
كشف الشذوذ: دليل لمنع اقتحام الشبكة
نشرت: 2023-01-09تعد البيانات جزءًا لا غنى عنه من الشركات والمؤسسات ، ولا تكون ذات قيمة إلا عندما يتم تنظيمها بشكل صحيح وإدارتها بكفاءة.
وفقًا لإحصاءات ، تجد 95٪ من الشركات اليوم مشكلة في إدارة وتنظيم البيانات غير المهيكلة.
هذا هو المكان الذي يأتي فيه التنقيب عن البيانات. إنها عملية اكتشاف وتحليل واستخراج أنماط ذات مغزى ومعلومات قيمة من مجموعات كبيرة من البيانات غير المهيكلة.
تستخدم الشركات البرامج لتحديد الأنماط في مجموعات البيانات الكبيرة لمعرفة المزيد عن عملائها والجمهور المستهدف وتطوير استراتيجيات الأعمال والتسويق لتحسين المبيعات وتقليل التكاليف.
إلى جانب هذه الميزة ، يعد اكتشاف الاحتيال والشذوذ من أهم تطبيقات التنقيب عن البيانات.
تشرح هذه المقالة اكتشاف الشذوذ وتستكشف بشكل أكبر كيف يمكن أن تساعد في منع انتهاكات البيانات واختراقات الشبكة لضمان أمان البيانات.
ما هو كشف الشذوذ وأنواعه؟

بينما يتضمن التنقيب عن البيانات العثور على الأنماط والارتباطات والاتجاهات التي ترتبط ببعضها البعض ، إلا أنها طريقة رائعة للعثور على الحالات الشاذة أو نقاط البيانات الخارجية داخل الشبكة.
الحالات الشاذة في استخراج البيانات هي نقاط بيانات تختلف عن نقاط البيانات الأخرى في مجموعة البيانات وتنحرف عن نمط السلوك الطبيعي لمجموعة البيانات.
يمكن تصنيف الحالات الشاذة إلى أنواع وفئات متميزة ، بما في ذلك:
- التغييرات في الأحداث: تشير إلى التغييرات المفاجئة أو المنهجية من السلوك الطبيعي السابق.
- القيم المتطرفة: أنماط صغيرة شاذة تظهر بطريقة غير منهجية في جمع البيانات. يمكن تصنيفها إلى قيم متطرفة عالمية وسياقية وجماعية.
- الانجرافات: تغيير تدريجي وغير اتجاهي وطويل المدى في مجموعة البيانات.
وبالتالي ، يعد اكتشاف الشذوذ تقنية معالجة بيانات مفيدة للغاية للكشف عن المعاملات الاحتيالية ، والتعامل مع دراسات الحالة مع عدم توازن عالي الدرجة ، واكتشاف الأمراض لبناء نماذج قوية لعلوم البيانات.
على سبيل المثال ، قد ترغب الشركة في تحليل تدفقها النقدي للعثور على معاملات غير طبيعية أو متكررة إلى حساب مصرفي غير معروف للكشف عن الاحتيال وإجراء مزيد من التحقيقات.
فوائد اكتشاف الشذوذ
يساعد اكتشاف سلوك المستخدم الشاذ في تقوية أنظمة الأمان وجعلها أكثر دقة ودقة.
يقوم بتحليل المعلومات المتنوعة التي توفرها أنظمة الأمان وفهمها لتحديد التهديدات والمخاطر المحتملة داخل الشبكة.
فيما يلي مزايا اكتشاف العيوب بالنسبة للشركات:
- الكشف في الوقت الحقيقي عن تهديدات الأمن السيبراني وخروقات البيانات حيث تقوم خوارزميات الذكاء الاصطناعي (AI) بفحص بياناتك باستمرار للعثور على سلوك غير عادي.
- فهو يجعل تتبع الأنشطة والأنماط الشاذة أسرع وأسهل من الكشف اليدوي عن الشذوذ ، مما يقلل من العمل والوقت اللازمين لحل التهديدات.
- يقلل المخاطر التشغيلية من خلال تحديد الأخطاء التشغيلية ، مثل الانخفاض المفاجئ في الأداء ، قبل حدوثها.
- فهو يساعد في القضاء على الأضرار التجارية الكبرى من خلال الكشف عن الحالات الشاذة بسرعة ، لأنه بدون وجود نظام للكشف عن الشذوذ ، يمكن للشركات أن تستغرق أسابيع وشهور لتحديد التهديدات المحتملة.
