعدة البيانات المحلية ستكون الآن عديمة الفائدة وبالتأكيد لن تعمل على تحسين أداء نظام قاعدة البيانات المرتبط بهذا الاستخدام الجديد. وبالمثل ، قد ترغب في تقسيم البيانات بشكل مختلف على النظام الهدف ، كما كان من قبل في النظام المصدر.
أيضًا ، قد يكون من الجيد التفكير في إجراء بعض تحويلات البيانات أثناء عملية الترحيل ، وهو ما يعني أساسًا تغيير نموذج البيانات الهدف لبعض الجداول (بحيث لا يتم نسخ 1: 1 بعد الآن). في وقت لاحق ، ستحتاج قواعد التحويل إلى أن يتم تنفيذها في أداة الترحيل.
تكوين أداة الترحيل
إذا كانت قواعد البيانات المصدر والهدف من نفس النوع (على سبيل المثال ، Oracle داخل الشركة مقابل Oracle في AWS و PostgreSQL مقابل Aurora Postgresql وما إلى ذلك) ، فمن الأفضل استخدام أداة ترحيل مخصصة تدعمها قاعدة البيانات الملموسة أصلاً ( على سبيل المثال ، صادرات وواردات مضخة البيانات ، Oracle Goldengate ، إلخ).
ومع ذلك ، في معظم الحالات ، لن تكون قاعدة البيانات المصدر والهدف متوافقة ، ومن ثم ستكون الأداة الواضحة المفضلة هي خدمة AWS Database Migration Service.
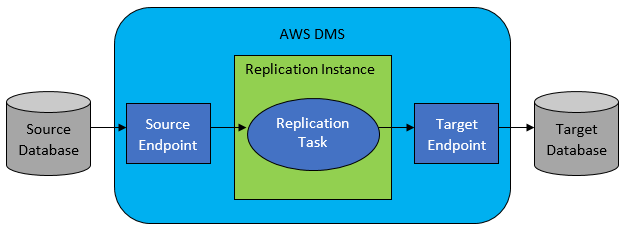
يسمح AWS DMS بشكل أساسي بتكوين قائمة بالمهام على مستوى الجدول ، والتي ستحدد:
- ما هو المصدر الدقيق DB والجدول للاتصال به؟
- بيان المواصفات التي سيتم استخدامها للحصول على البيانات للجدول الهدف.
- أدوات التحويل (إن وجدت) ، التي تحدد كيفية تعيين بيانات المصدر في بيانات الجدول الهدف (إن لم يكن 1: 1).
- ما هي قاعدة البيانات والجدول الهدف الدقيق لتحميل البيانات فيه؟
يتم تكوين مهام DMS بتنسيق سهل الاستخدام مثل JSON.
الآن في أبسط سيناريو ، كل ما عليك فعله هو تشغيل البرامج النصية للنشر على قاعدة البيانات الهدف وبدء مهمة DMS. ولكن هناك ما هو أكثر من ذلك بكثير.

ترحيل البيانات الكاملة لمرة واحدة

أسهل حالة يتم تنفيذها هي عندما يكون الطلب هو نقل قاعدة البيانات بأكملها مرة واحدة إلى قاعدة البيانات السحابية الهدف. بعد ذلك ، سيبدو كل ما هو ضروري في الأساس كما يلي:
- حدد مهمة DMS لكل جدول مصدر.
- تأكد من تحديد تكوين وظائف DMS بشكل صحيح. وهذا يعني إعداد التوازي المعقول ، ومتغيرات التخزين المؤقت ، وتكوين خادم DMS ، وتحجيم مجموعة DMS ، وما إلى ذلك. وعادة ما تكون هذه هي المرحلة الأكثر استهلاكا للوقت لأنها تتطلب اختبارًا مكثفًا وضبطًا دقيقًا لحالة التكوين الأمثل.
- تأكد من إنشاء كل جدول هدف (فارغ) في قاعدة البيانات الهدف في هيكل الجدول المتوقع.
- جدولة نافذة زمنية سيتم خلالها ترحيل البيانات. قبل ذلك ، من الواضح ، تأكد (من خلال إجراء اختبارات الأداء) أن النافذة الزمنية ستكون كافية لإكمال الترحيل. أثناء الترحيل نفسه ، قد يتم تقييد قاعدة البيانات المصدر من وجهة نظر الأداء. أيضًا ، من المتوقع ألا تتغير قاعدة البيانات المصدر أثناء وقت تشغيل الترحيل. وإلا ، فقد تختلف البيانات التي تم ترحيلها عن تلك المخزنة في قاعدة البيانات المصدر بمجرد إتمام الترحيل.