وبالتالي ، يعد اكتشاف الانحرافات أحد الأصول الضخمة للشركات التي تخزن مجموعات كبيرة من بيانات العملاء والأعمال للعثور على فرص النمو والقضاء على التهديدات الأمنية والاختناقات التشغيلية.
تقنيات كشف الشذوذ
يستخدم اكتشاف العيوب العديد من الإجراءات وخوارزميات التعلم الآلي (ML) لمراقبة البيانات واكتشاف التهديدات.
فيما يلي التقنيات الرئيسية لاكتشاف التشوهات:
# 1. تقنيات التعلم الآلي

تستخدم تقنيات تعلم الآلات خوارزميات ML لتحليل البيانات واكتشاف الحالات الشاذة. تشمل الأنواع المختلفة من خوارزميات التعلم الآلي لاكتشاف العيوب ما يلي:
- خوارزميات التجميع
- خوارزميات التصنيف
- خوارزميات التعلم العميق
وتشتمل تقنيات ML المستخدمة بشكل شائع للكشف عن الشذوذ والتهديدات على آلات ناقلات الدعم (SVMs) ، وتجميع الوسائل k ، وأجهزة التشفير التلقائي.
# 2. تقنيات احصائيه
تستخدم التقنيات الإحصائية النماذج الإحصائية لاكتشاف الأنماط غير العادية (مثل التقلبات غير العادية في أداء جهاز معين) في البيانات لاكتشاف القيم التي تقع خارج نطاق القيم المتوقعة.
تشمل تقنيات اكتشاف الشذوذ الإحصائي الشائعة اختبار الفرضيات ، ونسبة الذكاء ، وعلامة Z ، ودرجة Z المعدلة ، وتقدير الكثافة ، و boxplot ، وتحليل القيمة القصوى ، والمدرج التكراري.
# 3. تقنيات التنقيب عن البيانات

تستخدم تقنيات استخراج البيانات تقنيات تصنيف البيانات والتجميع للعثور على الحالات الشاذة داخل مجموعة البيانات. تتضمن بعض تقنيات شذوذ استخراج البيانات الشائعة التجميع الطيفي ، والتجميع القائم على الكثافة ، وتحليل المكون الرئيسي.
تُستخدم خوارزميات استخراج البيانات العنقودية لتجميع نقاط البيانات المختلفة في مجموعات بناءً على تشابهها في العثور على نقاط البيانات والشذوذ الذي يقع خارج هذه المجموعات.
من ناحية أخرى ، تخصص خوارزميات التصنيف نقاط بيانات لفئات محددة مسبقًا وتكتشف نقاط البيانات التي لا تنتمي إلى هذه الفئات.
# 4. التقنيات المستندة إلى القواعد
كما يوحي الاسم ، تستخدم تقنيات اكتشاف الشذوذ المستندة إلى القواعد مجموعة من القواعد المحددة مسبقًا للعثور على الحالات الشاذة داخل البيانات.
تعد هذه الأساليب أسهل نسبيًا وأبسط في الإعداد ولكنها قد تكون غير مرنة وقد لا تكون فعالة في التكيف مع سلوك وأنماط البيانات المتغيرة.
على سبيل المثال ، يمكنك بسهولة برمجة نظام قائم على القواعد لوضع علامة على المعاملات التي تتجاوز مبلغًا معينًا بالدولار على أنها احتيالية.
# 5. تقنيات المجال
يمكنك استخدام تقنيات خاصة بالمجال لاكتشاف الحالات الشاذة في أنظمة بيانات معينة. ومع ذلك ، في حين أنها قد تكون عالية الكفاءة في اكتشاف الحالات الشاذة في مجالات معينة ، إلا أنها قد تكون أقل كفاءة في مجالات أخرى خارج المجال المحدد.
على سبيل المثال ، باستخدام تقنيات خاصة بالمجال ، يمكنك تصميم تقنيات خاصة للعثور على الحالات الشاذة في المعاملات المالية. لكنها قد لا تعمل للعثور على الانحرافات أو انخفاض الأداء في الجهاز.
الحاجة إلى التعلم الآلي لاكتشاف الشذوذ
التعلم الآلي مهم جدًا ومفيد للغاية في اكتشاف العيوب.
اليوم ، تتعامل معظم الشركات والمؤسسات التي تتطلب الكشف الخارجي مع كميات هائلة من البيانات ، من النصوص ومعلومات العملاء والمعاملات إلى ملفات الوسائط مثل الصور ومحتوى الفيديو.
يعد إجراء جميع المعاملات المصرفية والبيانات التي يتم إنشاؤها كل ثانية يدويًا للحصول على رؤية ذات مغزى أقرب إلى المستحيل. علاوة على ذلك ، تواجه معظم الشركات تحديات وصعوبات كبيرة في هيكلة البيانات غير المهيكلة وترتيب البيانات بطريقة مفيدة لتحليل البيانات.
هذا هو المكان الذي تلعب فيه الأدوات والتقنيات مثل التعلم الآلي (ML) دورًا كبيرًا في جمع وتنظيف وهيكلة وترتيب وتحليل وتخزين كميات ضخمة من البيانات غير المنظمة.
تعالج تقنيات وخوارزميات التعلم الآلي مجموعات البيانات الكبيرة وتوفر المرونة في استخدام التقنيات والخوارزميات المختلفة والجمع بينها لتقديم أفضل النتائج.
إلى جانب ذلك ، يساعد التعلم الآلي أيضًا في تبسيط عمليات اكتشاف الأخطاء في تطبيقات العالم الحقيقي وتوفير الموارد القيمة.
فيما يلي بعض فوائد التعلم الآلي وأهميته في اكتشاف العيوب:
- إنه يجعل اكتشاف التحجيم أسهل عن طريق أتمتة تحديد الأنماط والأشكال الشاذة دون الحاجة إلى برمجة واضحة.
- خوارزميات التعلم الآلي قابلة للتكيف بشكل كبير مع أنماط مجموعات البيانات المتغيرة ، مما يجعلها عالية الكفاءة وقوية مع مرور الوقت.
- يتعامل بسهولة مع مجموعات البيانات الكبيرة والمعقدة ، مما يجعل الكشف عن الأخطاء الشاذة فعالاً على الرغم من تعقيد مجموعة البيانات.
- يضمن التعرف المبكر على الحالات الشاذة واكتشافها من خلال تحديد الحالات الشاذة فور حدوثها ، مما يوفر الوقت والموارد.
- تساعد أنظمة اكتشاف الشذوذ القائمة على التعلم الآلي في تحقيق مستويات أعلى من الدقة في اكتشاف العيوب مقارنة بالطرق التقليدية.
وبالتالي ، يساعد اكتشاف الانحرافات المقترنة بالتعلم الآلي في الكشف المبكر والمبكر عن الحالات الشاذة لمنع التهديدات الأمنية والاختراقات الضارة.

خوارزميات التعلم الآلي لاكتشاف الشذوذ
يمكنك اكتشاف الانحرافات والقيم المتطرفة في البيانات بمساعدة خوارزميات مختلفة لاستخراج البيانات من أجل التصنيف أو التجميع أو تعلم قواعد الارتباط.
عادةً ما يتم تصنيف خوارزميات استخراج البيانات هذه إلى فئتين مختلفتين - خوارزميات التعلم الخاضعة للإشراف وغير الخاضعة للإشراف.
التعلم الخاضع للإشراف
التعلم الخاضع للإشراف هو نوع شائع من خوارزميات التعلم التي تتكون من خوارزميات مثل آلات ناقلات الدعم ، والانحدار اللوجستي والخطي ، والتصنيف متعدد الفئات. يتم تدريب هذا النوع من الخوارزمية على البيانات المصنفة ، مما يعني أن مجموعة بيانات التدريب الخاصة به تتضمن بيانات الإدخال العادية والمخرجات الصحيحة المقابلة أو الأمثلة الشاذة لبناء نموذج تنبؤي.
وبالتالي ، فإن هدفها هو إجراء تنبؤات المخرجات للبيانات غير المرئية والجديدة بناءً على أنماط مجموعة بيانات التدريب. تشمل تطبيقات خوارزميات التعلم الخاضع للإشراف التعرف على الصور والكلام والنمذجة التنبؤية ومعالجة اللغة الطبيعية (NLP).