إذا تم تكوين DMS بشكل جيد ، فلن يحدث أي شيء سيء في هذا السيناريو. سيتم انتقاء كل جدول مصدر فردي ونسخه في قاعدة بيانات AWS المستهدفة. ستكون المخاوف الوحيدة هي أداء النشاط والتأكد من أن التحجيم صحيح في كل خطوة حتى لا يفشل بسبب مساحة التخزين غير الكافية.
المزامنة اليومية المتزايدة

هذا هو المكان الذي تبدأ فيه الأمور بالتعقيد. أعني ، إذا كان العالم مثاليًا ، فمن المحتمل أن يعمل بشكل جيد طوال الوقت. لكن العالم ليس مثاليًا أبدًا.
يمكن تكوين DMS للعمل في وضعين:
- تحميل كامل - الوضع الافتراضي الموصوف والمستخدم أعلاه. تبدأ مهام DMS إما عند بدء تشغيلها أو عند جدولتها للبدء. بمجرد الانتهاء ، تتم مهام DMS.
- تغيير التقاط البيانات (CDC) - في هذا الوضع ، تعمل مهمة DMS بشكل مستمر. تفحص DMS قاعدة البيانات المصدر لإجراء تغيير على مستوى الجدول. إذا حدث التغيير ، فسيحاول على الفور تكرار التغيير في قاعدة البيانات الهدف بناءً على التكوين داخل مهمة DMS المتعلقة بالجدول الذي تم تغييره.
عند الذهاب إلى مركز السيطرة على الأمراض ، تحتاج إلى اتخاذ خيار آخر - أي كيف سيقوم مركز السيطرة على الأمراض باستخراج تغييرات دلتا من قاعدة البيانات المصدر.
# 1. قارئ سجلات إعادة أوراكل
أحد الخيارات هو اختيار قارئ سجلات إعادة قاعدة البيانات الأصلي من Oracle ، والذي يمكن لـ CDC استخدامه للحصول على البيانات المتغيرة ، وبناءً على أحدث التغييرات ، قم بتكرار نفس التغييرات على قاعدة البيانات الهدف.
على الرغم من أن هذا قد يبدو خيارًا واضحًا في حالة التعامل مع Oracle كمصدر ، إلا أن هناك مشكلة: يستخدم قارئ سجلات إعادة Oracle مجموعة أوراكل المصدر وبالتالي يؤثر بشكل مباشر على جميع الأنشطة الأخرى التي تعمل في قاعدة البيانات (فهو في الواقع ينشئ جلسات نشطة بشكل مباشر في قاعدة البيانات).
كلما زاد عدد مهام DMS التي قمت بتكوينها (أو زاد عدد مجموعات DMS بالتوازي) ، كلما احتجت إلى زيادة حجم مجموعة Oracle - بشكل أساسي ، اضبط القياس الرأسي لمجموعة قاعدة بيانات Oracle الأساسية. سيؤثر هذا بالتأكيد على التكاليف الإجمالية للحل ، بل وأكثر من ذلك إذا كانت المزامنة اليومية على وشك البقاء مع المشروع لفترة طويلة من الزمن.
# 2. AWS DMS Log Miner
على عكس الخيار أعلاه ، يعد هذا حل AWS أصليًا لنفس المشكلة. في هذه الحالة ، لا يؤثر DMS على Oracle DB المصدر. بدلاً من ذلك ، يقوم بنسخ سجلات إعادة Oracle إلى مجموعة DMS ويقوم بكل عمليات المعالجة هناك. بينما يحفظ موارد Oracle ، فهو الحل الأبطأ ، حيث يتم تضمين المزيد من العمليات. وأيضًا ، كما يمكن للمرء أن يفترض بسهولة ، من المحتمل أن يكون القارئ المخصص لسجلات إعادة Oracle أبطأ في وظيفته كقارئ أصلي من Oracle.
اعتمادًا على حجم قاعدة البيانات المصدر وعدد التغييرات اليومية هناك ، في أفضل سيناريو ، قد ينتهي بك الأمر بمزامنة متزايدة في الوقت الفعلي تقريبًا للبيانات من قاعدة بيانات Oracle المحلية في قاعدة بيانات AWS السحابية.
في أي سيناريوهات أخرى ، لن تكون مزامنة في الوقت الفعلي تقريبًا ، ولكن يمكنك محاولة الاقتراب قدر الإمكان من التأخير المقبول (بين المصدر والهدف) عن طريق ضبط تكوين أداء مجموعات المصدر والهدف والتوازي أو التجربة مع مقدار مهام DMS وتوزيعها بين مثيلات CDC.
وقد ترغب في معرفة تغييرات جدول المصدر التي يدعمها مركز السيطرة على الأمراض (مثل إضافة عمود ، على سبيل المثال) لأنه لا يتم دعم جميع التغييرات الممكنة. في بعض الحالات ، تكون الطريقة الوحيدة هي تغيير الجدول الهدف يدويًا وإعادة تشغيل مهمة CDC من البداية (فقدان جميع البيانات الموجودة في قاعدة البيانات الهدف على طول الطريق).
عندما تسوء الأمور ، لا يهم ماذا

لقد تعلمت هذا بالطريقة الصعبة ، ولكن هناك سيناريو واحد محدد مرتبط بـ DMS حيث يصعب تحقيق وعد النسخ اليومي.
يمكن لـ DMS معالجة سجلات الإعادة فقط ببعض السرعة المحددة. لا يهم ما إذا كان هناك المزيد من حالات DMS التي تنفذ مهامك. ومع ذلك ، فإن كل مثيل DMS يقرأ سجلات الإعادة فقط بسرعة محددة واحدة ، ويجب على كل واحد منهم قراءتها بالكامل. حتى أنه لا يهم إذا كنت تستخدم Oracle redo logs أو AWS log miner. كلاهما له هذا الحد.
إذا تضمنت قاعدة البيانات المصدر عددًا كبيرًا من التغييرات في غضون يوم واحد تصبح فيه سجلات إعادة Oracle كبيرة جدًا (مثل 500 جيجابايت + كبيرة) كل يوم ، فلن يعمل مركز السيطرة على الأمراض. لن يكتمل النسخ المتماثل قبل نهاية اليوم. سيؤدي ذلك إلى إحضار بعض الأعمال غير المعالجة إلى اليوم التالي ، حيث تنتظر بالفعل مجموعة جديدة من التغييرات المراد تكرارها. ستزداد كمية البيانات غير المعالجة من يوم لآخر.
في هذه الحالة بالذات ، لم يكن CDC خيارًا (بعد العديد من اختبارات الأداء والمحاولات التي نفذناها). الطريقة الوحيدة لكيفية ضمان تكرار جميع تغييرات دلتا على الأقل من اليوم الحالي في نفس اليوم هي الاقتراب منها على النحو التالي:
- افصل بين الجداول الكبيرة حقًا التي لا يتم استخدامها كثيرًا وقم بتكرارها مرة واحدة فقط في الأسبوع (على سبيل المثال ، خلال عطلات نهاية الأسبوع).
- تكوين النسخ المتماثل للجداول ليست كبيرة ولكن لا تزال كبيرة لتقسيمها بين عدة مهام DMS ؛ تم ترحيل جدول واحد في النهاية من خلال 10 أو أكثر من مهام DMS المنفصلة بالتوازي ، مما يضمن أن تقسيم البيانات بين مهام DMS مميز (الترميز المخصص متضمن هنا) وتنفيذها يوميًا.
- أضف المزيد (حتى 4 في هذه الحالة) مثيلات DMS وقسم مهام DMS بينها بالتساوي ، مما يعني ليس فقط بعدد الجداول ولكن أيضًا بالحجم.
بشكل أساسي ، استخدمنا وضع التحميل الكامل لـ DMS لنسخ البيانات اليومية لأن هذه كانت الطريقة الوحيدة لكيفية تحقيق إكمال نسخ البيانات في نفس اليوم على الأقل.
ليس حلاً مثاليًا ، لكنه لا يزال موجودًا ، وحتى بعد سنوات عديدة ، لا يزال يعمل بنفس الطريقة. لذلك ، ربما لا يكون هذا حلاً سيئًا بعد كل شيء.