تعليم غير مشرف عليه
تعليم غير مشرف عليه لم يتم تدريبه على أي بيانات مصنفة. بدلاً من ذلك ، يكتشف العمليات المعقدة وهياكل البيانات الأساسية دون توفير إرشادات خوارزمية التدريب وبدلاً من إجراء تنبؤات محددة.
تشمل تطبيقات خوارزميات التعلم غير الخاضعة للإشراف اكتشاف الشذوذ وتقدير الكثافة وضغط البيانات.
الآن ، دعنا نستكشف بعض خوارزميات اكتشاف الشذوذ القائمة على التعلم الآلي.
عامل خارجي محلي (LOF)
Local Outlier Factor أو LOF هي خوارزمية لاكتشاف الشذوذ تأخذ في الاعتبار كثافة البيانات المحلية لتحديد ما إذا كانت نقطة البيانات هي حالة شاذة.
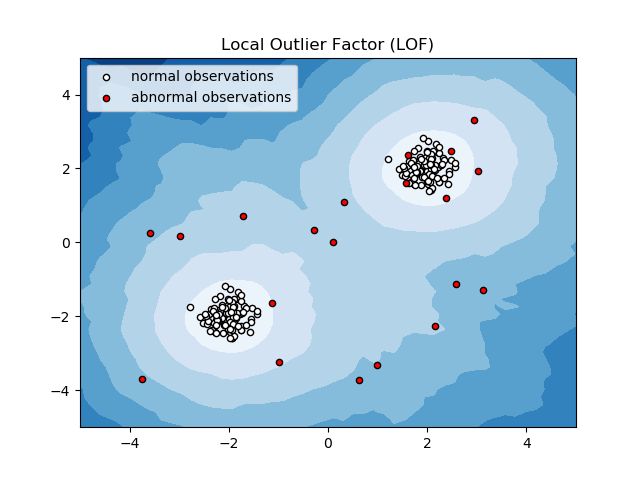
يقارن الكثافة المحلية لعنصر ما بالكثافات المحلية لجيرانه لتحليل مناطق ذات كثافة مماثلة وعناصر ذات كثافة أقل نسبيًا من جيرانها - والتي ليست سوى شذوذ أو قيم متطرفة.
وبالتالي ، بعبارات بسيطة ، تختلف الكثافة المحيطة بعنصر غريب أو شاذ عن الكثافة المحيطة بجيرانه. ومن ثم ، فإن هذه الخوارزمية تسمى أيضًا خوارزمية الكشف عن العوامل الخارجية القائمة على الكثافة.
K- أقرب الجار (K-NN)
K-NN هي أبسط خوارزمية تصنيف وخوارزمية للكشف عن الشذوذ الخاضع للإشراف يسهل تنفيذها ، وتخزن جميع الأمثلة والبيانات المتاحة ، وتصنف الأمثلة الجديدة بناءً على أوجه التشابه في مقاييس المسافة.
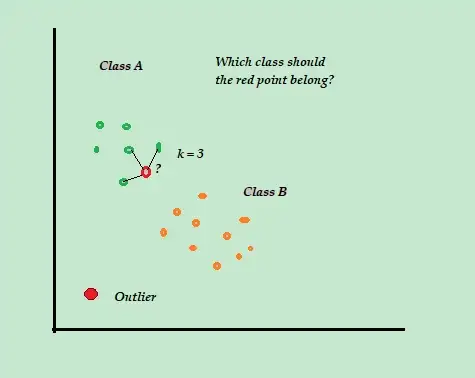
تسمى خوارزمية التصنيف هذه أيضًا باسم المتعلم الكسول لأنها تخزن فقط بيانات التدريب المسمى - دون القيام بأي شيء آخر أثناء عملية التدريب.
عندما تصل نقطة بيانات التدريب الجديدة غير المسماة ، تنظر الخوارزمية إلى أقرب نقاط بيانات التدريب أو أقرب K لاستخدامها لتصنيف وتحديد فئة نقطة البيانات الجديدة غير المسماة.
تستخدم خوارزمية K-NN طرق الكشف التالية لتحديد أقرب نقاط البيانات:
- المسافة الإقليدية لقياس المسافة للبيانات المستمرة.
- مسافة مطرقة لقياس القرب أو "القرب" بين سلسلتي النص لبيانات منفصلة.
على سبيل المثال ، ضع في اعتبارك أن مجموعات بيانات التدريب الخاصة بك تتكون من تسميتين للفصل ، A و B. إذا وصلت نقطة بيانات جديدة ، فإن الخوارزمية ستحسب المسافة بين نقطة البيانات الجديدة وكل نقطة من نقاط البيانات في مجموعة البيانات وتحدد النقاط هذا هو العدد الأقصى الأقرب إلى نقطة البيانات الجديدة.
لذلك ، افترض أن K = 3 ، و 2 من 3 نقاط بيانات تم تصنيفها على أنها A ، ثم تم تصنيف نقطة البيانات الجديدة بالفئة A.
وبالتالي ، تعمل خوارزمية K-NN بشكل أفضل في البيئات الديناميكية مع متطلبات تحديث البيانات المتكررة.
إنها خوارزمية شائعة للكشف عن الشذوذ وتعدين النص مع تطبيقات في التمويل والشركات لاكتشاف المعاملات الاحتيالية وزيادة معدل اكتشاف الاحتيال.
دعم آلة المتجهات (SVM)
آلة ناقلات الدعم هي خوارزمية للكشف عن الشذوذ القائم على التعلم الآلي خاضعة للإشراف تستخدم في الغالب في مشاكل الانحدار والتصنيف.
يستخدم طائرة مفرطة متعددة الأبعاد لفصل البيانات إلى مجموعتين (جديدة وعادية). وبالتالي ، يعمل المستوي الفائق كحد قرار يفصل بين ملاحظات البيانات العادية والبيانات الجديدة.
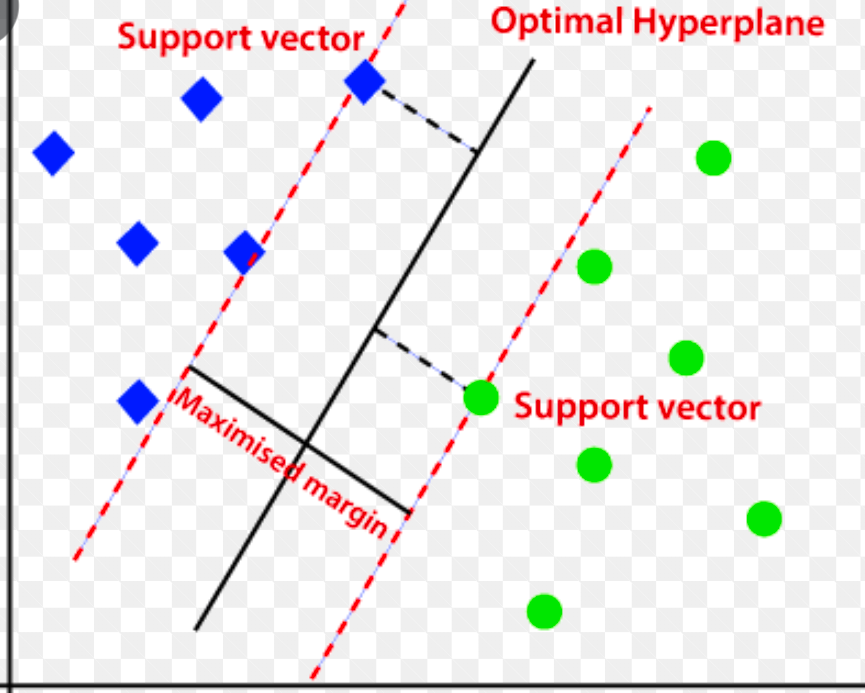
يشار إلى المسافة بين نقطتي البيانات هاتين باسم الهوامش.
نظرًا لأن الهدف هو زيادة المسافة بين النقطتين ، فإن SVM يحدد المستوى الأفضل أو الأمثل مع الحد الأقصى للهامش لضمان أن تكون المسافة بين الفئتين واسعة قدر الإمكان.
فيما يتعلق باكتشاف الشذوذ ، يحسب SVM هامش ملاحظة نقطة البيانات الجديدة من المستوى الفائق لتصنيفها.
إذا تجاوز الهامش الحد المعين ، فإنه يصنف الملاحظة الجديدة على أنها شذوذ. في الوقت نفسه ، إذا كان الهامش أقل من الحد الأدنى ، يتم تصنيف الملاحظة على أنها عادية.
وبالتالي ، فإن خوارزميات SVM ذات كفاءة عالية في التعامل مع مجموعات البيانات عالية الأبعاد والمعقدة.
غابة العزلة
تعد Isolation Forest خوارزمية غير خاضعة للإشراف لاكتشاف الشذوذ في التعلم الآلي تعتمد على مفهوم Random Forest Classifier.
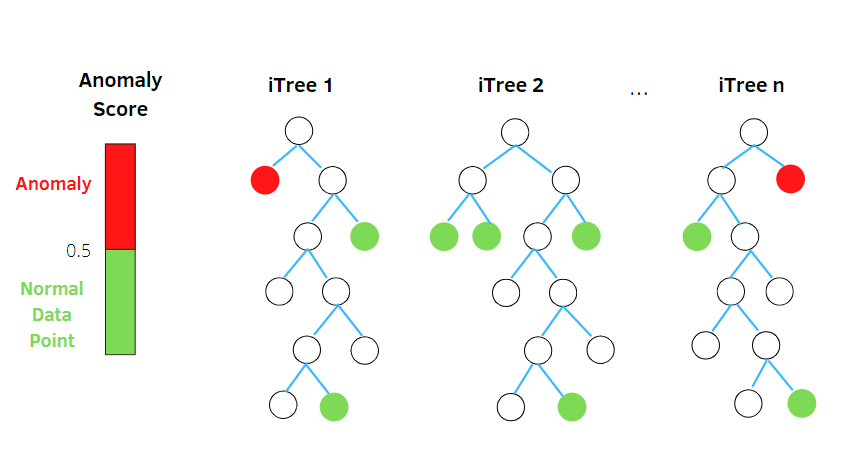
تعالج هذه الخوارزمية البيانات المستندة إلى عينات فرعية بشكل عشوائي في مجموعة البيانات في بنية شجرة بناءً على سمات عشوائية. يقوم ببناء العديد من أشجار القرار لعزل الملاحظات. وتعتبر ملاحظة معينة شذوذًا إذا تم عزلها في عدد أقل من الأشجار بناءً على معدل التلوث.
وهكذا ، بعبارات بسيطة ، تقسم خوارزمية غابة العزل نقاط البيانات إلى أشجار قرار مختلفة - مما يضمن عزل كل ملاحظة عن الأخرى.
تقع الحالات الشاذة عادةً بعيدًا عن مجموعة نقاط البيانات - مما يسهل تحديد الحالات الشاذة مقارنةً بنقاط البيانات العادية.
يمكن لخوارزميات مجموعة العزلة التعامل بسهولة مع البيانات الفئوية والرقمية. ونتيجة لذلك ، فهي أسرع في التدريب وفعالة للغاية في اكتشاف الحالات الشاذة عالية الأبعاد والكبيرة في مجموعات البيانات.
النطاق الربيعي
النطاق الرباعي أو معدل الذكاء يستخدم لقياس التباين الإحصائي أو التشتت الإحصائي للعثور على نقاط شاذة في مجموعات البيانات عن طريق تقسيمها إلى أرباع.
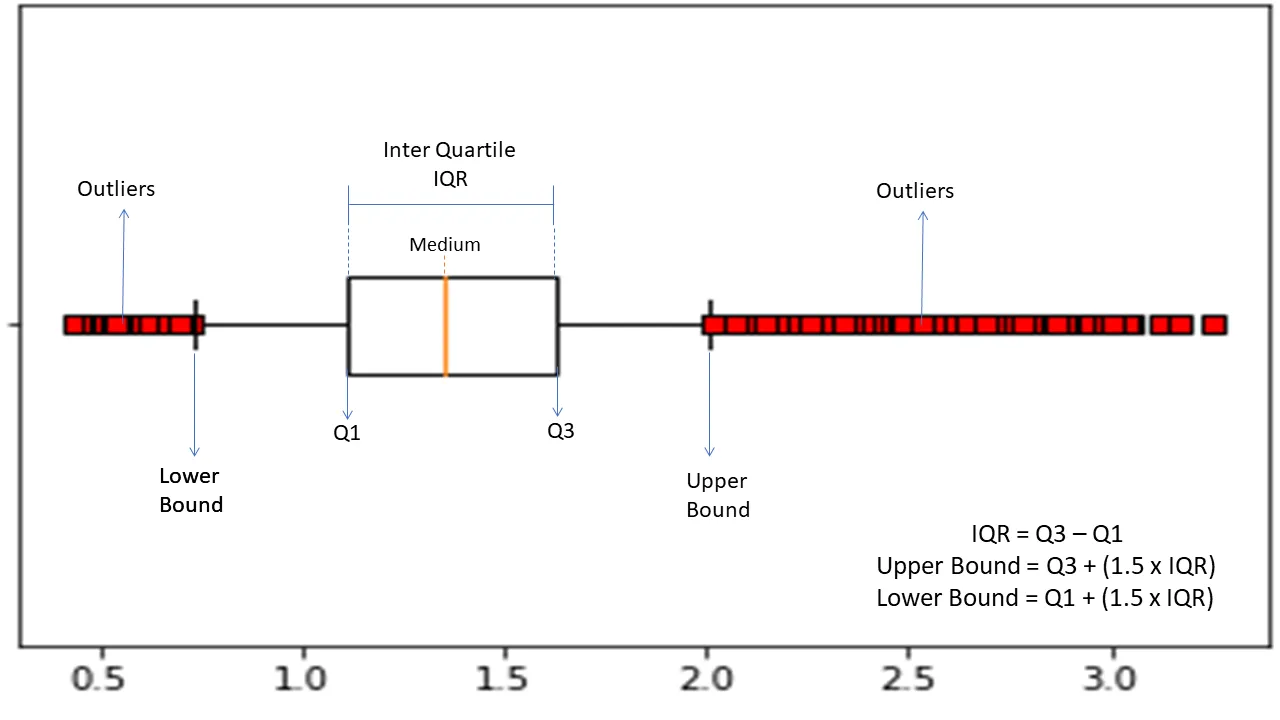
تقوم الخوارزمية بفرز البيانات بترتيب تصاعدي وتقسم المجموعة إلى أربعة أجزاء متساوية. القيم التي تفصل بين هذه الأجزاء هي Q1 و Q2 و Q3 - الربع الأول والثاني والثالث.
فيما يلي التوزيع المئوي لهذه الشرائح الربعية:
- تشير Q1 إلى النسبة المئوية الخامسة والعشرين من البيانات.
- تشير Q2 إلى النسبة المئوية الخمسين للبيانات.
- تشير Q3 إلى النسبة المئوية الخامسة والسبعين للبيانات.
معدل الذكاء هو الفرق بين مجموعتي البيانات المئوية الثالثة (75) والأولى (25) ، والتي تمثل 50٪ من البيانات.
يتطلب استخدام IQR لاكتشاف الانحرافات حساب معدل الذكاء لمجموعة البيانات الخاصة بك وتحديد الحدود الدنيا والعليا للبيانات للعثور على الحالات الشاذة.
- الحد الأدنى: Q1 - 1.5 * IQR
- الحد العلوي: Q3 + 1.5 * IQR
عادة ، تعتبر الملاحظات التي تقع خارج هذه الحدود شذوذ.
تعد خوارزمية IQR فعالة لمجموعات البيانات ذات البيانات الموزعة بشكل غير متساو وحيث يكون التوزيع غير مفهوم جيدًا.
الكلمات الأخيرة
لا يبدو أن مخاطر الأمن السيبراني وخروقات البيانات ستكبح في السنوات القادمة - ومن المتوقع أن تنمو هذه الصناعة المحفوفة بالمخاطر أكثر في عام 2023 ، ومن المتوقع أن تتضاعف الهجمات الإلكترونية لإنترنت الأشياء وحدها بحلول عام 2025.
علاوة على ذلك ، ستكلف الجرائم الإلكترونية الشركات والمنظمات العالمية ما يقدر بـ 10.3 تريليون دولار سنويًا بحلول عام 2025.
هذا هو السبب في أن الحاجة إلى تقنيات كشف الشذوذ أصبحت أكثر انتشارًا وضرورية اليوم للكشف عن الاحتيال ومنع اختراق الشبكة.
ستساعدك هذه المقالة على فهم ماهية الحالات الشاذة في التنقيب عن البيانات ، وأنواع مختلفة من الحالات الشاذة ، وطرق منع اختراق الشبكة باستخدام تقنيات اكتشاف الشذوذ المستندة إلى ML.
بعد ذلك ، يمكنك استكشاف كل شيء عن مصفوفة الارتباك في التعلم الآلي.